背景
Elasticsearch 是一个实时的分布式搜索与分析引擎,被广泛用来做全文搜索、结构化搜索、分析。在使用过程中,有一些典型的使用场景,比如分页、遍历等。在使用关系型数据库中,我们被告知要注意甚至被明确禁止使用深度分页,同理,在 Elasticsearch 中,也应该尽量避免使用深度分页。这篇文章主要介绍 Elasticsearch 中使用分页的方式、Elasticsearch 搜索执行过程以及为什么深度分页应该被禁止,最后再介绍使用 scroll 的方式遍历数据。
Elasticsearch 搜索内部执行原理
一个最基本的 Elasticsearch 查询语句是这样的:
POST /my_index/my_type/_search
{
"query": { "match_all": {}},
"from": 100,
"size": 10
}
上面的查询表示从搜索结果中取第100条开始的10条数据。下面讲解搜索过程时也以这个请求为例。
那么,这个查询语句在 Elasticsearch 集群内部是怎么执行的呢?为了方便描述,我们假设该 index 只有primary shards,没有 replica shards。
在 Elasticsearch 中,搜索一般包括两个阶段,query 和 fetch 阶段,可以简单的理解,query 阶段确定要取哪些doc,fetch 阶段取出具体的 doc。
Query 阶段

如上图所示,描述了一次搜索请求的 query 阶段。
- Client 发送一次搜索请求,node1 接收到请求,然后,node1 创建一个大小为 from + size 的优先级队列用来存结果,我们管 node1 叫 coordinating node。
- coordinating node将请求广播到涉及到的 shards,每个 shard 在内部执行搜索请求,然后,将结果存到内部的大小同样为 from + size 的优先级队列里,可以把优先级队列理解为一个包含 top N 结果的列表。
- 每个 shard 把暂存在自身优先级队列里的数据返回给 coordinating node,coordinating node 拿到各个 shards 返回的结果后对结果进行一次合并,产生一个全局的优先级队列,存到自身的优先级队列里。
在上面的例子中,coordinating node 拿到 (from + size) * 6 条数据,然后合并并排序后选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。另外,各个分片返回给 coordinating node 的数据用于选出前 from + size 条数据,所以,只需要返回唯一标记 doc 的 _id 以及用于排序的 _score 即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
Fetch 阶段
query 阶段知道了要取哪些数据,但是并没有取具体的数据,这就是 fetch 阶段要做的。

上图展示了 fetch 过程:
- coordinating node 发送 GET 请求到相关shards。
- shard 根据 doc 的 _id 取到数据详情,然后返回给 coordinating node。
- coordinating node 返回数据给 Client。
coordinating node 的优先级队列里有 from + size 个 _doc _id,但是,在 fetch 阶段,并不需要取回所有数据,在上面的例子中,前100条数据是不需要取的,只需要取优先级队列里的第101到110条数据即可。
需要取的数据可能在不同分片,也可能在同一分片,coordinating node 使用 multi-get 来避免多次去同一分片取数据,从而提高性能。
深度分页的问题
Elasticsearch 的这种方式提供了分页的功能,同时,也有相应的限制。举个例子,一个索引,有10亿数据,分10个 shards,然后,一个搜索请求,from=1,000,000,size=100,这时候,会带来严重的性能问题:
- CPU
- 内存
- IO
- 网络带宽
CPU、内存和IO消耗容易理解,网络带宽问题稍难理解一点。在 query 阶段,每个shards需要返回 1,000,100 条数据给 coordinating node,而 coordinating node 需要接收 10 * 1,000,100 条数据,即使每条数据只有 _doc _id 和 _score,这数据量也很大了,而且,这才一个查询请求,那如果再乘以100呢?
在另一方面,我们意识到,这种深度分页的请求并不合理,因为我们是很少人为的看很后面的请求的,在很多的业务场景中,都直接限制分页,比如只能看前100页。
不过,这种深度分页确实存在,比如,被爬虫了,这个时候,直接干掉深度分页就好;又或者,业务上有遍历数据的需要,比如,有1千万粉丝的微信大V,要给所有粉丝群发消息,或者给某省粉丝群发,这时候就需要取得所有符合条件的粉丝,而最容易想到的就是利用 from + size 来实现,不过,这个是不现实的,这时,可以采用 Elasticsearch 提供的 scroll 方式来实现遍历。
利用 scroll 遍历数据
可以把 scroll 理解为关系型数据库里的 cursor,因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
可以把 scroll 分为初始化和遍历两步,初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,在遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。
使用介绍
下面介绍下scroll的使用,可以通过 Elasticsearch 的 HTTP 接口做试验下,包括初始化和遍历两个部分。
初始化
POST ip:port/my_index/my_type/_search?scroll=1m
{
"query": { "match_all": {}}
}
初始化时需要像普通 search 一样,指明 index 和 type (当然,search 是可以不指明 index 和 type 的),然后,加上参数 scroll,表示暂存搜索结果的时间,其它就像一个普通的search请求一样。
初始化返回一个 _scroll_id,_scroll_id 用来下次取数据用。
遍历
POST /_search?scroll=1m
{
"scroll_id":"XXXXXXXXXXXXXXXXXXXXXXX I am scroll id XXXXXXXXXXXXXXX"
}
这里的 scroll_id 即 上一次遍历取回的 _scroll_id 或者是初始化返回的 _scroll_id,同样的,需要带 scroll 参数。 重复这一步骤,直到返回的数据为空,即遍历完成。注意,每次都要传参数 scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。
设置scroll的时候,需要使搜索结果缓存到下一次遍历完成,同时,也不能太长,毕竟空间有限。
Scroll-Scan
Elasticsearch 提供了 Scroll-Scan 方式进一步提高遍历性能。还是上面的例子,微信大V要给粉丝群发这种后台任务,是不需要关注顺序的,只要能遍历所有数据即可,这时候,就可以用Scroll-Scan。
Scroll-Scan 的遍历与普通 Scroll 一样,初始化存在一点差别。
POST ip:port/my_index/my_type/_search?search_type=scan&scroll=1m&size=50
{
"query": { "match_all": {}}
}
需要指明参数:
- search_type。赋值为scan,表示采用 Scroll-Scan 的方式遍历,同时告诉 Elasticsearch 搜索结果不需要排序。
- scroll。同上,传时间。
- size。与普通的 size 不同,这个 size 表示的是每个 shard 返回的 size 数,最终结果最大为 number_of_shards * size。
Scroll-Scan 方式与普通 scroll 有几点不同:
- Scroll-Scan 结果没有排序,按 index 顺序返回,没有排序,可以提高取数据性能。
- 初始化时只返回 _scroll_id,没有具体的 hits 结果。
- size 控制的是每个分片的返回的数据量而不是整个请求返回的数据量。
Java 实现
用 Java 举个例子。
初始化
try {
response = esClient.prepareSearch(index)
.setTypes(type)
.setSearchType(SearchType.SCAN)
.setQuery(query)
.setScroll(new TimeValue(timeout))
.setSize(size)
.execute()
.actionGet();
} catch (ElasticsearchException e) {
// handle Exception
}
初始化返回 _scroll_id,然后,用 _scroll_id 去遍历,注意,上面的query是一个JSONObject,不过这里很多种实现方式,我这儿只是个例子。
遍历
try {
response = esClient.prepareSearchScroll(scrollId)
.setScroll(new TimeValue(timeout))
.execute()
.actionGet();
} catch (ElasticsearchException e) {
// handle Exception
}
总结
- 深度分页不管是关系型数据库还是Elasticsearch还是其他搜索引擎,都会带来巨大性能开销,特别是在分布式情况下。
- 有些问题可以考业务解决而不是靠技术解决,比如很多业务都对页码有限制,google 搜索,往后翻到一定页码就不行了。
- Elasticsearch 提供的 Scroll 接口专门用来获取大量数据甚至全部数据,在顺序无关情况下,首推Scroll-Scan。
- 描述搜索过程时,为了简化描述,假设 index 没有备份,实际上,index 肯定会有备份,这时候,就涉及到选择 shard。
1. from+size 实现分页
from表示从第几行开始,size表示查询多少条文档。from默认为0,size默认为10,
注意:size的大小不能超过index.max_result_window这个参数的设置,默认为10,000。
如果搜索size大于10000,需要设置index.max_result_window参数
PUT _settings
{
"index": {
"max_result_window": "10000000"
}
}
内部执行原理:
示例:有三个节点node1、node2、node3,每个节点上有2个shard分片
| node1 | node2 | node3 |
|---|---|---|
| shard1 | shard3 | shard5 |
| shard2 | shard4 | shard6 |
1.client发送分页查询请求到node1(coordinating node)上,node1建立一个大小为from+size的优先级队列来存放查询结果;
2.node1将请求广播到涉及到的shards上;
3.每个shards在内部执行查询,把from+size条记录存到内部的优先级队列(top N表)中;
4.每个shards把缓存的from+size条记录返回给node1;
5.node1获取到各个shards数据后,进行合并并排序,选择前面的 from + size 条数据存到优先级队列,以便 fetch 阶段使用。
各个分片返回给 coordinating node 的数据用于选出前 from + size 条数据,所以,只需要返回唯一标记 doc 的 _id 以及用于排序的 _score 即可,这样也可以保证返回的数据量足够小。
coordinating node 计算好自己的优先级队列后,query 阶段结束,进入 fetch 阶段。
from+size在深度分页时,会带来严重的性能问题:
CPU、内存、IO、网络带宽
数据量越大,越往后翻页,性能越低
2.scroll
可以把 scroll 理解为关系型数据库里的 cursor,因此,scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
可以把 scroll 分为初始化和遍历两步,
初始化时将所有符合搜索条件的搜索结果缓存起来,可以想象成快照,
遍历时,从这个快照里取数据,也就是说,在初始化后对索引插入、删除、更新数据都不会影响遍历结果。
1.初始化:
POST http://192.168.18.230:9200/bill/bill/_search?scroll=3m
{
"query": { "match_all": {}},
"size": 10
}
参数 scroll,表示暂存搜索结果的时间
返回一个 _scroll_id,_scroll_id 用来下次取数据用
2.遍历:
POST http://192.168.18.230:9200/_search?scroll=3m
{
"scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAHRCFi1BLWIzSHdhUkl1cC1rcjBueVhJZUEAAAAAAAB0QRYtQS1iM0h3YVJJdXAta3IwbnlYSWVBAAAAAAAAdEQWLUEtYjNId2FSSXVwLWtyMG55WEllQQAAAAAAAHRDFi1BLWIzSHdhUkl1cC1rcjBueVhJZUEAAAAAAAB0RRYtQS1iM0h3YVJJdXAta3IwbnlYSWVB"
}
这里的 scroll_id 即 上一次遍历取回的 _scroll_id 或者是初始化返回的 _scroll_id,同样的,需要带 scroll 参数。
注意,每次都要传参数 scroll,刷新搜索结果的缓存时间。另外,不需要指定 index 和 type。
3.search_after
官网上的说明:
The Scroll api is recommended for efficient deep scrolling but scroll contexts are costly and it is not recommended to use it for real time user requests.
The search_after parameter circumvents this problem by providing a live cursor. The idea is to use the results from the previous page to help the retrieval of the next page.
Scroll 被推荐用于深度查询,但是contexts的代价是昂贵的,不推荐用于实时用户请求,而更适用于后台批处理任务,比如群发。
search_after 提供了一个实时的光标来避免深度分页的问题,其思想是使用前一页的结果来帮助检索下一页。
search_after 需要使用一个唯一值的字段作为排序字段,否则不能使用search_after方法
推荐使用_uid 作为唯一值的排序字段
GET twitter/tweet/_search
{
"size": 10,
"query": { "match_all": {}},
"sort": [
{"date": "asc"},
{"_uid": "desc"}
]
}
每一条返回记录中会有一组 sort values ,查询下一页时,在search_after参数中指定上一页返回的 sort values
GET twitter/tweet/_search
{
"size": 10,
"query": { "match_all": {}},
"search_after": [1463538857, "tweet#654323"],
"sort": [
{"date": "asc"},
{"_uid": "desc"}
]
}
注意:search_after不能自由跳到一个随机页面,只能按照 sort values 跳转到下一页
4.总结
- 深度分页不管是关系型数据库还是Elasticsearch还是其他搜索引擎,都会带来巨大性能开销,特别是在分布式情况下。
- 有些问题可以考业务解决而不是靠技术解决,比如很多业务都对页码有限制,google 搜索,往后翻到一定页码就不行了。
- scroll 并不适合用来做实时搜索,而更适用于后台批处理任务,比如群发。
- search_after不能自由跳到一个随机页面,只能按照 sort values 跳转到下一页。
按照一般的查询流程来说,如果我想查询前10条数据:
1 客户端请求发给某个节点 2 节点转发给个个分片,查询每个分片上的前10条 3 结果返回给节点,整合数据,提取前10条 4 返回给请求客户端
我这里总的数据有33万多,分别以每页5000,10000,50000的数据量请求,得到如下的执行时间:
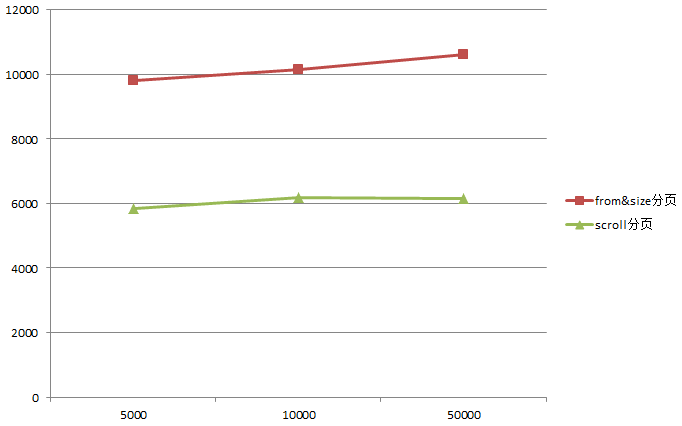
可以看到仅仅30万,就相差接近一倍的性能,更何况是如今的大数据环境...因此,如果想要对全量数据进行操作,快换掉fromsize,使用scroll吧!
那么当我想要查询第10条到第20条的数据该怎么办呢?这个时候就用到分页查询了。
from-size"浅"分页
"浅"分页的概念是小博主自己定义的,可以理解为简单意义上的分页。它的原理很简单,就是查询前20条数据,然后截断前10条,只返回10-20的数据。这样其实白白浪费了前10条的查询。
查询的方法如:
{
"from" : 0, "size" : 10,
"query" : {
"term" : { "user" : "kimchy" }
}
}其中,from定义了目标数据的偏移值,size定义当前返回的事件数目。
默认from为0,size为10,即所有的查询默认仅仅返回前10条数据。
做过测试,越往后的分页,执行的效率越低。
通过下图可以看出,刨去一些异常的数据,总体上还是会随着from的增加,消耗时间也会增加。而且数据量越大,效果越明显!
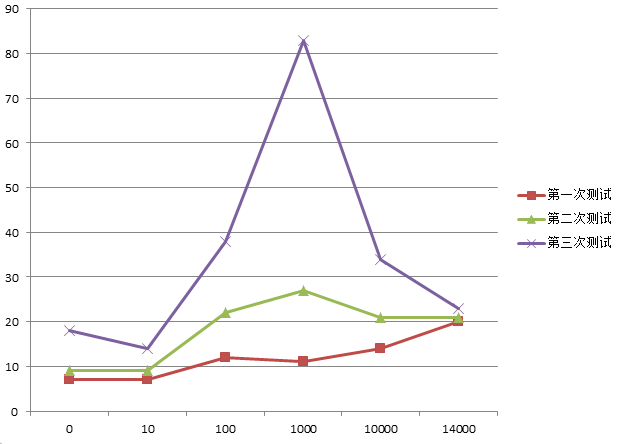
也就是说,分页的偏移值越大,执行分页查询时间就会越长!
scroll“深”分页
相对于from和size的分页来说,使用scroll可以模拟一个传统数据的游标,记录当前读取的文档信息位置。这个分页的用法,不是为了实时查询数据,而是为了一次性查询大量的数据(甚至是全部的数据)。
因为这个scroll相当于维护了一份当前索引段的快照信息,这个快照信息是你执行这个scroll查询时的快照。在这个查询后的任何新索引进来的数据,都不会在这个快照中查询到。但是它相对于from和size,不是查询所有数据然后剔除不要的部分,而是记录一个读取的位置,保证下一次快速继续读取。
API使用方法如:
curl -XGET 'localhost:9200/twitter/tweet/_search?scroll=1m' -d '
{
"query": {
"match" : {
"title" : "elasticsearch"
}
}
}
'会自动返回一个_scroll_id,通过这个id可以继续查询(实际上这个ID会很长哦!):
curl -XGET 'localhost:9200/_search/scroll?scroll=1m&scroll_id=c2Nhbjs2OzM0NDg1ODpzRlBLc0FXNlNyNm5JWUc1'注意,我在使用1.4版本的ES时,只支持把参数放在URL路径里面,不支持在JSON body中使用。
有个很有意思的事情,细心的会发现,这个ID其实是通过base64编码的:
cXVlcnlUaGVuRmV0Y2g7MTY7MjI3NTp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyNzQ6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjgwOnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI4MTp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyODM6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjgyOnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI4Njp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyODc6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjg5OnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI4NDp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyODU6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjg4OnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI3Njp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzIyNzc6dnRYS0o4bG5RSW1kaXdjRHRQVC1rQTsyMjc4OnZ0WEtKOGxuUUltZGl3Y0R0UFQta0E7MjI3OTp2dFhLSjhsblFJbWRpd2NEdFBULWtBOzA7如果使用解码工具可以看到:
queryThenFetch;16;2275:vtXKJ8lnQImdiwcDtPT-kA;2274:vtXKJ8lnQImdiwcDtPT-kA;2280:vtXKJ8lnQImdiwcDtPT-kA;2281:vtXKJ8lnQImdiwcDtPT-kA;2283:vtXKJ8lnQImdiwcDtPT-kA;2282:vtXKJ8lnQImdiwcDtPT-kA;2286:vtXKJ8lnQImdiwcDtPT-kA;2287:vtXKJ8lnQImdiwcDtPT-kA;2289:vtXKJ8lnQImdiwcDtPT-kA;2284:vtXKJ8lnQImdiwcDtPT-kA;2285:vtXKJ8lnQImdiwcDtPT-kA;2288:vtXKJ8lnQImdiwcDtPT-kA;2276:vtXKJ8lnQImdiwcDtPT-kA;2277:vtXKJ8lnQImdiwcDtPT-kA;2278:vtXKJ8lnQImdiwcDtPT-kA;2279:vtXKJ8lnQImdiwcDtPT-kA;0;虽然搞不清楚里面是什么内容,但是看到了一堆规则的键值对,总是让人兴奋一下!
测试from&size VS scroll的性能
首先呢,需要在java中引入elasticsearch-jar,比如使用maven:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>1.4.4</version>
</dependency>然后初始化一个client对象:
private static TransportClient client;
private static String INDEX = "index_name";
private static String TYPE = "type_name";
public static TransportClient init(){
Settings settings = ImmutableSettings.settingsBuilder()
.put("client.transport.sniff", true)
.put("cluster.name", "cluster_name")
.build();
client = new TransportClient(settings).addTransportAddress(new InetSocketTransportAddress("localhost",9300));
return client;
}
public static void main(String[] args) {
TransportClient client = init();
//这样就可以使用client执行查询了
}然后就是创建两个查询过程了 ,下面是from-size分页的执行代码:
System.out.println("from size 模式启动!");
Date begin = new Date();
long count = client.prepareCount(INDEX).setTypes(TYPE).execute().actionGet().getCount();
SearchRequestBuilder requestBuilder = client.prepareSearch(INDEX).setTypes(TYPE).setQuery(QueryBuilders.matchAllQuery());
for(int i=0,sum=0; sum<count; i++){
SearchResponse response = requestBuilder.setFrom(i).setSize(50000).execute().actionGet();
sum += response.getHits().hits().length;
System.out.println("总量"+count+" 已经查到"+sum);
}
Date end = new Date();
System.out.println("耗时: "+(end.getTime()-begin.getTime()));下面是scroll分页的执行代码,注意啊!scroll里面的size是相对于每个分片来说的,所以实际返回的数量是:分片的数量*size
System.out.println("scroll 模式启动!");
begin = new Date();
SearchResponse scrollResponse = client.prepareSearch(INDEX)
.setSearchType(SearchType.SCAN).setSize(10000).setScroll(TimeValue.timeValueMinutes(1))
.execute().actionGet();
count = scrollResponse.getHits().getTotalHits();//第一次不返回数据
for(int i=0,sum=0; sum<count; i++){
scrollResponse = client.prepareSearchScroll(scrollResponse.getScrollId())
.setScroll(TimeValue.timeValueMinutes(8))
.execute().actionGet();
sum += scrollResponse.getHits().hits().length;
System.out.println("总量"+count+" 已经查到"+sum);
}
end = new Date();
System.out.println("耗时: "+(end.getTime()-begin.getTime()));参照:https://scsundefined.gitbooks.io/elasticsearch-reference-cn/content/s06/03_02_from__size.html
Elasticsearch 官方指南
英文原文:
https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
Gitbook:
https://www.gitbook.com/book/scsundefined/elasticsearch-reference-cn/details
Github: