
原文链接:http://www.cnblogs.com/xhb-bky-blog/p/9051380.html
导图
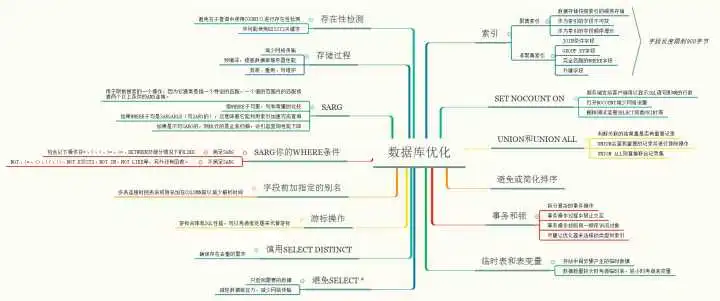
下图是我结合自己的经验以及搜集整理的数据库优化相关内容的思维导图。
常用关键字优化
在编写T-SQL的时候,会使用很多功能类似的关键字,比如COUNT和EXISTS、IN和BETWEEN AND等,我们往往会根据需求直奔主题地来编写查询脚本,完成需求要求实现的业务逻辑即可,但是,我们编写的脚本中却存在着很多的可优化的空间。
EXISTS代替COUNT或IN
不要在子查询中使用COUNT()执行存在性检查,不要使用类似于如下这样的语句:
SELECT COLUMN_LIST FROM TABLENAME WHERE 0 < (SELECT COUNT(*) FROM TABLE2 WHERE ..)
而应该采用这样的语句代替:
SELECT COLUMN_LIST FROM TABLENAME WHERE EXISTS(SELECT COLUMN_LIST FROM TABLE2 WHERE ...)
当你使用COUNT()时,SQL SERVER不知道你要做的是存在性检查,它会计算所有匹配的值,要么会执行全表扫描,要么会扫描最小的非聚集索引。当你使用EXISTS时,SQL SERVER知道你要执行存在性检查,当它发现第一个匹配的值时,就会返回TRUE,并停止查询。此外,很多时候用EXISTS代替IN是一个好的选择,例如:
SELECT NUM FROM A WHERE NUM IN (SELECT NUM FROM B) 可以使用SELECT NUM FROM A WHERE EXISTS (SELECT 1 FROM B WHERE NUM=A.NUM)进行替代。
尽量不用 SELECT
绝大多数情况下,不要用 *来代替查询返回的字段列表,用 *的好处是代码量少,就算是表结构或视图的列发生变化,编写的查询SQL语句也不用变,都返回所有的字段。但数据库服务器在解析时,如果碰到 *,则会先分析表的结构,然后把表的所有字段名再罗列出来,这就增加了分析的时间。另一个问题是,SELECT *可能包含了不需要的列,增加了网络流量。如果在视图创建中使用了SELECT *,在后期如果有对视图基表的表结构进行了更改,当查询视图时,可能会生成意外结果,除非重建视图或利用SP_REFRESHVIEW更新视图的元数据。
慎用 SELECT DISTINCT
DISTINCT子句仅在特定功能的时候使用,即从记录集中排除重复记录的时候。这是因为DISTINCT子句先获取结果,进行排序集然后再去重,这样增加了SQL SERVER资源的消耗。在实际的业务中,如果你已经预先知道SELECT语句将从不返回重复记录,那么使用DISTINCT语句是对SQL SERVER资源不必要的浪费。当然,如果是符合特定的业务场景,是可以酌情使用的。
正确使用 UNION 和 UNION ALL 以及 WITH TEMPTABLENAME AS
许多人没完全理解UNION和UNION ALL是怎样工作的,因此,结果浪费了大量不必要的SQL Server资源。当使用UNION时,它相当于在结果集上执行SELECT DISTINCT。换句话说,UNION将联合两个相类似的记录集,然后搜索重复的记录并排除。如果这是你的目的,那么使用UNION是正确的。但如果你使用UNION联合的两个记录集本身就没有重复记录,那么使用UNION会浪费资源,因为它要寻找重复记录,即使你确定它们不存在。总而言之,联合无重复的结果集采用UNION ALL,联合存在重复记录的采用UNION。对于WITH TEMP TABLENAME AS,其实并没有建立临时表,只是子查询部分(SUBQUERY FACTORING),定义一个SQL片断,该SQL片断会被整个SQL语句所用到。有的时候,是为了让SQL语句的可读性更高些,也有可能是在UNION ALL的不同部分,作为提供数据的部分。特别对于UNION ALL比较有用。因为UNION ALL的每个部分可能相同,但是如果每个部分都去执行一遍的话成本太高,所以可以使用WITH AS短语,则只要执行一遍即可。
使用 SET NOCOUNT ON 选项
缺省地,每次执行SQL语句时,一个消息会从服务端发给客户端以显示SQL语句影响的行数。这些信息对客户端来说很少有用,甚至有些客户端会把这些信息当成错误信息处理。通过关闭这个缺省值,你能减少在服务端和客户端的网络流量,帮助全面提升服务器和应用程序的性能。为了关闭存储过程级的这个特点,在每个存储过程的开头包含SET NOCOUNT ON语句。同样,为减少在服务端和客户端的网络流量,生产环境中应该去掉存储过程中那些在调试过程中使用的SELECT和PRINT语句。
指定字段别名
当在SQL语句中连接多个表时,可以将表名或别名加到每个COLUMN前面,这样可以有效地减少解析的时间并减少那些由COLUMN歧义引起的语法错误。例如:
SELECT COLUMN_A,COLUMN_B FROM TABLE1 T1 INNER JOIN TABLE2 T2 ON T1.ID = T2.UID,其中COLUMN_A是TABLE1的数据列,COLUMN_B是TABLE2的数据列,这并不妨碍查询的进行,但是改成下列语句是不是更好呢?SELECT T1.COLUMN_A,T2.COLUMN_B FROM TABLE T1 INNER JOIN TABLE T2 ON T1.ID = T2.UID
建立索引
关于索引,下图展示出了索引的直观结构:

索引按照索引的类型可以分为聚集索引和非聚集索引,一张数据表只能存在一个聚集索引,但可以建立若干非聚集索引,聚集索引通常是建立在主键上,当然主键上不一定需要强制建立聚集索引。关于索引的实现原理可以参考这篇篇,以及。对于聚集索引而言,表中存储的数据按照索引的顺序存储,即逻辑顺序决定了表中相应行的物理顺序。对于非聚集索引,一般考虑在下列情形下使用非聚集索引:使用JOIN的条件字段、使用GROUP BY的字段、完全匹配的WHERE条件字段、外键字段等等。索引是有900字节大小限制的,因此不要在超长字段上建立索引,索引字段的总字节数不要超过900字节,否则插入的数据达到900字节时会报错。另外,并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段Gender,Male、Female几乎各一半,那么即使在Gender上建了索引也对查询效率起不了作用。索引并不是越多越好,索引固然可以提高查询效率,但同时也降低了插入数据及更新数据的效率,因为插入或更新数据时有可能会重建索引,所以在建立索引时需要慎重考虑,视具体情况而定。总之,要根据实际的业务情景合理地为数据表建立索引。
存储过程
存储过程是数据库中的一个重要对象。存储过程实际上是对一些SQL脚本的有逻辑地组合而形成的,是一组为了完成特定功能的SQL 语句集。存储在数据库中,经过第一次编译后再次调用不需要再次编译,所以使用存储过程可提高数据库执行速度,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程执行计划能够重用,驻留在SQL SERVER内存的缓存里,减少服务器开销。当业务相对复杂的时候,可以将该业务封装成一个存储过程存储在数据库服务器,可以大大降低网络流量的传输,提高性能。例如,通过网络发送一个存储过程调用,而不是发送500行的T-SQL,这样速度会更快,资源占用更少,有效地避免了每次执行SQL时,都会执行解析SQL语句、估算索引的利用率、绑定变量、读取数据块等工作。存储过程可有效地降低数据库连接次数,当对数据库进行复杂操作时(如对多个表进行 Update,Insert,Query,Delete操作时),可将该复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。这些操作,如果用程序来完成,就变成了一条条的 SQL 语句,可能要多次连接数据库。而采用成存储过程,只需要连接一次数据库就可以了。
事务和锁
事务是数据库应用中重要的工具,它具有原子性、一致性、隔离性、持久性这四个属性,很多操作我们都需要利用事务来保证数据的正确性。在使用事务中我们需要做到尽量避免死锁、尽量减少阻塞。开发过程中,可以通过以下几种方式来避免问题的产生:事务操作过程要尽量小,能拆分的事务要拆分开来,在更细的粒度上应用事务;事务操作过程中不应该有交互,因为交互等待的时候,事务并未结束,可能锁定了很多资源;事务操作过程要按同一顺序访问对象,比如在某一事务中要按顺序更新A、B两表,那么在其他的事务中就不要按B、A的顺序去更新这两个表。我在实际工作中就遇到过这种问题(如下图所示),由于在事务中需要同时更新主表和子表,子表的数据更新后主表汇总数据,但是更新两个表的时候,顺序不一致,由于事务的原子性,需要在同一事务中完成两表的更新操作,这就形成了Transaction A需要的资源(子表B)被Transaction B占据着,Transaction B需要的资源(主表A)被Transaction A占据着,导致表被锁住,造成了死锁,后来对表的更新顺序进行了调整,解决了这个问题。尽量不要指定锁类型和索引,SQL SERVER允许我们自己指定语句使用的锁类型和索引,但是一般情况下,SQL SERVER优化器选择的锁类型和索引是在当前数据量和查询条件下是最优的,我们指定的可能只是在目前情况下更优,但是数据量和数据分布在将来是会变化的。
 SARG WHERE条件
SARG WHERE条件
下面是百度百科对SARG的解释:
SARG (Searchable Arguments)操作,用于限制搜索的一个操作,它通常是指一个特定的匹配,一个值的范围内的匹配或者两个以上条件的AND连接。
SARG来源于Search Argument(搜索参数)的首字母拼成的SARG,它是指WHERE子句里,列和常量的比较。如果WHERE子句是SARGABLE(可SARG的),这意味着它能利用索引加速查询的完成。如果WHERE子句不是可SARG的,这意味着WHERE子句不能利用索引(或至少部分不能利用),执行的是全表或索引扫描,这会引起查询的性能下降。
在WHERE子句中,可以SARG的搜索条件包含以下如:包含以下操作符=、>、<、>=、<=、BETWEEN及部分情况下的LIKE(通配符在查询关键字之后,如LIKE 'A%')
在WHERE子句中,不可SARG的搜索条件如:IS NULL, <>, !=, !>, !<, NOT, NOT EXISTS, NOT IN, NOT LIKE和LIKE '%500',通常(但不总是)会阻止查询优化器使用索引执行搜索。另外在列上使用包括函数的表达式、两边都使用相同列的表达式、或和一个列(不是常量)比较的表达式,都是不可SARG的。并不是每一个不可SARG的WHERE子句都注定要全表扫描。如果WHERE子句包括两个可SARG和一个不可SARG的子句,那么至少可SARG的子句能使用索引(如果存在的话)帮助快速访问数据。
大多数情况下,如果表上有包括查询里所有SELECT、JOIN、WHERE子句用到的列的覆盖索引,那么覆盖索引能够代替全表扫描去返回查询的数据,即使它有不可SARG的WHERE子句。某些情况下,可以把不可SARG的WHERE子句重写成可SARG的子句。例如:
WHERE SUBSTRING(FirstName,1,1) = 'M'可以写成:WHERE FirstName LIKE 'M%' 这两个WHERE子句有相同的结果,但第一个是不可SARG的(因为使用了函数)将运行得慢些,而第二个是可SARG的,将运行得快些。如果你不知道特定的WHERE子句是不是可SARG的,可以在查询分析器里检查查询执行计划。这样做,你能很快地知道查询是使用了索引还是全表扫描来返回的数据。仔细分析,许多不可SARG的查询能写成可SARG的查询,从而实现性能的优化和提升。
查询条件中使用了不等于操作符(<>, !=)的SELECT语句执行效率较低,因为不等于操作符会限制索引,引起全表扫描,即使被比较的字段上有索引,这时可以通过把不等于操作符改成OR,可以使用索引,从而避免全表扫描。例如, 可以把SELECT TOP 100 AGE FROM TABLE WHERE AGE <> 25改写为SELECT TOP 1000 AGE FROM TABLE WHERE AGE > 25 OR AGE < 25
应当尽量避免在WHERE子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。例如:SELECT ID FROM TABLE WHERE SUBSTRING(NAME, 1, 3) = 'ABC'
临时表和表变量
在复杂系统中,如果业务是以存储过程的方式组织的,那么中间必然会产生一些临时查询出的数据,此时临时表和表变量很难避免,关于临时表和表变量的用法,需要注意的是,如果语句很复杂,连接太多,可以考虑用临时表和表变量分步完成,将需要的结果集存储在临时表或表变量中,便于复用;同样地,如果需要多次用到一个大表的同一部分数据,考虑用临时表和表变量暂存这部分数据;如果需要综合多个表的数据,形成一个结果集,可以考虑用临时表和表变量分步汇总出这多个表的数据;其他情况下,应该控制临时表和表变量的使用。另外,在临时表完成自身功能后,要显式地删除临时表,先TRUNCATE TABLE,然后DROP TABLE,以避免资源的占用。关于临时表和表变量的选择,很多说法是表变量储存在内存,速度快,应该首选表变量,但是在实际使用中发现,这个选择主要是考虑需要放在临时表中的数据量,在数据量较多的情况下,临时表的速度反而更快。关于临时表的创建,使用SELECT INTO和CREATE TABLE + INSERT INTO的选择,我们做过测试,一般情况下,SELECT INTO会比CREATE TABLE + INSERT INTO的方法快很多,但是SELECT INTO会锁定TEMPDB的系统表SYSOBJECTS、SYSINDEXES、SYSCOLUMNS,在多用户并发环境下,容易阻塞其他进程,所以建议在并发系统中,尽量使用CREATE TABLE + INSERT INTO,而大数据量的单个语句使用中,使用SELECT INTO。
临时表和表变量是有区别的,表变量是存储在内存中的,当用户在访问表变量的时候,SQL SERVER是不产生日志的,而在临时表中是产生日志的;在表变量中,是不允许有非聚集索引的;表变量是不允许有DEFAULT默认值,也不允许有约束;临时表上的统计信息是健全而可靠的,但是表变量上的统计信息是不可靠的;临时表中是有锁的机制,而表变量中就没有锁的机制。了解二者的区别,可以针对特定场景选择最优方案,使用表变量主要需要考虑的就是应用程序对内存的压力,如果代码的运行实例很多,就要特别注意内存变量对内存的消耗。对于较小的数据或者是通过计算出来的数据推荐使用表变量。如果数据的结果比较大,在代码中用于临时计算,在选取的时候没有什么分组或聚合,也可以考虑使用表变量。一般对于大的数据结果集,或者因为统计出来的数据为了便于更好的优化,我们就推荐使用临时表,同时还可以创建索引,由于临时表是存放在Tempdb中,一般默认分配的空间很少,需要对Tempdb进行调优,增大其存储的空间。
结语
本篇博文对常用的数据库优化方法进行了简单的梳理和总结,如果文中有不正确或者不恰当的地方,欢迎提出质疑,共同讨论共同进步,如果您有什么更好的优化方案,可以在评论区讨论,我会把这些优化方案补充进来。如果您觉得有帮助,点个赞哟~
声明:本博客原创文字只代表本人工作中在某一时间内总结的观点或结论,与本人所在单位没有直接利益关系。非商业,未授权贴子请以现状保留,转载时必须保留此段声明,且在文章页面明显位置给出原文连接。