- 针对课件中的例子自己实现k-means算法
- 调用R语言自带kmeans()对给定数据集表示的文档进行聚类。
- 给定数据集:
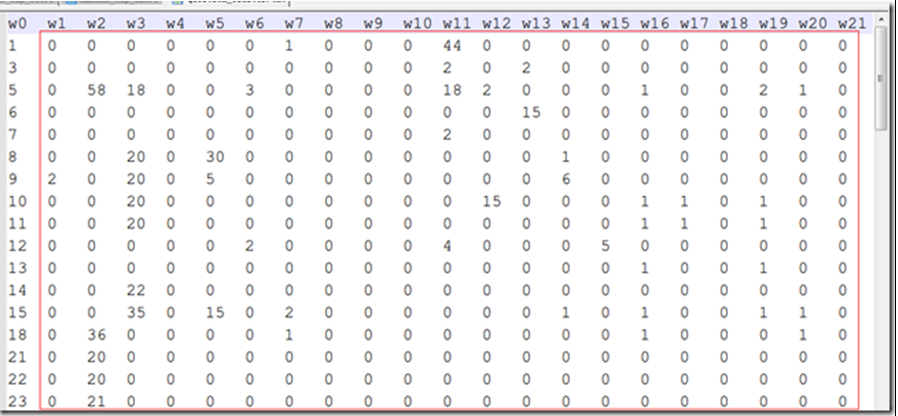
a) 数据代表的是文本信息。
b) 第一行代表词语,由于保密原因,词语已经被转意。第一列代表了文本的编号。
c) 红框中的数字为对应词的词频。
共113个样本,用K-Means算法将样本分为8类。
1、针对课件中的例子自己实现k-means算法
rm(list=ls()) #导入数据 id<-c(1:8) x<-c(1,2,1,2,4,5,4,5) y<-c(1,1,2,2,3,3,4,4) inputdata<-data.frame(id,x,y) #计算距离函数 cal_distance<-function(x1,y1,x2,y2){ dis=(x1-x2)*(x1-x2)+(y1-y2)*(y1-y2) dis=sqrt(dis) return(dis) } #假定随机选择的两个对象,如序号1和序号3当作初始点 center1=matrix(c(inputdata[1,2],inputdata[1,3])) center2=matrix(c(inputdata[3,2],inputdata[3,3])) #一开始两个簇都是空的 cu1<-c() cu2<-c() for(time in 1:5) { #遍历每一个点 for(i in 1:length(inputdata$id)) { distance1=cal_distance(inputdata$x[i],inputdata$y[i],center1[1],center1[2]) distance2=cal_distance(inputdata$x[i],inputdata$y[i],center2[1],center2[2]) if(distance1<=distance2) { cu1<-c(cu1,i) } else { cu2<-c(cu2,i) } } #更新簇1的质心 sx=0 sy=0 for(i in 1:length(cu1)) { sx=sx+inputdata$x[cu1[i]] sy=sy+inputdata$y[cu1[i]] } center1[1]=sx*1.0/length(cu1) center1[2]=sy*1.0/length(cu1) #更新簇2的质心 sx=0 sy=0 for(i in 1:length(cu2)) { sx=sx+inputdata$x[cu2[i]] sy=sy+inputdata$y[cu2[i]] } if(center2[1]==sx*1.0/length(cu2)&¢er2[2]==sy*1.0/length(cu2)) { break } center2[1]=sx*1.0/length(cu2) center2[2]=sy*1.0/length(cu2) cu1<-c() cu2<-c() } cat("簇1质心: ",center1[1]," ",center1[2]) print("簇1包含的元素有: ") for(i in 1:length(cu1)) { print(cu1[i]) } print("") cat("簇2质心: ",center2[1]," ",center2[2]) print("") print("簇1包含的元素有: ") for(i in 1:length(cu2)) { print(cu2[i]) }

2、 调用R语言自带kmeans()对给定数据集表示的文档进行聚类。
rm(list=ls()) setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验5-聚类分析") data = read.table("data_cluster.txt") kc <- kmeans(data, 8) #分类模型训练 print(kc) #fitted(kc) #查看具体分类情况 #table(data$Species, data$cluster)#查看分类概括