数据清理第一步:整体数据查看
一、查看识别变量--isid、duplicates
一般而言,每个数据集都有唯一一个识别每条记录的识别符(重复测量的长型数据除外)。Stata检查唯一识别符是否唯一的命令为isid(或许是is this an ID的缩写)。isid允许同时检查多个唯一识别符,如果没有返回值,就说明是唯一的(没有消息就是好消息);如果不唯一,就会出现红色提示variable *** does not uniquely identify the observations。如采用下面例子中的查重方式:
isid company //检查company是否唯一 isid company year //检查company year 是否唯一
如果出现重复记录就需要详细查看重复记录的情况,深入检查数据集重复记录的Stata命令为duplicates,对应的Stata菜单操作方式为Data → Data utilities → Manageduplicate observations。Stata是这样描述duplicates命令的:duplicates命令用来报告、查看、标示和删除重复记录。具体应用,大家可以在Stata软件命令栏中输入help duplicates查看。
bys symbol: gen filter=_n //对相同id的数据从1到最后一条编号 keep if filter == 1
duplicates drop year stkcd,force
*这一段代码可以删除重复的观测
sort date symbol
by date symbol : gen set=_n //证券代码和date相同则编号:从1到 最后
keep if set==1 //date 和 证券代码相同的观测,只保留了一条记录
drop set
save mystockdata_dropreplicate,replace
数据清理第二步:变量清理
一、缺失值的识别与处理
命令1:misstable
命令misstable可以快速查看变量的缺失值,它会以表格的形式呈现数据缺失的样本量,该命令的语法结构为:
misstable summarize[varlist][if][in][, summarize_options]
运行命令misstable和选项all可以直接输出指定变量串中所有变量的缺失情况。如果变量本身没有缺失值,表格结果显示为空;由于misstable只能识别数值型变量的缺失值,无法识别字符型变量的缺失值,所以,对于字符型变量来说,表格结果显示为“(string variable)”。
命令2:nmissing
nmissing是第三方用户写的命令,该命令的语法结构为:
nmissing [varlist] [if exp] [in range] [, min(#) obs piasm trim]
运行命令nmissing不仅可以给出指定变量串中的数值型变量的缺失值的个数,还可以给出字符型变量的缺失值的个数。选项min(#)可以显示缺失值个数超过#的变量及其缺失值情况。
命令3:mdesc
命令mdesc也是一个查看变量缺失情况的第三方命令,它的语法结构为:
mdescvarlist [if] [in] [, abbreviate(#) any all none]
该命令可以识别数值型变量和字符型变量,它不仅可以查看变量缺失值的样本量,还可以看其分布。
对于数据中的异常值,我们通常的处理方式有以下几种:
方法一:直接删除----适合缺失值数量较小,并且是随机出现的,删除它们对整体数据影响不大的情况。
Stata会区分缺失值:数值型变量缺失以点(.)表示,字符型变量确实以双引号("")表示,不要与空字符型变量(“ ”)搞混。
drop if provincename=="" //删除字符型变量
列出有缺失值的变量,只要有任何一个变量缺失即为真,即各个判断之间是或(OR)的关系
list id dose gender age t0 t1 a1 a2 if id>=.| dose>=.|gender>=.| age>=.| t0>=.| t1>=.| a1>=.| a2>=.
foreach var of varlist id-a2 {# v1 ~7 W9 x; F: ^( A list id-a2 if missing(`var')( t7 r; F3 w: A: S& t0 N0 |( e/ w };
方法二:使用一个全局常量填充---譬如将缺失值用“Unknown”等填充,但是效果不一定好,因为算法可能会把它识别为一个新的类别,一般很少用。
方法三:使用均值或中位数代替----优点:不会减少样本信息,处理简单。缺点:当缺失数据不是随机数据时会产生偏差.对于正常分布的数据可以使用均值代替,如果数据是倾斜的,使用中位数可能更好。
方法四:插补法
1)随机插补法----从总体中随机抽取某个样本代替缺失样本
2)多重插补法----通过变量之间的关系对缺失数据进行预测,利用蒙特卡洛方法生成多个完整的数据集,在对这些数据集进行分析,最后对分析结果进行汇总处理
3)热平台插补----指在非缺失数据集中找到一个与缺失值所在样本相似的样本(匹配样本),利用其中的观测值对缺失值进行插补。这样做的优点是:简单易行,准去率较高。缺点:变量数量较多时,通常很难找到与需要插补样本完全相同的样本。但我们可以按照某些变量将数据分层,在层中对缺失值实用均值插补
4)拉格朗日差值法和牛顿插值法(简单高效,数值分析里的内容)
方法五:建模法
可以用回归、使用贝叶斯形式化方法的基于推理的工具或决策树归纳确定。例如,利用数据集中其他数据的属性,可以构造一棵判定树,来预测缺失值的值。
以上方法各有优缺点,具体情况要根据实际数据分分布情况、倾斜程度、缺失值所占比例等等来选择方法。一般而言,建模法是比较常用的方法,它根据已有的值来预测缺失值,准确率更高。
三、异常值的识别与处理
异常值(outlier)是指一组测定值中与平均值的偏差超过两倍标准差的测定值,与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。通常面对样本时需要做整体数据观察,以确认样本数量、均值、极值、方差、标准差以及数据范围等。其中的极值很可能是异常值,此时如何处理异常值会直接影响数据结果。那么我们在Stata中应该如何识别异常值呢?
方法一:简单的统计分析
拿到数据后可以对数据进行一个简单的描述性统计分析,譬如最大最小值可以用来判断这个变量的取值是否超过了合理的范围,如客户的年龄为-20岁或200岁,显然是不合常理的,为异常值。这种方法我们可以在Stata中summarize命令来实现。summarize命令用来计算及展示一组单变量的概要统计,若后面不指定变量,则计算当前数据集中所有变量的概要统计。若觉得某个变量的极值不符合常识,可选择detail选项,则显示变量的额外统计量,包括skewness、kurtosis、4个最小值、4个最大值,以及各种百分比。这就很容易以查看极值找到异常值。
二:简单画图
也可以在Stata中采用scatter命令,通过画散点图的方法,直接观察是否存在异常值。
方法三:箱形图
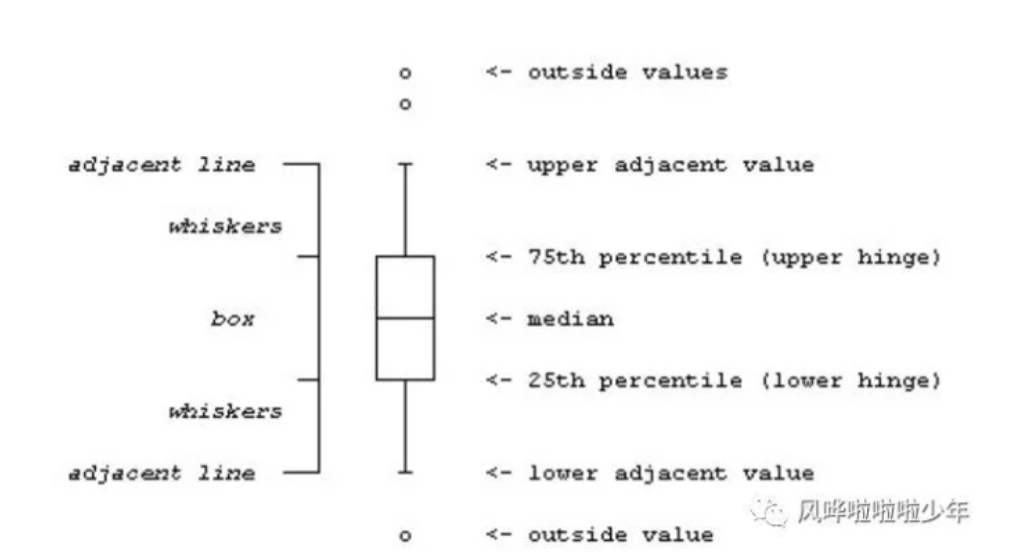
box图分为四个分位点,75th和25th比较简单。
上四分位数Q3,又叫做升序数列的75%位点
下四分位数Q1,又叫做升序数列的25%位点
箱式图检验就是摘除大于Q3+3/2*(Q3-Q1),小于Q1-3/2*(Q3-Q1)外的数据,并认定其为异常值;
这里的具体操作过程,可以查看Stata中的graph box命令来更多了解。
方法四:3δ原则
当数据服从正态分布:根据正态分布的定义可知,距离平均值3δ之外的概率为 P(|x-μ|>3δ) <= 0.003 ,这属于极小概率事件,在默认情况下我们可以认定,距离超过平均值3δ的样本是不存在的。因此,当样本距离平均值大于3δ,则认定该样本为异常值。
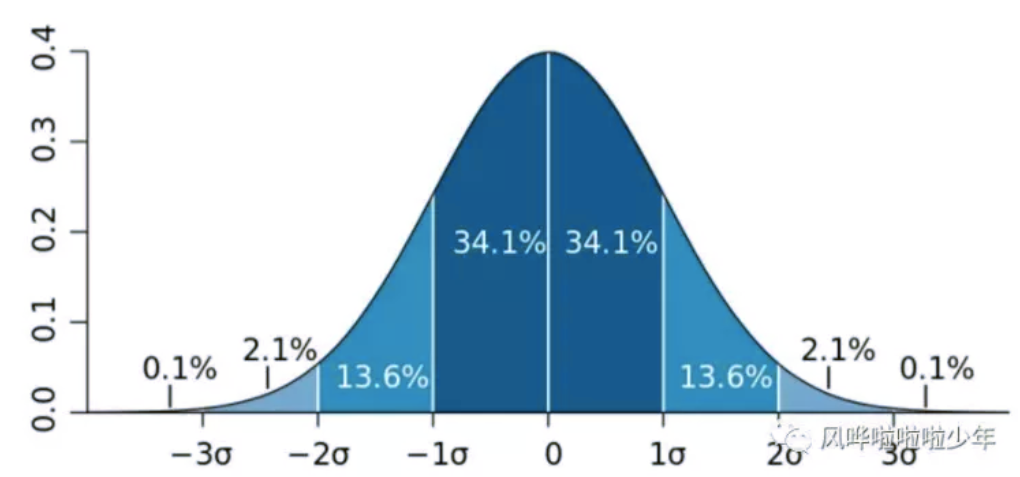
当数据不服从正态分布:当数据不服从正态分布,可以通过远离平均距离多少倍的标准差来判定,多少倍的取值需要根据经验和实际情况来决定。
那么在stata中我们如何处理这些异常值呢?
方法一:直接删除
这只一种非常粗暴的方法。由于异常值对于统计推断的影响巨大,这种做法目前已经不多采用了,尤其当样本量规模不大甚至比较小的时候。当然如果数据量样本足够大而异常值并不多的情况下,慎行。
方法二:替换成均值或者中位数
这是一种非常偷懒的做法,如果是做回归那么就在回归时改成用中位数回归,不过这也确实是一种很不错的办法。
方法三:将异常值视为缺失值,交给缺失值处理方法来处理
缺失值的处理方式本文前面已经详细介绍,在此不再赘述。
方法四:winsorize命令
winsorize是用相应分位数的值替代分位数之外的值,而不是删掉,这样可以最大限度的保存数据信息。主要是根据已有文献来的,如果别人用winsorize你也要用,否则你的结论和别人的没有可比性。目前来看,至少在金融领域,使用winsorize比较普遍,删除异常值的做法越来越少的被使用了。Stata中有现成的winsorize程序,打开Stata,在命令行输入ssc install winsor2,replace,自动安装 winsor2。安装完之后,winsor2命令的基本格式为:
winsor2 变量名 变量名, replace cuts(1 99)
p()里的数字可以自己设,一般是0.01。当然,0.01就是在1%的异常变量,也可以设定5%,就是p里面写成0.05。这个命令把最高1%和最低1%替换成离他们最近的值,不删除或变成缺失。
这个命令也可以将识别出来的异常值直接删除,命令形式如下:
winsor2 变量名 变量名, replace cuts(199) trim
这里插一句:数据清理永无止境,需要不断反复,有时候觉得数据很干净了,没问题了,过一段时间之后还是会发现一些小错误,有的能被修正过来,而有的只能保持错误状态。这个世界上很难找到完美的调查和数据,因此每次做清理时都要假定这个变量有问题,而不是这个变量没问题。
经过上面那么多道程序之后,你是否觉得自己拿到手的数据(比如CGSS、CHNS、CFPS、CHIPS等等)已经可以做回归分析了?这里只能说相当抱歉!真的还差得远!如果真的要采用这些数据进行回归,你可能还要经历一下的过程:
数据清理第三步:一些更为深入的工作
在这里,我们以CHNS数据为例,在进行完前两步的工作之后,对接下来个的工序进行详细解释。CHNS调查数据是中国疾病预防控制中心营养与食品安全所(原中国预防医学科学院营养与食品卫生研究所)与美国北卡罗来纳大学人口中心合作的追踪调查项目,其目的在于探讨中国社会的经济转型和计划生育政策的开展对国民健康和营养状况的影响。该调查始于1989年,到目前为止共进行了十次,包括1989、1991、1993、1997、2000、2004、2006、2009、2011、2015年数据。范围覆盖了9个省的城市和农村地区,内容涉及人口特征,经济发展、公共资源和健康指标。除此之外,还有详细的社区数据,包括食品市场、医疗机构和其他社会服务设施的信息。目前CHNS数据上面这些优点使得CHNS具有独特的应用价值。该调查采用多阶段分层整群随机抽样方法。为了理清接下来的数据处理过程,我们可能还需要知道:
一、首先明确,所研究的问题是否需要一个真正的长期面板
在数据调研过程中,样本丢失是一种非常常见的现象。比如原样本家庭访户的去世,原企业在原有领域的退出等等。然而依据我们所要研究的主题的差异,我们需要对数据样本进行选择。如果只是研究X与Y之间的因果性问题,那么所有样本可用。而如果要研究样本某个特征的长期趋势,那么我们可能需要只研究数据库中存在的长期样本。比如刘志军(2017)中的研究主题是收入流动性的长期趋势,那么他便在在所有调查的样本数据中,只保留有长期追踪调查的样本,根据研究的需要构造三个平衡面板数据。一是1989-2000年期间含有在9个调查年份中同时都出现的样本量;二是1989-2000年期间同时含有5个调查年份数据;三是2000-2011年期间同时含有所有5个调查年份数据。
二、需要用权重对长周期调查中的数据磨损加以调整
每个数据库在数据调查过程中,都采用了特定的抽样方法,如CHNS采用的是多阶段分层整群随机抽样方法。这里对于不同的地区和样本进行了权重赋予,因此我们在重新使用过程中,需要利用这些权重对调查出的数据进行重新调整,以保证数据的随机性。这一过程是当下很多研究者没有进行的程序,但是实际上不进行真的是不行的。
在进行完上面的过程之后,我们的数据已经基本能用了,但是如果研究的主题是样本某特征的长期趋势,我们可能还要进行下一步工作:
三、如果有余力,可以将调查缺失年份的数据补齐
很多数据库的调查年份的间隔并不是等距的,中间可能有多少一两年的差别。这时候为了能够更好地反映样本某特征的长期演化趋势,可以进一步我们采取一种方法将非调查年度的某特征数据补充完整:首先根据期初和期末收入计算出在此时间跨度中的每个样本i的年均收入增长速度g;接着再利用前一轮次的调查数据和增长速度计算缺失年份的数据来补充数据有助于反映某特征数据的全貌。
总结:以上便是本人在学习过程中了解到的数据清理过程,分享给大家,欢迎批评指正,互相进步。另外,在学习与研究的初级阶段,数据清理大致占据了论文写作整体过程70%-80%的时间,可谓费时费力,希望大家不辞辛劳,咬牙坚持住;数据清理是论文写作的第一步,加油吧,不要吝惜自己去 dirty your hands,你会收货颇丰的,加油!共勉O(∩_∩)O哈哈~