上一篇我们介绍了使用 Hystrix Dashboard 来展示 Hystrix 用于熔断的各项度量指标。通过 Hystrix Dashboard,我们可以方便的查看服务实例的综合情况,比如:服务调用次数、服务调用延迟等。但是仅通过 Hystrix Dashboard 我们只能实现对服务当个实例的数据展现,在生产环境我们的服务是肯定需要做高可用的,那么对于多实例的情况,我们就需要将这些度量指标数据进行聚合。下面,我们就来介绍一下另外一个工具:Turbine。
准备工作
我们将用到之前实现的几个应用,包括:
- eureka-server:服务注册中心
- service-producer:服务提供者
- service-hystrix-feign:使用 Feign 和 Hystrix 实现的服务消费者
- service-hystrix-ribbon:使用 Ribbon 和 Hystrix 实现的服务消费者
- service-hystrix-dashboard:用于展示 service-hystrix-feign 和 service-hystrix-ribbon 服务的 Hystrix 数据
创建 Turbine
创建一个标准的 Spring Boot 工程,命名为:service-turbine
POM 依赖
1 <dependency>
2 <groupId>org.springframework.cloud</groupId>
3 <artifactId>spring-cloud-starter-netflix-turbine</artifactId>
4 </dependency>
配置文件
在 application.yml 加入 Eureka 和 Turbine 的相关配置
spring:
application:
name: service-turbine
server:
port: 8090
management:
port: 8091
eureka:
client:
service-url:
defaultZone: http://admin:123456@localhost:8761/eureka/
turbine:
app-config: service-hystrix-feign,service-hystrix-ribbon #多个用逗号分隔
cluster-name-expression: new String("default")
combine-host-port: true
参数说明
turbine.app-config参数指定了需要收集监控信息的服务名turbine.cluster-name-expression参数指定了集群名称为default,当我们服务数量非常多的时候,可以启动多个 Turbine 服务来构建不同的聚合集群,而该参数可以用来区分这些不同的聚合集群,同时该参数值可以在 Hystrix 仪表盘中用来定位不同的聚合集群,只需要在 Hystrix Stream 的 URL 中通过 cluster 参数来指定turbine.combine-host-port参数设置为true,可以让同一主机上的服务通过主机名与端口号的组合来进行区分,默认情况下会以 host 来区分不同的服务,这会使得在本地调试的时候,本机上的不同服务聚合成一个服务来统计
注意:new String("default")这个一定要用 String 来包一下,否则启动的时候会抛出异常:
org.springframework.expression.spel.SpelEvaluationException: EL1008E: Property or field 'default' cannot be found on object of type 'com.netflix.appinfo.InstanceInfo' - maybe not public or not valid?
启动类
在启动类上使用@EnableTurbine注解开启 Turbine
1 package com.carry.springcloud;
2
3 import org.springframework.boot.SpringApplication;
4 import org.springframework.boot.autoconfigure.SpringBootApplication;
5 import org.springframework.cloud.netflix.turbine.EnableTurbine;
6
7 @EnableTurbine
8 @SpringBootApplication
9 public class ServiceTurbineApplication {
10
11 public static void main(String[] args) {
12 SpringApplication.run(ServiceTurbineApplication.class, args);
13 }
14 }
测试
分别启动
- eureka-server
- service-producer
- service-hystrix-feign
- service-hystrix-ribbon
- service-hystrix-dashboard
- service-turbine
访问 Hystrix Dashboard 并开启对 http://localhost:8090/turbine.stream 的监控,这时候,我们将看到针对服务 service-hystrix-feign 与 service-hystrix-ribbon 的聚合监控数据
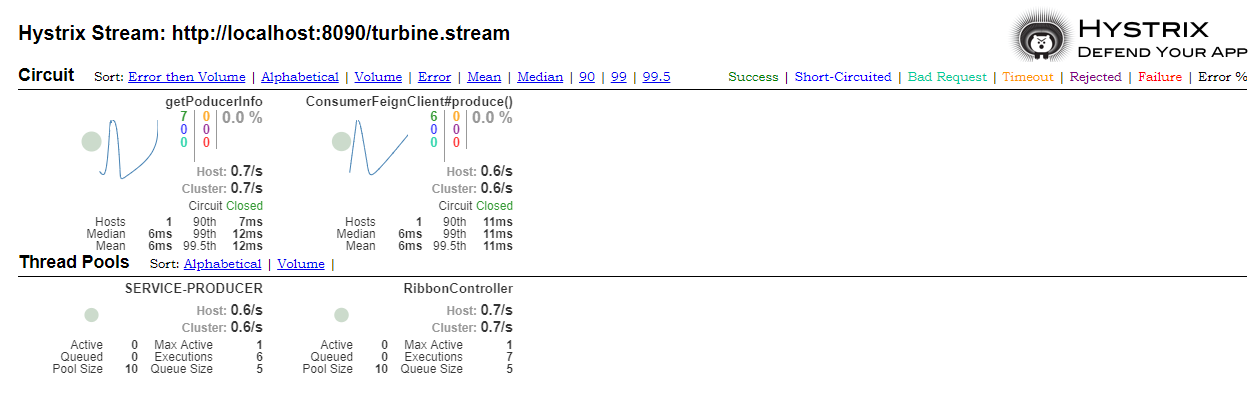
注意:服务 service-hystrix-ribbon 需要跟 service-hystrix-feign 一样暴露 hystrix.stream 端口