流程:
1.文本和摘要全部输入到模型中。
2.训练时,对生成摘要取前C个词,从头开始取,如果生成的摘要不足C,那么不足的地方直接补<s>。
3.训练时,最大化生成的摘要与原摘要的概率,即每个生成的词与原摘要的词进行对比,用损失函数计算梯度,然后下降。
4.预测时,已经具有了权重的模型,会逐词生成N个词的摘要。
5.注意力:已生成的摘要的前C个词,求出一个注意力权重,然后再成乘以全部文本经过平滑以后的。
6.这里生成词,不是只生成一个,而是生成K个集合。,采用beam search算法来寻找目标单词。
a.这样生成的词不是只有一个,而是生成了K个备选集。
b.第一个词的时候,按照权重生成第一个词,K种可能不是一个词,而是生成K中可能,要逐渐迭代迭代生成词的词数循环。
例如:第一个词生成了K种可能。第二次与第一次生成的词要组成K种可能,原来是K2可能,选出K种概率最大的可能的组合。
Encoder:
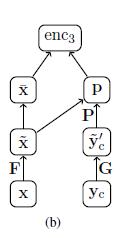
x:整个输入文本
yc:生成的摘要前C个词
y'c:前C个词,经过卷积后的向量
p:soft alighment因子
F:词嵌入矩阵,这里使用的是BOW
G:词嵌入矩阵
P:软对其因子学习矩阵
Decoder:
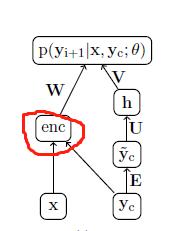
U、W、V:权重矩阵
E:词嵌入矩阵,BOW(这里前C个已生成摘要的词,不需要卷积)
Decoder:会生成K个最大词的概率,然后用beam search去选
总体流程:
encoder->decoder->beam search