基于数据库
基于数据库(MySQL)的方案,一般分为3类:基于表记录、乐观锁和悲观锁
基于表记录
用表主键或表字段加唯一性索引便可实现,如下;
CREATE TABLE `database_lock` (
`id` BIGINT NOT NULL AUTO_INCREMENT,
`resource` int NOT NULL COMMENT '锁定的资源',
`description` varchar(1024) NOT NULL DEFAULT "" COMMENT '描述',
PRIMARY KEY (`id`),
UNIQUE KEY `uiq_idx_resource` (`resource`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='数据库分布式锁表';
想获得锁插入一条数据
INSERT INTO database_lock(resource, description) VALUES (1, 'lock');
解锁删除数据:
DELETE FROM database_lock WHERE resource=1;
这种实现方式非常的简单,但是需要注意以下几点:
- 这种锁没有失效时间,一旦释放锁的操作失败就会导致锁记录一直在数据库中,其它线程无法获得锁。这个缺陷也很好解决,比如可以做一个定时任务去定时清理。
- 这种锁的可靠性依赖于数据库。建议设置备库,避免单点,进一步提高可靠性。
- 这种锁是非阻塞的,因为插入数据失败之后会直接报错,想要获得锁就需要再次操作。如果需要阻塞式的,可以弄个for循环、while循环之类的,直至INSERT成功再返回。
- 这种锁也是非可重入的,因为同一个线程在没有释放锁之前无法再次获得锁,因为数据库中已经存在同一份记录了。想要实现可重入锁,可以在数据库中添加一些字段,比如获得锁的主机信息、线程信息等,那么在再次获得锁的时候可以先查询数据,如果当前的主机信息和线程信息等能被查到的话,可以直接把锁分配给它。
- 在 MySQL 数据库中采用主键冲突防重,在大并发情况下有可能会造成锁表现象
基于乐观锁
可基于MVCC机制实现
-
优点:在检测数据冲突时并不依赖数据库本身的锁机制,不会影响请求的性能,当产生并发且并发量较小的时候只有少部分请求会失败
-
缺点: 唯一癿问题就是对数据表侵入较大,我们
要为每个表设计一个版本号字段,然后写一条判断 sql 每次进行判断,增加了数据库操作的次数,在高并发要求下,对数据库连接的开销也是无法忍受的。
基于悲观锁
在查询语句后面增加for update, 数据库会在查询过程中给数据库表增加排他锁, 当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以任务获得排他锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法后,通过connection.commit()操作来释放锁
注意:在加锁的时候,只有明确地指定主键(或索引)的才会执行行锁,否则MySQL 将会执行表锁
加锁前注意取消自动提交
优点:
- 简单易于理解
- 严格保证数据访问的安全
缺点:
- MySQL会对查询进行优化,如果任务全表扫描效率更高,便使用表锁,导致性能问题
- 如果一个排他锁长时间不提交,就会占用数据库连接,类似连接变多,就可能把连接池撑爆
- 悲观锁使用不当还可能产生死锁的情况
- 每次请求都会额外产生加锁的开销且未获取到锁的请求将会阻塞等待锁的获取,在高并发环境下,容易造成大量请求阻塞,影响系统可用性
基于redis
Java jedis分布式锁例子
依赖(注意版本2.9.0后,但3以上不支持)
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
public class RedisTool {
private static final String LOCK_SUCCESS = "OK";
private static final String SET_IF_NOT_EXIST = "NX";
private static final String SET_WITH_EXPIRE_TIME = "PX";
/**
* 尝试获取分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @param expireTime 超期时间
* @return 是否获取成功
*/
public static boolean tryGetDistributedLock(Jedis jedis, String lockKey, String requestId, int expireTime) {
/**
* 1. 使用key来当锁,因为key是唯一的
* 2. value,传的是requestId。通过给value赋值为requestId,我们就知道这把锁是哪个请求加的了,在解锁的时候就可以有依据
* 3. NX,意思是SET IF NOT EXIST,即当key不存在时,我们进行set操作;若key已经存在,则不做任何操作;
* 4. PX,意思是我们要给这个key加一个过期的设置,具体时间由第五个参数决定。
* 5. time,代表key的过期时间
*/
String result = jedis.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime);
if (LOCK_SUCCESS.equals(result)) {
return true;
}
return false;
}
private static final Long RELEASE_SUCCESS = 1L;
/**
* 释放分布式锁
* @param jedis Redis客户端
* @param lockKey 锁
* @param requestId 请求标识
* @return 是否释放成功
*/
public static boolean releaseDistributedLock(Jedis jedis, String lockKey, String requestId) {
/**
* 使用Lua语言来实现,来确保上述操作是原子性。在eval命令执行Lua代码的时候,Lua代码将被当成一个命令去执行,并且直到eval命令执行完成,Redis才会执行其他命令。
* 参数KEYS[1]赋值为lockKey,ARGV[1]赋值为requestId
*/
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
Object result = jedis.eval(script, Collections.singletonList(lockKey), Collections.singletonList(requestId));
if (RELEASE_SUCCESS.equals(result)) {
return true;
}
return false;
}
}
执行上面的set()方法就只会导致两种结果:
- 当前没有锁(key不存在),那么就进行加锁操作,并对锁设置个有效期,同时value表示加锁的客户端。
- 已有锁存在,不做任何操作。
Redisson实现分布式锁
使用流程如下,创建Redisson实例(单机或哨兵模式),然后通过getLock获取锁,后续是进行lock和unlock操作。
// 1. Create config object
Config config = new Config();
config.useClusterServers()
// use "rediss://" for SSL connection
.addNodeAddress("redis://127.0.0.1:7181");
// 2. Create Redisson instance
// Sync and Async API
RedissonClient redisson = Redisson.create(config);
// 3. Get Redis based implementation of java.util.concurrent.locks.Lock
RLock lock = redisson.getLock("myLock");
具体使用例子可参考:https://www.cnblogs.com/milicool/p/9201271.html
基于zookeeper
zookeeper基本锁原理
利用临时节点与watch机制,每个锁占用一个普通节点/lock,当需要获取锁时,在/lock目录下创建一个临时节点,创建成功则表示获取锁成功,失败则watch /lock节点,有删除操作后再去争锁。
临时节点
- 好处:在于当进程挂掉后能自动上锁的节点自动删除,即取消锁
- 缺点: 所有取锁失败的进程都监听父节点,很容易发生羊群效应,即当释放锁后所有等待进程一起来创建节点,并发量很大
zookeeper锁优化原理
上锁改为创建临时有序节点,每个上锁的节点均能创建节点成功,只是其序号不同,只有序号最小的可以拥有锁,如果这个节点序号不是最小的则watch序号比本身小的前一个节点。
步骤:
- 在/lock节点下创建一个有序临时节点(EPHEMERAL_SEQUENTIAL)
- 判断创建的节点序号是否最小,如果是则获取锁成功。不是则获取锁失败,watch序号比本身小的前一个节点(避免很多线程watch同一个node,导致羊群效应)
- 当获取锁失败,设置watch后则等待watch事件到来后,再次判断是否序号最小
- 取锁成功则执行代码,最后释放锁(删除该节点)
优缺点:
- 优点:有效的解决单点问题,不可重入问题,非阻塞问题,以及锁无法释放问题。实现简单
- 缺点:性能上可能没有缓存服务高,因为每次在创建锁和释放锁过程中,都要动态创建、销毁临时节点来实现锁功能。zookeeper中创建和删除节点只能通过Leader服务器来执行,然后将数据同步到所有follower机器上。
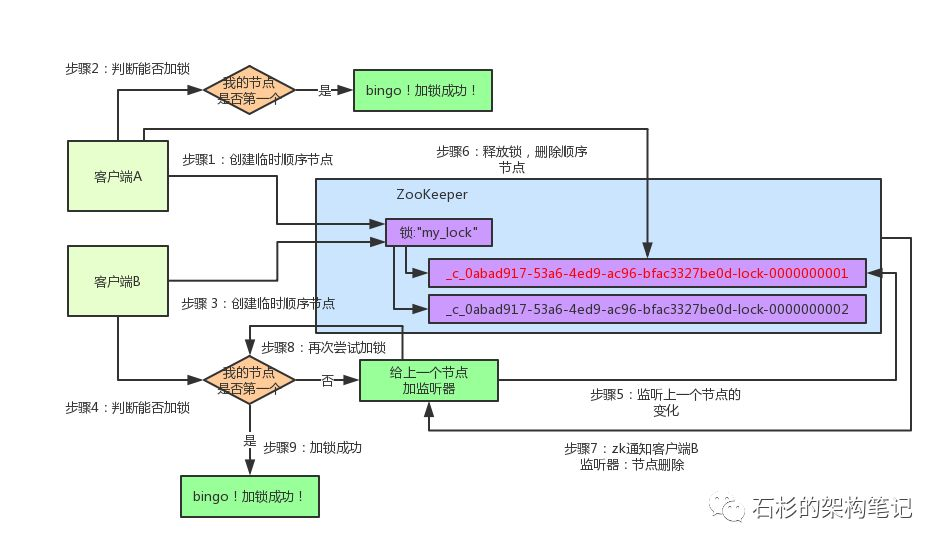
(图片来自https://mp.weixin.qq.com/s/jn4LkPKlWJhfUwIKkp3KpQ)
开源框架Curator
Curator开源框架对zookeeper分布式锁进行了实现。具体例子可参考:https://www.jianshu.com/p/31335efec309
参考:
https://mp.weixin.qq.com/s/jn4LkPKlWJhfUwIKkp3KpQ
https://blog.csdn.net/u013256816/article/details/92854794
https://www.cnblogs.com/milicool/p/9201271.html
https://mp.weixin.qq.com/s/y_Uw3P2Ll7wvk_j5Fdlusw
https://mp.weixin.qq.com/s/ovBtKTs-ycOWXSpZqRm6BA
https://mp.weixin.qq.com/s/iOtnIEPlEM1crBIgHXDZsg
https://mp.weixin.qq.com/s/95N8mKRreeOwaXLttYCbcQ