
查看运行结果:
#查看已安装的包,查看已载入的包,查看包的介绍
########例题3.1
#向量的输入方法
w<-c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
plot(w)#概况,数据的可视化可以让我们看的更轻松
summary(w)
#求均值
w.mean<-mean(w); w.mean
w[2]#选取特定位置的数字
#控制异常值,trim表示去掉异常值的比例
w[1]<-750#改变向量w的第一个元素的值
w.mean<-mean(w,trim=0.1); w.mean
#缺失值的处理,忽略缺失值
w[16]<-NA
w.mean<-mean(w,na.rm=TRUE); w.mean
#给出顺序统计量
sort(w)
sort(w,decreasing=T)
#分位数
quantile(w,probs=seq(0,1,0.2),na.rm=TRUE)
#寻求在线帮助的方法,
help('quantile')
?quantile
#方便起见,编写一个统一的函数计算样本的各种描述统计量
data_outline <- function(x){
n <- length(x)
m <- mean(x)
v <- var(x)
s <- sd(x)
me <- median(x)
cv <- 100*s/m #变异系数
css <- sum((x-m)^2) #矫正平方和
uss <- sum(x^2) #未校正平方和
R <- max(x)-min(x)#极差
R1 <- quantile(x,3/4)-quantile(x,1/4)
sm <- s/sqrt(n)
g1 <- n/((n-1)*(n-2))*sum((x-m)^3)/s^3 #峰度
g2 <- ((n*(n+1))/((n-1)*(n-2)*(n-3))*sum((x-m)^4)/s^4
- (3*(n-1)^2)/((n-2)*(n-3))) #偏度
data.frame(N=n, Mean=m, Var=v, std_dev=s, Median=me,
std_mean=sm, CV=cv, CSS=css, USS=uss, R=R,
R1=R1, Skewness=g1, Kurtosis=g2, row.names=1)#输出一个数据框data.frame
}
data_outline(w)#使用你所写的函数
#####………………实例分析
attach(mtcars)#获取数据集,把工作对象固定在mtcars上
mtcars#查看数据集
?mtcars#详细了解该数据集的信息
vars=c('mpg','hp','wt')#英里数,马力,车重
m=mtcars[vars];m#我们只选取vars中的三个变量
mode(m)#不能用刚才写的函数
mode(w)
#出来base包中的一些函数可以分析数据,还有其他的一些包可以使用,这里介绍Hmisc包,
#pasteses包,psych包
install.packages("Hmisc")
library(Hmisc)
describe(m)
describe
install.packages("pastecs")
library(pastecs)
stat.desc(m)
install.packages("psych")
library(psych)
describe(m)
detach(mtcars)推出该数据集的处理
##############################################################例题3.3
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
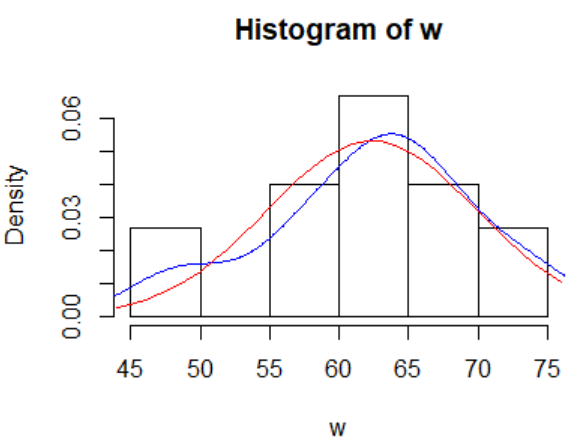
hist(w,freq=FALSE)#直方图,xlab="hgu",main="hist"
lines(density(w),col="blue")#lines() 该语句表示在已有图形上添加曲线
range(w)
x<-44:76
lines(x, dnorm(x, mean(w), sd(w)), col="red")#dnorm 表示正态分布的密度函数更多说明请看课件,
#算出每一个x对应的f(x)值,f为正态分布密度函数。
#课后思考练习:
#如何导入数据
#如何获取图片?
#实际例子中我们可能需要比较不同条件下的密度函数,如男性和女性
#sm包中的sm.density.compare()能提供帮助,见《R语言实战》p119

> w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
+ 66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
> hist(w,freq=FALSE)#直方图,xlab="hgu",main="hist"
> lines(density(w),col="blue")#lines() 该语句表示在已有图形上添加曲线
> range(w)
[1] 47.4 75.0
> x<-44:76
> lines(x, dnorm(x, mean(w), sd(w)), col="red")

做模拟的时候生成随机数:
> rnorm(10,1,4) #生成10个均值为1,标准差为4的正态分布的随机数
[1] -0.3721022 -4.6810248 -2.7463328 1.5920591 -7.5328322 2.1772208 5.1561548
[8] 1.2342389 -2.9472454 1.1590652

####################################################例题3.4
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
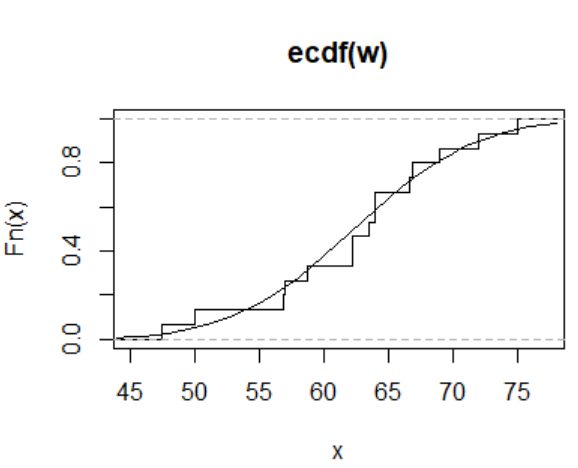
plot(ecdf(w),verticals = TRUE, do.p = FALSE)
x<-44:78
lines(x, pnorm(x, mean(w), sd(w)))#pnorm() 表示正态分布分布函数


##########################################################例题3.5
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
qqnorm(w); qqline(w)#用分号隔离两句代码。图的标题,坐标轴名称修改也是可以操作的
#########################################################正态性检验
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
shapiro.test(w) #正太分布的假设检验

> shapiro.test(w) #正太分布的假设检验
Shapiro-Wilk normality test
data: w
W = 0.96862, p-value = 0.8371



#############################################3.11箱线图
y<-c(1600, 1610, 1650, 1680, 1700, 1700, 1780, 1500, 1640,
1400, 1700, 1750, 1640, 1550, 1600, 1620, 1640, 1600,
1740, 1800, 1510, 1520, 1530, 1570, 1640, 1600)
f<-factor(c(rep(1,7),rep(2,5), rep(3,8), rep(4,6)))
plot(f,y)

#箱线图
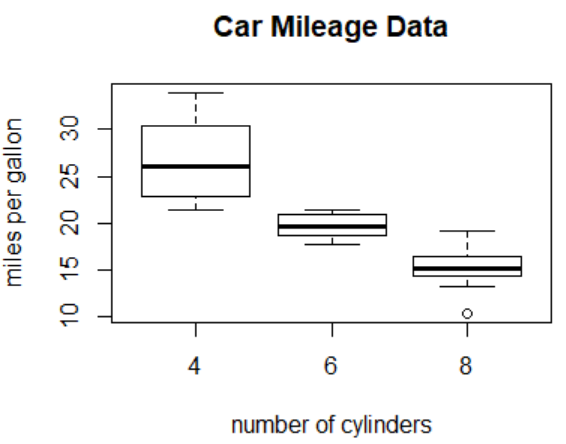
attach(mtcars)#motor trend杂志车辆路实数据集
boxplot(mpg~cyl,main="Car Mileage Data",xlab="number of cylinders",ylab="miles per gallon")
detach(mtcars)
> mtcars
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Cadillac Fleetwood 10.4 8 472.0 205 2.93 5.250 17.98 0 0 3 4
Lincoln Continental 10.4 8 460.0 215 3.00 5.424 17.82 0 0 3 4
Chrysler Imperial 14.7 8 440.0 230 3.23 5.345 17.42 0 0 3 4
Fiat 128 32.4 4 78.7 66 4.08 2.200 19.47 1 1 4 1
Honda Civic 30.4 4 75.7 52 4.93 1.615 18.52 1 1 4 2
Toyota Corolla 33.9 4 71.1 65 4.22 1.835 19.90 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Dodge Challenger 15.5 8 318.0 150 2.76 3.520 16.87 0 0 3 2
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Camaro Z28 13.3 8 350.0 245 3.73 3.840 15.41 0 0 3 4
Pontiac Firebird 19.2 8 400.0 175 3.08 3.845 17.05 0 0 3 2
Fiat X1-9 27.3 4 79.0 66 4.08 1.935 18.90 1 1 4 1
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Lotus Europa 30.4 4 95.1 113 3.77 1.513 16.90 1 1 5 2
Ford Pantera L 15.8 8 351.0 264 4.22 3.170 14.50 0 1 5 4
Ferrari Dino 19.7 6 145.0 175 3.62 2.770 15.50 0 1 5 6
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2
##############绘图补充
df<-data.frame(
Age=c(13, 13, 14, 12, 12, 15, 11, 15, 14, 14, 14, 15,
12, 13, 12, 16, 12, 11, 15 ),
Height=c(56.5, 65.3, 64.3, 56.3, 59.8, 66.5, 51.3,
62.5, 62.8, 69.0, 63.5, 67.0, 57.3, 62.5,
59.0, 72.0, 64.8, 57.5, 66.5),
Weight=c( 84.0, 98.0, 90.0, 77.0, 84.5, 112.0,
50.5, 112.5, 102.5, 112.5, 102.5, 133.0,
83.0, 84.0, 99.5, 150.0, 128.0, 85.0,
112.0)
);
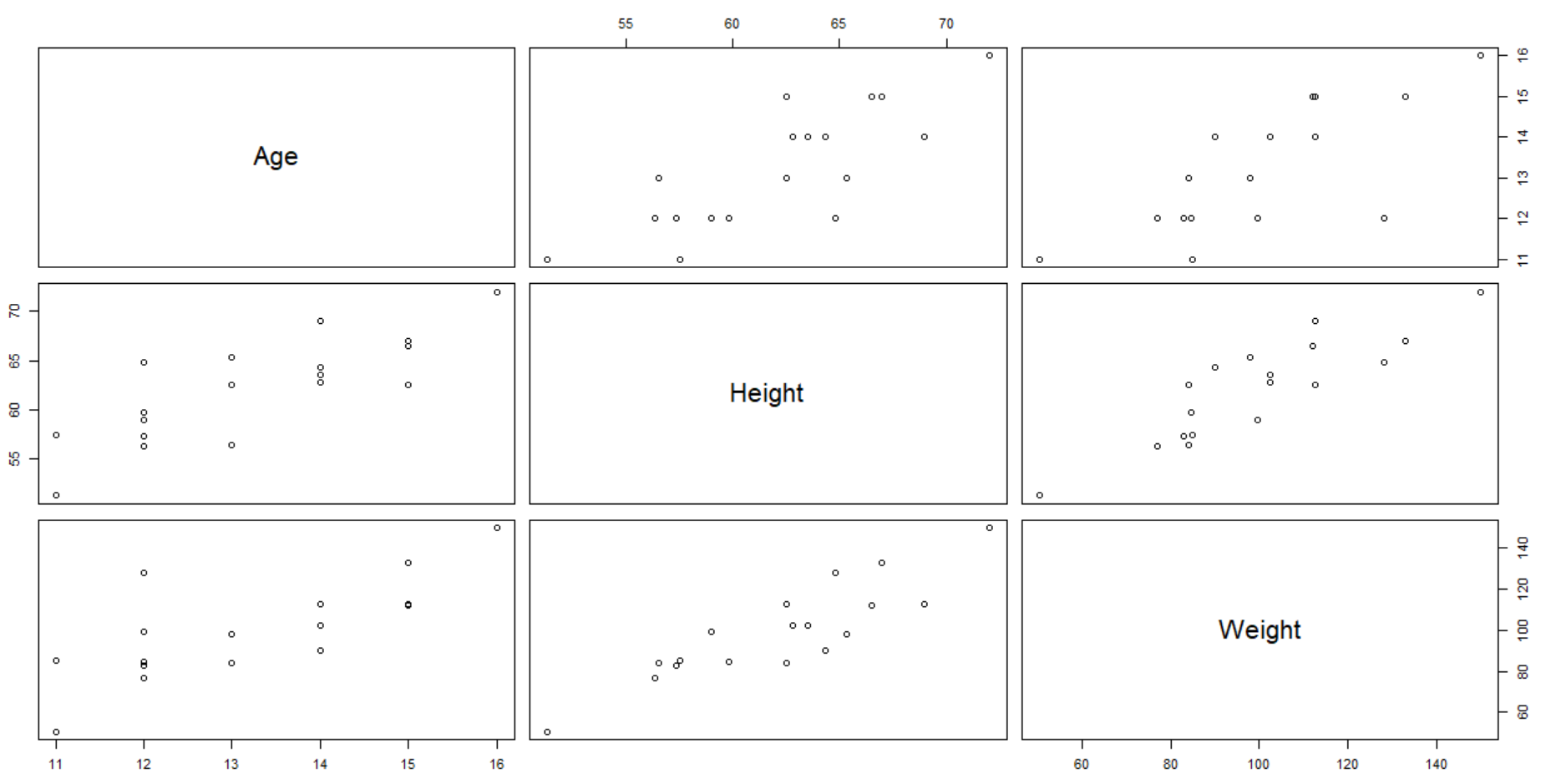
plot(df)
attach(df)
plot(~Age+Height)#attach(df)缺失的话,此处无法绘图.或者:plot(~Age+Height,data=df);
#或plot(~df$Age+df$Height)
plot(Weight~Age+Height)
pairs(df)#所有变量之间的关系
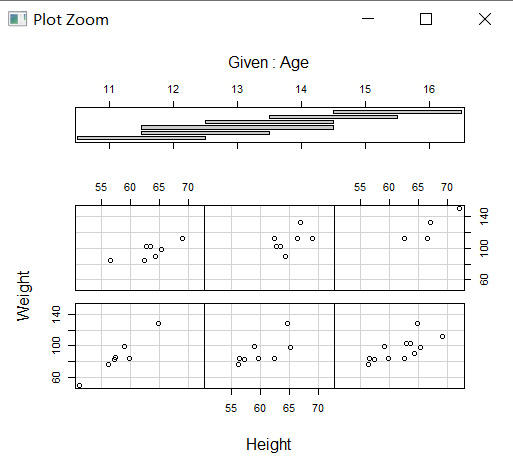
coplot(Weight ~ Height | Age)#在分组比较时特别重要
detach(df)
#散点图矩阵,在做多元回归分析的时候需要用到
pairs(~mpg+disp+drat+wt,data=mtcars,main='basic scatterplot matrix')
#install.packages("car")
library(car)
scatterplotMatrix(~mpg+disp+drat+wt,data=mtcars,lty.smooth=2,main='basic scatterplot matrix via car package')

#关于更多图形的操作查阅《R语言实战》第三章内容。
############excel数据导入说明
install.packages("xlsx")
library(xlsx)
my.data=read.xlsx2(file="C:\Users\HWT\Desktop\test.xlsx",sheetIndex=1)#注意这里斜线的方向
#最后说明:在自己编写函数的时候。R语言中的重复和循环语句for/while,条件执行语句if-else/ifelse/switch和c和matlab一致
所有代码:


#查看已安装的包,查看已载入的包,查看包的介绍
########例题3.1
#向量的输入方法
w<-c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
plot(w)#概况,数据的可视化可以让我们看的更轻松
summary(w)
#求均值
w.mean<-mean(w); w.mean
w[2]#选取特定位置的数字
#控制异常值,trim表示去掉异常值的比例
w[1]<-750#改变向量w的第一个元素的值
w.mean<-mean(w,trim=0.1); w.mean
#缺失值的处理,忽略缺失值
w[16]<-NA
w.mean<-mean(w,na.rm=TRUE); w.mean
#给出顺序统计量
sort(w)
sort(w,decreasing=T)
#分位数
quantile(w,probs=seq(0,1,0.2),na.rm=TRUE)
#寻求在线帮助的方法,
help('quantile')
?quantile
#方便起见,编写一个统一的函数计算样本的各种描述统计量
data_outline <- function(x){
n <- length(x)
m <- mean(x)
v <- var(x)
s <- sd(x)
me <- median(x)
cv <- 100*s/m #变异系数
css <- sum((x-m)^2) #矫正平方和
uss <- sum(x^2) #未校正平方和
R <- max(x)-min(x)#极差
R1 <- quantile(x,3/4)-quantile(x,1/4)
sm <- s/sqrt(n)
g1 <- n/((n-1)*(n-2))*sum((x-m)^3)/s^3 #峰度
g2 <- ((n*(n+1))/((n-1)*(n-2)*(n-3))*sum((x-m)^4)/s^4
- (3*(n-1)^2)/((n-2)*(n-3))) #偏度
data.frame(N=n, Mean=m, Var=v, std_dev=s, Median=me,
std_mean=sm, CV=cv, CSS=css, USS=uss, R=R,
R1=R1, Skewness=g1, Kurtosis=g2, row.names=1)#输出一个数据框data.frame
}
data_outline(w)#使用你所写的函数
#####………………实例分析
attach(mtcars)#获取数据集,把工作对象固定在mtcars上
mtcars#查看数据集
?mtcars#详细了解该数据集的信息
vars=c('mpg','hp','wt')#英里数,马力,车重
m=mtcars[vars];m#我们只选取vars中的三个变量
mode(m)#不能用刚才写的函数
mode(w)
#出来base包中的一些函数可以分析数据,还有其他的一些包可以使用,这里介绍Hmisc包,
#pasteses包,psych包
install.packages("Hmisc")
library(Hmisc)
describe(m)
describe
install.packages("pastecs")
library(pastecs)
stat.desc(m)
install.packages("psych")
library(psych)
describe(m)
detach(mtcars)#推出该数据集的处理
##############################################################例题3.3
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
hist(w,freq=FALSE)#直方图,xlab="hgu",main="hist"
lines(density(w),col="blue")#lines() 该语句表示在已有图形上添加曲线
range(w)
x<-44:76
lines(x, dnorm(x, mean(w), sd(w)), col="red")#dnorm 表示正态分布的密度函数更多说明请看课件,
#算出每一个x对应的f(x)值,f为正态分布密度函数。
#课后思考练习:
#如何导入数据
#如何获取图片?
#实际例子中我们可能需要比较不同条件下的密度函数,如男性和女性
#sm包中的sm.density.compare()能提供帮助,见《R语言实战》p119
####################################################例题3.4
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
plot(ecdf(w),verticals = TRUE, do.p = FALSE)
x<-44:78
lines(x, pnorm(x, mean(w), sd(w)))#pnorm() 表示正态分布分布函数
##########################################################例题3.5
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
qqnorm(w); qqline(w)#用分号隔离两句代码。图的标题,坐标轴名称修改也是可以操作的
#########################################################正态性检验
w <- c(75.0, 64.0, 47.4, 66.9, 62.2, 62.2, 58.7, 63.5,
66.6, 64.0, 57.0, 69.0, 56.9, 50.0, 72.0)
shapiro.test(w)
#############################################3.11箱线图
y<-c(1600, 1610, 1650, 1680, 1700, 1700, 1780, 1500, 1640,
1400, 1700, 1750, 1640, 1550, 1600, 1620, 1640, 1600,
1740, 1800, 1510, 1520, 1530, 1570, 1640, 1600)
f<-factor(c(rep(1,7),rep(2,5), rep(3,8), rep(4,6)))
plot(f,y)
#箱线图
attach(mtcars)#motor trend杂志车辆路实数据集
boxplot(mpg~cyl,main="Car Mileage Data",xlab="number of cylinders",ylab="miles per gallon")
detach(mtcars)
##############绘图补充
df<-data.frame(
Age=c(13, 13, 14, 12, 12, 15, 11, 15, 14, 14, 14, 15,
12, 13, 12, 16, 12, 11, 15 ),
Height=c(56.5, 65.3, 64.3, 56.3, 59.8, 66.5, 51.3,
62.5, 62.8, 69.0, 63.5, 67.0, 57.3, 62.5,
59.0, 72.0, 64.8, 57.5, 66.5),
Weight=c( 84.0, 98.0, 90.0, 77.0, 84.5, 112.0,
50.5, 112.5, 102.5, 112.5, 102.5, 133.0,
83.0, 84.0, 99.5, 150.0, 128.0, 85.0,
112.0)
);
plot(df)
attach(df)
plot(~Age+Height)#attach(df)缺失的话,此处无法绘图.或者:plot(~Age+Height,data=df);
#或plot(~df$Age+df$Height)
plot(Weight~Age+Height)
pairs(df)#所有变量之间的关系
coplot(Weight ~ Height | Age)#在分组比较时特别重要
detach(df)
#散点图矩阵,在做多元回归分析的时候需要用到
pairs(~mpg+disp+drat+wt,data=mtcars,main='basic scatterplot matrix')
install.packages("car")
library(car)
scatterplotMatrix(~mpg+disp+drat+wt,data=mtcars,lty.smooth=2,main='basic scatterplot matrix via car package')
#关于更多图形的操作查阅《R语言实战》第三章内容。
############excel数据导入说明
install.packages("xlsx")
library(xlsx)
my.data=read.xlsx2(file="C:\Users\HWT\Desktop\test.xlsx",sheetIndex=1)#注意这里斜线的方向
#最后说明:在自己编写函数的时候。R语言中的重复和循环语句for/while,条件执行语句if-else/ifelse/switch和c和matlab一致View Code