from sklearn.datasets import load_boston
boston=load_boston()
x=boston.data
y=boston.target
x.shape
from sklearn.preprocessing import PolynomialFeatures
poly=PolynomialFeatures(degree=2)#多项式的度 度越小曲线越平滑
x_poly=poly.fit_transform(x)#先拟合数据,然后转化它将其转化为标准形式
print(x_poly.shape)
#
from sklearn.linear_model import LinearRegression
ip=LinearRegression()
ip.fit(x_poly,y)
y_poly_pred=ip.predict(x_poly)
import matplotlib.pyplot as plt
plt.plot(y,y,'r')
plt.scatter(y,y_poly_pred)
plt.show()
print(ip.coef_.shape)#coef线性表达
# 一元多项式回归模型,建立一个变量与房价之间的预测模型,并图形化显示。
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
x_poly = poly.fit_transform(x)
lrp = LinearRegression()
lrp.fit(x_poly,y)
y_poly_pred = lrp.predict(x_poly)
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
x_poly = poly.fit_transform(x)
lrp = LinearRegression()
lrp.fit(x_poly,y)
plt.scatter(x,y)
plt.scatter(x,y_pred)
plt.scatter(x,y_poly_pred) #多项回归
plt.show()
with open(r'd:\stopsCN.txt', encoding='utf-8') as f:
stopwords = f.read().split('
')
import jieba
import os
import codecs#转码包
path=r"D:�369"
wenjianlujing=[]
wenjianneirong=[]
wenjianleibie=[]
# fs=os.listdir(path)
for root, dirs, files in os.walk(path):
print(root)
print(dirs)
print(files)
for name in files:
filePath = os.path.join(root, name)
wenjianlujing.append(filePath)
wenjianleibie.append(filePath.split('\')[2])
f = codecs.open(filePath, 'r', 'utf-8')
fc = f.read()
fc = fc.replace('
','')
tokens = [token for token in jieba.cut(fc)]#用jieba所设置的占位符来划分数据
tokens = " ".join([token for token in tokens if token not in stopwords])#添加成string
f.close()
wenjianneirong.append(tokens)
import pandas;
all_datas = pandas.DataFrame({
'wenjianneirong': wenjianneirong,
'wenjianleibie': wenjianleibie
})
str=''#将所有list合并成string
for i in range(len(wenjianneirong)):
str+=wenjianneirong[i]
#TF-IDF算法
#统计词频
import jieba.analyse
keywords = jieba.analyse.extract_tags(str, topK=20, withWeight=True, allowPOS=('n','nr','ns'))
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
#划分数据集
x_train,x_test,y_train,y_test = train_test_split(wenjianneirong,wenjianleibie,test_size=0.3,random_state=0,stratify=wenjianleibie)
print(len(wenjianneirong),len(x_train),len(x_test))
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
#划分数据集
x_train,x_test,y_train,y_test = train_test_split(wenjianneirong,wenjianleibie,test_size=0.3,random_state=0,stratify=wenjianleibie)
print(len(wenjianneirong),len(x_train),len(x_test))
x_train
#向量化
vectorizer = TfidfVectorizer()
x_train = vectorizer.fit_transform(x_train)
x_test = vectorizer.transform(x_test)
#数据建模
clf= MultinomialNB().fit(X_train,y_train)
y_nb_pred=clf.predict(X_test)
#分类结果,混淆矩阵
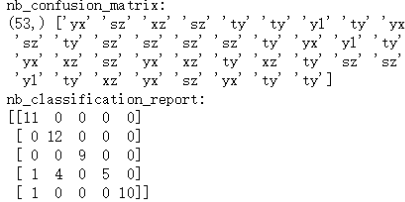
print(y_pred.shape,y_pred)
print('nb_confusion_matrix:')
cm=confusion_matrix(y_test,y_pred)
print(cm)
print('nb_classification_report:')
cr=classification_report(y_test,y_pred)
print(cr)