一 Hadoop简介
Hadoop 2.7.2 Doc refer to http://hadoop.apache.org/docs/r2.7.2/
-
HDFS (The following is a subset of useful features in HDFS:)
-
- File permissions and authentication.
-
- Rack awareness: to take a node’s physical location into account while scheduling tasks and allocating storage.
-
- Safemode: an administrative mode for maintenance.
-
- fsck: a utility to diagnose health of the file system, to find missing files or blocks.
-
- Balancer: tool to balance the cluster when the data is unevenly distributed among DataNodes.
-
- Upgrade and rollback: after a software upgrade, it is possible to rollback to HDFS’ state before the upgrade in case of unexpected problems.
-
- Secondary NameNode: performs periodic checkpoints of the namespace and helps keep the size of file containing log of HDFS modifications within certain limits at the NameNode.
-
- Checkpoint node: performs periodic checkpoints of the namespace and helps minimize the size of the log stored at the NameNode containing changes to the HDFS. Replaces the role previously filled by the Secondary NameNode, though is not yet battle hardened. The NameNode allows multiple Checkpoint nodes simultaneously, as long as there are no Backup nodes registered with the system.
-
- Backup node: An extension to the Checkpoint node. In addition to checkpointing it also receives a stream of edits from the NameNode and maintains its own in-memory copy of the namespace, which is always in sync with the active NameNode namespace state. Only one Backup node may be registered with the NameNode at once.
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs.
The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.
The ResourceManager has two main components: Scheduler and ApplicationsManager.
The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application. Also, it offers no guarantees about restarting failed tasks either due to application failure or hardware failures. The Scheduler performs its scheduling function based the resource requirements of the applications; it does so based on the abstract notion of a resource Container which incorporates elements such as memory, cpu, disk, network etc.
The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster and provides the service for restarting the ApplicationMaster container on failure. The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress.

HDFS daemons are NameNode, SecondaryNameNode, and DataNode. YARN damones are ResourceManager, NodeManager, and WebAppProxy. If MapReduce is to be used, then the MapReduce Job History Server will also be running. For large installations, these are generally running on separate hosts.
-
MapReduce (refer to http://hadoop.apache.org/docs/r2.7.2/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html)
Mapper
Mapper maps input key/value pairs to a set of intermediate key/value pairs.
Maps are the individual tasks that transform input records into intermediate records. The transformed intermediate records do not need to be of the same type as the input records. A given input pair may map to zero or many output pairs.
The Hadoop MapReduce framework spawns one map task for each InputSplit generated by the InputFormat for the job.
Overall, Mapper implementations are passed the Job for the job via the Job.setMapperClass(Class) method. The framework then calls map(WritableComparable, Writable, Context) for each key/value pair in the InputSplit for that task. Applications can then override the cleanup(Context) method to perform any required cleanup.
Output pairs do not need to be of the same types as input pairs. A given input pair may map to zero or many output pairs. Output pairs are collected with calls to context.write(WritableComparable, Writable).
Applications can use the Counter to report its statistics.
All intermediate values associated with a given output key are subsequently grouped by the framework, and passed to the Reducer(s) to determine the final output. Users can control the grouping by specifying a Comparator via Job.setGroupingComparatorClass(Class).
The Mapper outputs are sorted and then partitioned per Reducer. The total number of partitions is the same as the number of reduce tasks for the job. Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
Users can optionally specify a combiner, via Job.setCombinerClass(Class), to perform local aggregation of the intermediate outputs, which helps to cut down the amount of data transferred from the Mapper to the Reducer.
The intermediate, sorted outputs are always stored in a simple (key-len, key, value-len, value) format. Applications can control if, and how, the intermediate outputs are to be compressed and the CompressionCodec to be used via the Configuration.
Reducer
Reducer reduces a set of intermediate values which share a key to a smaller set of values.
The number of reduces for the job is set by the user via Job.setNumReduceTasks(int).
Overall, Reducer implementations are passed the Job for the job via the Job.setReducerClass(Class) method and can override it to initialize themselves. The framework then calls reduce(WritableComparable, Iterable<Writable>, Context) method for each <key, (list of values)> pair in the grouped inputs. Applications can then override the cleanup(Context) method to perform any required cleanup.
Reducer has 3 primary phases: shuffle, sort and reduce.
Shuffle
Input to the Reducer is the sorted output of the mappers. In this phase the framework fetches the relevant partition of the output of all the mappers, via HTTP.
Sort
The framework groups Reducer inputs by keys (since different mappers may have output the same key) in this stage.
The shuffle and sort phases occur simultaneously; while map-outputs are being fetched they are merged.
Secondary Sort
If equivalence rules for grouping the intermediate keys are required to be different from those for grouping keys before reduction, then one may specify a Comparator via Job.setSortComparatorClass(Class). Since Job.setGroupingComparatorClass(Class) can be used to control how intermediate keys are grouped, these can be used in conjunction to simulate secondary sort on values.
Reduce
In this phase the reduce(WritableComparable, Iterable<Writable>, Context) method is called for each <key, (list of values)> pair in the grouped inputs.
The output of the reduce task is typically written to the FileSystem via Context.write(WritableComparable, Writable).
Applications can use the Counter to report its statistics.
The output of the Reducer is not sorted.
Counter
Counter is a facility for MapReduce applications to report its statistics.
Mapper and Reducer implementations can use the Counter to report statistics.
Hadoop MapReduce comes bundled with a library of generally useful mappers, reducers, and partitioners.
下面的解说参考 http://itfish.net/article/58322.html
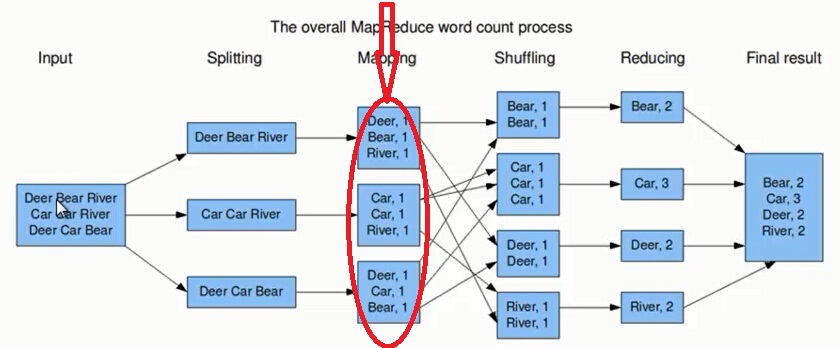
上图的流程大概分为以下几步。
第一步:假设一个文件有三行英文单词作为 MapReduce 的Input(输入),这里经过 Splitting 过程把文件分割为3块。分割后的3块数据就可以并行处理,每一块交给一个 map 线程处理。
第二步:每个 map 线程中,以每个单词为key,以1作为词频数value,然后输出。
第三步:每个 map 的输出要经过 shuffling(混洗),将相同的单词key放在一个桶里面,然后交给 reduce 处理。
第四步:reduce 接受到 shuffling 后的数据, 会将相同的单词进行合并,得到每个单词的词频数,最后将统计好的每个单词的词频数作为输出结果。
上述就是 MapReduce 的大致流程,前两步可以看做 map 阶段,后两步可以看做 reduce 阶段。下面我们来看看 MapReduce 大致实现。
1、Input:首先 MapReduce 输入的是一系列key/value对。key表示每行偏移量,value代表每行输入的单词。
2、用户提供了 map 函数和 reduce 函数的实现:
map(k,v) ——> list(k1,v1)
reduce(k1,list(v1)) ——>(k2,v2)map 函数将每个单词转化为key/value对输出,这里key为每个单词,value为词频1。(k1,v1)是 map 输出的中间key/value结果对。reduce 将相同单词的所有词频进行合并,比如将单词k1,词频为list(v1),合并为(k2,v2)。reduce 合并完之后,最终输出一系列(k2,v2)键值对。
下面我们来看一下 MapReduce 的伪代码。
map(key,value)://map 函数,key代表偏移量,value代表每行单词
for each word w in value: //循环每行数据,输出每个单词和词频的键值对(w,1)
emit(w,1)
reduce(key,values)://reduce 函数,key代表一个单词,value代表这个单词的所有词频数集合
result=0
for each count v in values: //循环词频集合,求出该单词的总词频数,然后输出(key,result)
result+=v
emit(key,result) 讲到这里,我们可以对 MapReduce 做一个总结。MapReduce 将 作业的整个运行过程分为两个阶段:Map 阶段和Reduce 阶段。
1、Map 阶段
Map 阶段是由一定数量的 Map Task 组成。这些 Map Task 可以同时运行,每个 Map Task又是由以下三个部分组成。
1) 对输入数据格式进行解析的一个组件:InputFormat。因为不同的数据可能存储的数据格式不一样,这就需要有一个
InputFormat 组件来解析这些数据的存放格式。默认情况下,它提供了一个 TextInputFormat
来解释数据格式。TextInputFormat
就是我们前面提到的文本文件输入格式,它会将文件的每一行解释成(key,value),key代表每行偏移量,value代表每行数据内容。
通常情况我们不需要自定义 InputFormat,因为 MapReduce
提供了很多种InputFormat的实现,我们根据不同的数据格式,选择不同的 InputFormat 来解释就可以了。这一点我们后面会讲到。
2)输入数据处理:Mapper。这个 Mapper 是必须要实现的,因为根据不同的业务对数据有不同的处理。
3)数据分组:Partitioner。Mapper 数据处理之后输出之前,输出key会经过 Partitioner
分组或者分桶选择不同的reduce。默认的情况下,Partitioner 会对 map 输出的key进行hash取模,比如有6个Reduce
Task,它就是模(mod)6,如果key的hash值为0,就选择第0个 Reduce Task,如果key的hash值为1,就选择第一个
Reduce Task。这样不同的 map 对相同单词key,它的 hash 值取模是一样的,所以会交给同一个 reduce 来处理。
2、Reduce 阶段
1) 数据运程拷贝。Reduce Task 要运程拷贝每个 map 处理的结果,从每个 map 中读取一部分结果。每个 Reduce Task 拷贝哪些数据,是由上面 Partitioner 决定的。
2) 数据按照key排序。Reduce Task 读取完数据后,要按照key进行排序。按照key排序后,相同的key被分到一组,交给同一个 Reduce Task 处理。
3) 数据处理:Reducer。以WordCount为例,相同的单词key分到一组,交个同一个Reducer处理,这样就实现了对每个单词的词频统计。
4) 数据输出格式:OutputFormat。Reducer 统计的结果,将按照 OutputFormat 格式输出。默认情况下的输出格式为 TextOutputFormat,以WordCount为例,这里的key为单词,value为词频数。
从上图以及MapReduce 的作业的整个运行过程我们可以看出存在以下问题:
1)Map Task输出的数据量(即磁盘IO)大。Map Task 将输出的数据写到本地磁盘,它输出的数据量越多,它写入磁盘的数据量就越大,那么开销就越大,速度就越慢。
2)Reduce-Map网络传输的数据量(网络IO)大,浪费了大量的网络资源。
3)容易造成负载不均。
二 安装
refer to http://kiwenlau.com/2016/06/12/160612-hadoop-cluster-docker-update/
将Hadoop打包到Docker镜像中,就可以快速地在单个机器上搭建Hadoop集群,这样可以方便新手测试和学习。
如下图所示,Hadoop的master和slave分别运行在不同的Docker容器中,其中hadoop-master容器中运行NameNode和ResourceManager,hadoop-slave容器中运行DataNode和NodeManager。NameNode和DataNode是Hadoop分布式文件系统HDFS的组件,负责储存输入以及输出数据,而ResourceManager和NodeManager是Hadoop集群资源管理系统YARN的组件,负责CPU和内存资源的调度。

0. Config daocloud mirror in Docker preference,then click "Apply & restart"
http://f5bfae5c.m.daocloud.io

Note: you can get your own address from https://www.daocloud.io/mirror#accelerator-doc
1. Get docker image from http://hub.daocloud.io/repos/a6ad6f88-5a2d-4ce5-aa2b-28b9e319245a
#docker pull daocloud.io/shenaishiren/hadoop:latest
1 latest: Pulling from shenaishiren/hadoop 2 3 30d541b48fc0: Pull complete 4 8ecd7f80d390: Pull complete 5 46ec9927bb81: Pull complete 6 2e67a4d67b44: Pull complete 7 7d9dd9155488: Pull complete 8 f4b26556b9eb: Pull complete 9 4941810204eb: Pull complete 10 0ef1658fe392: Pull complete 11 70b153348d7e: Pull complete 12 9b2cd2b98b85: Pull complete 13 b308ac2908a4: Pull complete 14 dab22f91ceaa: Pull complete 15 59bf5b0e2148: Pull complete 16 Digest: sha256:b311229157592326eb3f889867c08878435ab9cfb255f91e44e4d101effff748 17 Status: Downloaded newer image for daocloud.io/shenaishiren/hadoop:latest
2. Get github
#git clone https://github.com/kiwenlau/hadoop-cluster-docker
Cloning into 'hadoop-cluster-docker'... remote: Counting objects: 385, done. remote: Total 385 (delta 0), reused 0 (delta 0), pack-reused 384 Receiving objects: 100% (385/385), 186.67 KiB | 5.00 KiB/s, done. Resolving deltas: 100% (207/207), done. Checking connectivity... done.
3. Modify image names to keep the same as github script
#docker tag daocloud.io/shenaishiren/hadoop:latest kiwenlau/hadoop:1.0
4. Create docker network
#sudo docker network create --driver=bridge hadoop
$ docker network ls NETWORK ID NAME DRIVER SCOPE 5998a7bf15d9 bridge bridge local d5a6fd4d9dd2 hadoop bridge local bb796b08d54d host host local bedd5d832347 none null local
5. Start docker container
#sudo ./start-container.sh
start hadoop-master container... start hadoop-slave1 container... start hadoop-slave2 container... root@hadoop-master:~#
6. Start hadoop
root@hadoop-master:~# ./start-hadoop.sh
root@hadoop-master:~# ls hdfs run-wordcount.sh start-hadoop.sh root@hadoop-master:~# cat start-hadoop.sh #!/bin/bash echo -e "\n" $HADOOP_HOME/sbin/start-dfs.sh echo -e "\n" $HADOOP_HOME/sbin/start-yarn.sh echo -e "\n" root@hadoop-master:~# ./start-hadoop.sh Starting namenodes on [hadoop-master] hadoop-master: Warning: Permanently added 'hadoop-master,172.18.0.2' (ECDSA) to the list of known hosts. hadoop-master: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-hadoop-master.out hadoop-slave2: Warning: Permanently added 'hadoop-slave2,172.18.0.4' (ECDSA) to the list of known hosts. hadoop-slave1: Warning: Permanently added 'hadoop-slave1,172.18.0.3' (ECDSA) to the list of known hosts. hadoop-slave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop-slave1.out hadoop-slave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-hadoop-slave2.out hadoop-slave4: ssh: Could not resolve hostname hadoop-slave4: Name or service not known hadoop-slave3: ssh: Could not resolve hostname hadoop-slave3: Name or service not known Starting secondary namenodes [0.0.0.0] 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-hadoop-master.out starting yarn daemons starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-hadoop-master.out hadoop-slave1: Warning: Permanently added 'hadoop-slave1,172.18.0.3' (ECDSA) to the list of known hosts. hadoop-slave2: Warning: Permanently added 'hadoop-slave2,172.18.0.4' (ECDSA) to the list of known hosts. hadoop-slave1: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-hadoop-slave1.out hadoop-slave2: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-hadoop-slave2.out hadoop-slave3: ssh: Could not resolve hostname hadoop-slave3: Name or service not known hadoop-slave4: ssh: Could not resolve hostname hadoop-slave4: Name or service not known root@hadoop-master:~#
7. Run wordcount
./run-wordcount.sh
root@hadoop-master:~# ./run-wordcount.sh 17/03/22 09:25:32 INFO client.RMProxy: Connecting to ResourceManager at hadoop-master/172.18.0.2:8032 17/03/22 09:25:33 INFO input.FileInputFormat: Total input paths to process : 2 17/03/22 09:25:34 INFO mapreduce.JobSubmitter: number of splits:2 17/03/22 09:25:34 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1490174655916_0001 17/03/22 09:25:35 INFO impl.YarnClientImpl: Submitted application application_1490174655916_0001 17/03/22 09:25:35 INFO mapreduce.Job: The url to track the job: http://hadoop-master:8088/proxy/application_1490174655916_0001/ 17/03/22 09:25:35 INFO mapreduce.Job: Running job: job_1490174655916_0001 17/03/22 09:25:51 INFO mapreduce.Job: Job job_1490174655916_0001 running in uber mode : false 17/03/22 09:25:51 INFO mapreduce.Job: map 0% reduce 0% 17/03/22 09:26:08 INFO mapreduce.Job: map 100% reduce 0% 17/03/22 09:26:20 INFO mapreduce.Job: map 100% reduce 100% 17/03/22 09:26:21 INFO mapreduce.Job: Job job_1490174655916_0001 completed successfully 17/03/22 09:26:21 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=56 FILE: Number of bytes written=352398 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=258 HDFS: Number of bytes written=26 HDFS: Number of read operations=9 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=31510 Total time spent by all reduces in occupied slots (ms)=8918 Total time spent by all map tasks (ms)=31510 Total time spent by all reduce tasks (ms)=8918 Total vcore-milliseconds taken by all map tasks=31510 Total vcore-milliseconds taken by all reduce tasks=8918 Total megabyte-milliseconds taken by all map tasks=32266240 Total megabyte-milliseconds taken by all reduce tasks=9132032 Map-Reduce Framework Map input records=2 Map output records=4 Map output bytes=42 Map output materialized bytes=62 Input split bytes=232 Combine input records=4 Combine output records=4 Reduce input groups=3 Reduce shuffle bytes=62 Reduce input records=4 Reduce output records=3 Spilled Records=8 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=472 CPU time spent (ms)=5510 Physical memory (bytes) snapshot=808607744 Virtual memory (bytes) snapshot=2650054656 Total committed heap usage (bytes)=475004928 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=26 File Output Format Counters Bytes Written=26 input file1.txt: Hello Hadoop input file2.txt: Hello Docker wordcount output: Docker 1 Hadoop 1 Hello 2 root@hadoop-master:~#
8.Hadoop网页管理地址:
- NameNode: http://192.168.59.1:50070/
- ResourceManager: http://192.168.59.1:8088/
注:192.168.59.1为运行容器的主机的IP。具体IP以运行时日志为准
9 结束容器
#docker stop hadoop-master hadoop-slave1 hadoop-slave2
脚本分析
1. start-container.sh
该脚本依次启动了master X 1、slave X 2 三个container,以指定的Hadoop网络运行并且映射了50070 和8088 管理端口
1 cat start-container.sh 2 #!/bin/bash 3 4 # the default node number is 3 5 N=${1:-3} 6 7 8 # start hadoop master container 9 sudo docker rm -f hadoop-master &> /dev/null 10 echo "start hadoop-master container..." 11 sudo docker run -itd \ 12 --net=hadoop \ 13 -p 50070:50070 \ 14 -p 8088:8088 \ 15 --name hadoop-master \ 16 --hostname hadoop-master \ 17 kiwenlau/hadoop:1.0 &> /dev/null 18 19 20 # start hadoop slave container 21 i=1 22 while [ $i -lt $N ] 23 do 24 sudo docker rm -f hadoop-slave$i &> /dev/null 25 echo "start hadoop-slave$i container..." 26 sudo docker run -itd \ 27 --net=hadoop \ 28 --name hadoop-slave$i \ 29 --hostname hadoop-slave$i \ 30 kiwenlau/hadoop:1.0 &> /dev/null 31 i=$(( $i + 1 )) 32 done 33 34 # get into hadoop master container 35 sudo docker exec -it hadoop-master bash
启动成功后在运行容器的主机可以看到
1 bogon:~ test$ docker ps -a 2 CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 3 9f9aad061f33 kiwenlau/hadoop:1.0 "sh -c 'service ssh s" 36 seconds ago Up 35 seconds hadoop-slave2 4 de28037f2543 kiwenlau/hadoop:1.0 "sh -c 'service ssh s" 37 seconds ago Up 35 seconds hadoop-slave1 5 9817f2d11341 kiwenlau/hadoop:1.0 "sh -c 'service ssh s" 38 seconds ago Up 36 seconds 0.0.0.0:8088->8088/tcp, 0.0.0.0:50070->50070/tcp hadoop-master
2. 容器Master中的start-hadoop.sh
1 root@hadoop-master:~# cat start-hadoop.sh 2 #!/bin/bash 3 echo -e "\n" 4 $HADOOP_HOME/sbin/start-dfs.sh 5 echo -e "\n" 6 $HADOOP_HOME/sbin/start-yarn.sh 7 echo -e "\n"
其中start-dfs.sh用来启动HDFS系统
start-yarn.sh用来启动Yarn集群资源管理器
相关配置
1 root@hadoop-master:/usr/local/hadoop# cat etc/hadoop/slaves 2 hadoop-slave1 3 hadoop-slave2 4 hadoop-slave3 5 hadoop-slave4
3. run-wordcount.sh
经典的分词统计
相关原理参考 http://itfish.net/article/58322.html
1 root@hadoop-master:~# cat run-wordcount.sh 2 #!/bin/bash 3 4 # test the hadoop cluster by running wordcount 5 6 # create input files 7 mkdir input 8 echo "Hello Docker" >input/file2.txt 9 echo "Hello Hadoop" >input/file1.txt 10 11 # create input directory on HDFS 12 hadoop fs -mkdir -p input 13 14 # put input files to HDFS 15 hdfs dfs -put ./input/* input 16 17 # run wordcount 18 hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.7.2-sources.jar org.apache.hadoop.examples.WordCount input output 19 20 # print the input files 21 echo -e "\ninput file1.txt:" 22 hdfs dfs -cat input/file1.txt 23 24 echo -e "\ninput file2.txt:" 25 hdfs dfs -cat input/file2.txt 26 27 # print the output of wordcount 28 echo -e "\nwordcount output:" 29 hdfs dfs -cat output/part-r-00000 30 31 root@hadoop-master:~#