1.英文词频统
下载一首英文的歌词或文章
news='''It was summer. A duck was sitting in her nest. Her little ducklings were about to hatched.
One egg after another began to crack,but the biggest one was still there. At last, it cracked.
The baby was big and ugly. The next day,the mother duck with her family went down to the moat.
One duckling jumped in after another. The big ugly one swam about with them.But the poor
duckling was chased and harassed by all the ducklings because he was very ugly.The ducks
bit him,the hens pecked him. And the girl who fed them kicked him aside.Then he ran off
and soon came to a great marsh where the wild ducks lived. He stayed there for two whole
days.A big dog appeared close beside him,but he did not touch the duckling. "Oh,I am so
ugly that even the dog won`t bite me." Sighed the duckling.In the evening,he reached a
little cottage. Because he could not lay eggs,he was driven away by the hen. one
evening,he saw some swans.He flew into the water and swam towards them. What did he
see in the clear water? He was no longer a dark grey ugly bird. He wa s himself a swan.
He said to himself,"I never dreamed that I could be so happy when I was the ugly duckling."'''
将所有,.?!’:等分隔符全部替换为空格
sep = '''.,?""''' for c in sep: news=news.replace(c,'')
将所有大写转换为小写
生成单词列表
wordList = news.lower().split() for w in wordList: print(w)
生成词频统计
wordDict = {} wordSet = set(wordList) for w in wordSet: wordDict[w] = wordList.count(w)
排序
dictList = list(wordDict.items()) dictList.sort(key = lambda x: x[1], reverse=True)
排除语法型词汇,代词、冠词、连词
exclude ={'the','who','a','it','that','he','by','when'}
wordSet = set(wordList)-exclude
for w in wordSet:
wordDict[w] = wordList.count(w)
输出词频最大TOP20
for i in range(20): print(dictList[i])
将分析对象存为utf-8编码的文件,通过文件读取的方式获得词频分析内容。
f = open('news.txt', 'r', encoding='utf-8') news = f.read() f.close() print(news) f = open('newscount.txt', 'a') for i in range(20): f.write(dictList[i][0] + '' + str(dictList[i][1]) + '\n') f.close()
2.中文词频统计
下载一长篇中文文章。
从文件读取待分析文本。
news = open('gzccnews.txt','r',encoding = 'utf-8')
安装与使用jieba进行中文分词。
pip install jieba
import jieba
list(jieba.lcut(news))
import jieba f = open('price.txt','r',encoding='utf-8') price= f.read() f.close()
生成词频统计
排序
排除语法型词汇,代词、冠词、连词
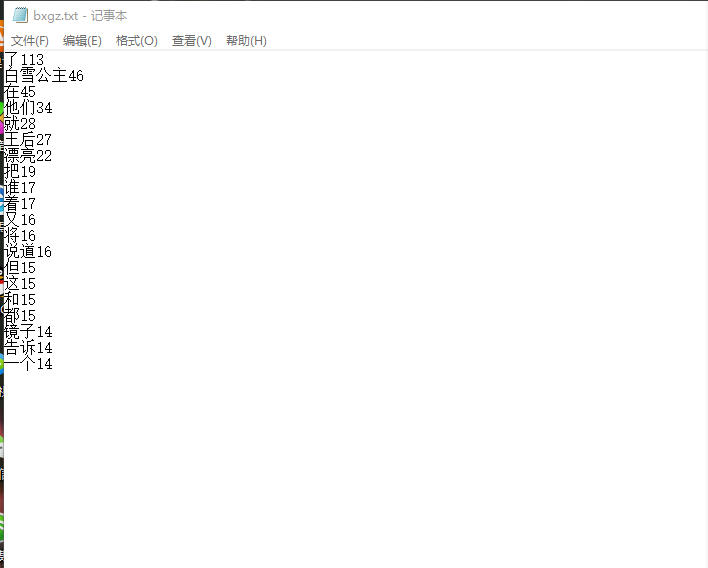
输出词频最大TOP20(或把结果存放到文件里)
将代码与运行结果截图发布在博客上。
can1 = '''“”,。?:()! ''' exclude = {'你','的','我','他','她','是'} jieba.add_word('白雪公主') for i in can1: price = price.replace(i,'') result = list(jieba.cut(price)) wordDict = {} words = list(set(result)-exclude) for i in words: wordDict[i]= result.count(i) wordList = list(wordDict.items()) wordList.sort(key = lambda x: x[1], reverse=True) print(wordList) f = open('bxgz.txt','a',encoding='utf-8') for i in range(20): f.write(wordList[i][0] + '' + str(wordList[i][1]) + '\n') f.close()