最近在做一些OpenCV算法优化相关的东西,发现OpenCV新版本现在的执行效率很高的原因一部分是来自于底层的优化,比如指令集优化。根据个人的实践经验,程序优化主要是以下三个步骤:
1.算法优化
2.代码优化
3.指令优化
算法优化
算法上的优化是必须首要考虑的,也是最重要的一步。一般我们需要分析算法的时间复杂度,即处理时间与输入数据规模的一个量级关系,一个优秀的算法可以将算法复杂度降低若干量级,那么同样的实现,其平均耗时一般会比其他复杂度高的算法少(这里不代表任意输入都更快)。
比如说排序算法,快速排序的时间复杂度为O(nlogn),而插入排序的时间复杂度为O(n*n),那么在统计意义下,快速排序会比插入排序快,而且随着输入序列长度n的增加,两者耗时相差会越来越大。但是,假如输入数据本身就已经是升序(或降序),那么实际运行下来,快速排序会更慢。
因此,实现同样的功能,优先选择时间复杂度低的算法。比如对图像进行二维可分的高斯卷积,图像尺寸为MxN,卷积核尺寸为PxQ,那么
直接按卷积的定义计算,时间复杂度为O(MNPQ)
如果使用2个一维卷积计算,则时间复杂度为O(MN(P+Q))
使用2个一位卷积+FFT来实现,时间复杂度为O(MNlogMN)
如果采用高斯滤波的递归实现,时间复杂度为O(MN)(参见paper:Recursive implementation of the Gaussian filter,源码在GIMP中有)
很显然,上面4种算法的效率是逐步提高的。一般情况下,自然会选择最后一种来实现。
还有一种情况,算法本身比较复杂,其时间复杂度难以降低,而其效率又不满足要求。这个时候就需要好好理解算法,做些修改。一种是保持算法效果来提升效率,另一种是舍弃部分效果来换取一定的效率,具体做法得根据实际情况操作。举例如:Using an fast floating-point “atan2” approximation instead of C++ standard “atan2”
Details: When I checked the CPU time, I found that 40.74 percent of time were spent in “std::atan2”. So I changed it to use a polynomial approximation which has a maximum error 0.005 radians. I think this error is tolerable in our case.
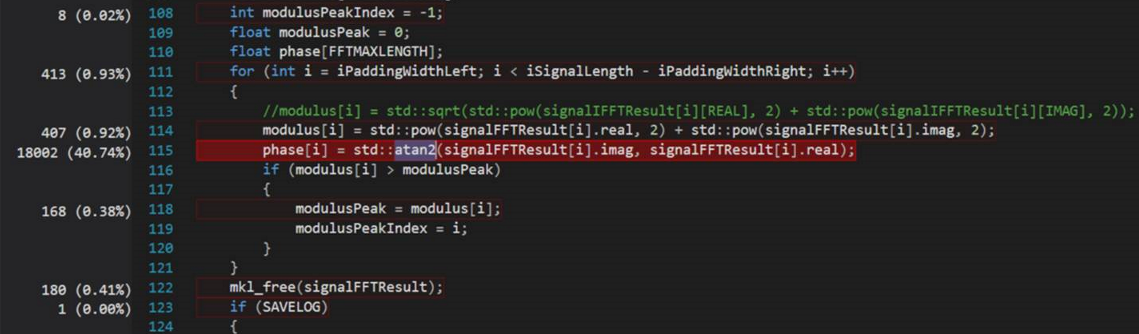
After using the approximation “atan2”, the CPU usage drops to 16.33 percent for the “atan2” calculation. And the time cost also drops.
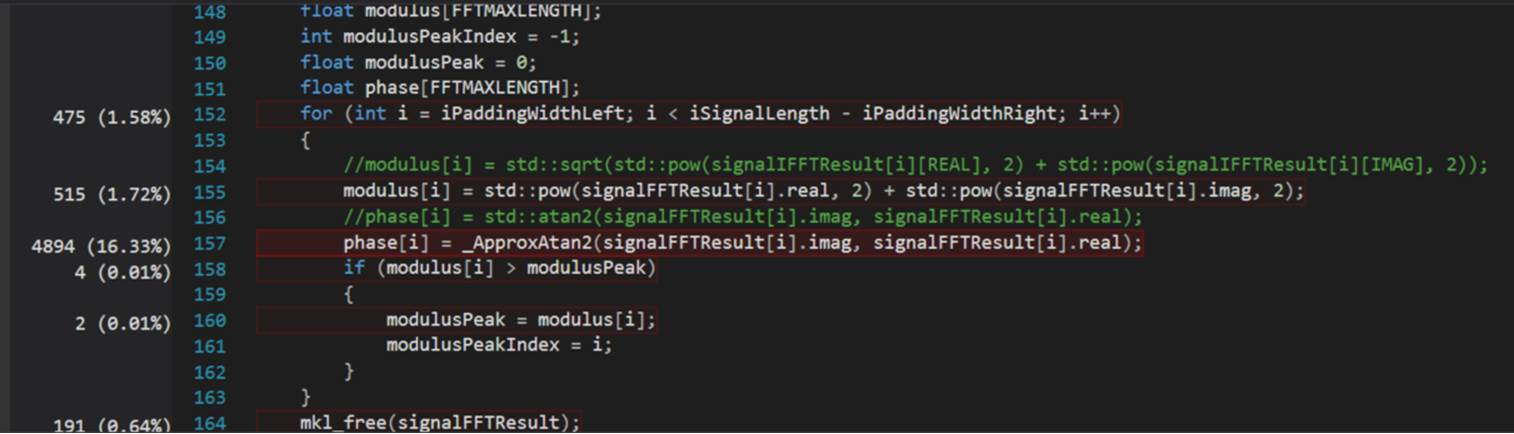
代码优化
代码优化一般需要与算法优化同步进行,代码优化主要是涉及到具体的编码技巧。同样的算法与功能,不同的写法也可能让程序效率差异巨大。一般而言,代码优化主要是针对循环结构进行分析处理,目前想到的几条原则是:
a.避免循环内部的乘(除)法以及冗余计算
b.避免循环内部有过多依赖和跳转,使cpu能流水起来
关于CPU流水线技术可google/baidu,循环结构内部计算或逻辑过于复杂,将导致cpu不能流水,那这个循环就相当于拆成了n段重复代码的效率。
另外ii值是衡量循环结构的一个重要指标,ii值是指执行完1次循环所需的指令数,ii值越小,程序执行耗时越短。下图是关于cpu流水的简单示意图:

简单而不严谨地说,cpu流水技术可以使得循环在一定程度上并行,即上次循环未完成时即可处理本次循环,这样总耗时自然也会降低。
c.定点化
定点化的思想是将浮点运算转换为整型运算,目前在PC上我个人感觉差别还不算大,但在很多性能一般的DSP上,其作用也不可小觑。定点化的做法是将数据乘上一个很大的数后,将所有运算转换为整数计算。例如某个乘法我只关心小数点后3位,那把数据都乘上10000后,进行整型运算的结果也就满足所需的精度了。
d.以空间换时间
空间换时间最经典的就是查表法了,某些计算相当耗时,但其自变量的值域是比较有限的,这样的情况可以预先计算好每个自变量对应的函数值,存在一个表格中,每次根据自变量的值去索引对应的函数值即可。
e.预分配内存
预分配内存主要是针对需要循环处理数据的情况的。比如视频处理,每帧图像的处理都需要一定的缓存,如果每帧申请释放,则势必会降低算法效率。
指令优化
对于经过前面算法和代码优化的程序,一般其效率已经比较不错了。对于某些特殊要求,还需要进一步降低程序耗时,那么指令优化就该上场了。指令优化一般是使用特定的指令集,可快速实现某些运算,同时指令优化的另一个核心思想是打包运算。目前PC上intel指令集有MMX,SSE和SSE2/3/4等,DSP则需要跟具体的型号相关,不同型号支持不同的指令集。intel指令集需要intel编译器才能编译,安装icc后,其中有帮助文档,有所有指令的详细说明。
(1)What is SIMD?

顾名思义,SIMD(Single instruction, multiple data 单指令多数据)是一种在一条指令中处理多个数据的方法。 与需要向每个处理器内核提供不同指令的机制的MIMD(多指令,多数据)相比,SIMD可以设计面积更小的处理器,因为它需要更少的晶体管。 因此,大多数CPU和GPU支持SIMD操作(这里不提及SIMT - 单指令多线程)。 MMX,SSE和AVX是Intel CPU上的SIMD操作指令。
(2)Matrix addition using SSE instructions
因为内联汇编在x64中不可用,所以我们可以使用作为宏的内在函数来扩展汇编。从可移植性的角度来看,最好使用内在函数(intrinsics )。让我们使用SSE,这是Intel CPU的SIMD指令之一。头文件xmmintrin.h包含用于扩展为SSE程序集的宏,因此请包含该宏并执行矩阵加法,如下所示。
#include <stdio.h>
#include <xmmintrin.h>
int main(void) {
__m128 a = {1.0f, 2.0f, 3.0f, 4.0f};
__m128 b = {1.1f, 2.1f, 3.1f, 4.1f};
float c[4];
__m128 ps = _mm_add_ps(a, b); // add
_mm_storeu_ps(c, ps); // store
printf(" source: (%5.1f, %5.1f, %5.1f, %5.1f)
",
a[0], a[1], a[2], a[3]);
printf(" dest. : (%5.1f, %5.1f, %5.1f, %5.1f)
",
b[0], b[1], b[2], b[3]);
printf(" result: (%5.1f, %5.1f, %5.1f, %5.1f)
",
c[0], c[1], c[2], c[3]);
return 0;
}
128位寄存器可用于SSE指令。浮点类型消耗32位,因此可以一次计算4个元素。输出为:
$ gcc -o avx -Wall -O0 main.c $ ./avx- source: ( 1.0, 2.0, 3.0, 4.0) dest. : ( 1.1, 2.1, 3.1, 4.1) result: ( 2.1, 4.1, 6.1, 8.1)
(3)Matrix addition using AVX (AVX2)
在SSE中,SIMD寄存器为128位,因此,如果要计算浮点数据,一次只能计算四个元素。 AVX指令已嵌入256位寄存器,这大大提高了算术性能。此外,后来添加的AVX2还支持整数算术以及浮点运算。基本上,希望在支持AVX2的环境中使用它。使用宏将其扩展为AVX和AVX2程序集时,请包含immintrin.h。
#include <stdio.h>
#include <immintrin.h>
int main(void) {
__m256 a = {1.0f, 2.0f, 3.0f, 4.0f, 5.0f, 6.0f, 7.0f, 8.0f};
__m256 b = {1.1f, 2.1f, 3.1f, 4.1f, 5.1f, 6.1f, 7.1f, 8.1f};
__m256 c;
c = _mm256_add_ps(a, b);
printf(" source: (%5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f)
",
a[0], a[1], a[2], a[3], a[4], a[5], a[6], a[7]);
printf(" dest. : (%5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f)
",
b[0], b[1], b[2], b[3], b[4], b[5], b[6], b[7]);
printf(" result: (%5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f, %5.1f)
",
c[0], c[1], c[2], c[3], c[4], c[5], c[6], c[7]);
return 0;
}
在AVX中,一次可以计算八个元素,因为256位除以32位(浮点消耗4个字节)。 如果要使用双精度而不是浮点数,请使用__m128d;如果要使用整数,请使用__m128i。 请注意,双精度浮点使用8个字节,并且只能处理4个元素。 让我们编译代码:
$ gcc -o avx2 -Wall main.c
main.c:9:9: error: always_inline function '_mm256_add_ps' requires target feature 'xsave', but would be inlined into function 'main' that is compiled without support for 'xsave'
c = _mm256_add_ps(a, b);
^
1 error generated.
编译失败。 通过以下命令确认CPU支持的功能。
$ sysctl -a | grep machdep.cpu.features machdep.cpu.features: FPU VME DE PSE TSC MSR PAE MCE CX8 APIC SEP MTRR PGE MCA CMOV PAT PSE36 CLFSH DS ACPI MMX FXSR SSE SSE2 SS HTT TM PBE SSE3 PCLMULQDQ DTES64 MON DSCPL VMX EST TM2 SSSE3 FMA CX16 TPR PDCM SSE4.1 SSE4.2 x2APIC MOVBE POPCNT AES PCID XSAVE OSXSAVE SEGLIM64 TSCTMR AVX1.0 RDRAND F16C
当然存在SSE,SSE2,SSE4.1,SSE4.2,AVX1.0,但此处没有AVX2。 但是,由于CPU可能支持AVX2,因此以下命令中出现的指令似乎可以通过提供特殊的编译器选项来使用它。
$ sysctl -a | grep machdep.cpu.leaf7_features machdep.cpu.leaf7_features: SMEP ERMS RDWRFSGS TSC_THREAD_OFFSET BMI1 AVX2 BMI2 INVPCID SMAP RDSEED ADX IPT SGX FPU_CSDS MPX CLFSOPT
事实证明,可以通过提供一些编译器选项来使用AVX2。 根据文章,gcc可以使用-mavx2选项。
$ gcc -o avx2 -mavx2 -Wall main.c $ ./avx2 source: ( 1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0) dest. : ( 1.1, 2.1, 3.1, 4.1, 5.1, 6.1, 7.1, 8.1) result: ( 2.1, 4.1, 6.1, 8.1, 10.1, 12.1, 14.1, 16.1)
参考:
SSE图像算法优化系列十一:使用FFT变换实现图像卷积。(系列文章都不错)
Optimizing Go programs by AVX2 using Auto-Vectorization in LLVM.