大数据技术之电商用户行为分析
第1章 项目整体介绍
1.1 电商的用户行为
电商平台中的用户行为频繁且较复杂,系统上线运行一段时间后,可以收集到大量的用户行为数据,进而利用大数据技术进行深入挖掘和分析,得到感兴趣的商业指标并增强对风险的控制。
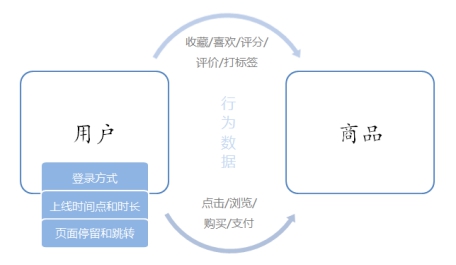
电商用户行为数据多样,整体可以分为用户行为习惯数据和业务行为数据两大类。用户的行为习惯数据包括了用户的登录方式、上线的时间点及时长、点击和浏览页面、页面停留时间以及页面跳转等等,我们可以从中进行流量统计和热门商品的统计,也可以深入挖掘用户的特征;这些数据往往可以从web服务器日志中直接读取到。而业务行为数据就是用户在电商平台中针对每个业务(通常是某个具体商品)所作的操作,我们一般会在业务系统中相应的位置埋点,然后收集日志进行分析。业务行为数据又可以简单分为两类:一类是能够明显地表现出用户兴趣的行为,比如对商品的收藏、喜欢、评分和评价,我们可以从中对数据进行深入分析,得到用户画像,进而对用户给出个性化的推荐商品列表,这个过程往往会用到机器学习相关的算法;另一类则是常规的业务操作,但需要着重关注一些异常状况以做好风控,比如登录和订单支付。
1.2 项目主要模块
基于对电商用户行为数据的基本分类,我们可以发现主要有以下三个分析方向:
1. 热门统计
利用用户的点击浏览行为,进行流量统计、近期热门商品统计等。
2. 偏好统计
利用用户的偏好行为,比如收藏、喜欢、评分等,进行用户画像分析,给出个性化的商品推荐列表。
3. 风险控制
利用用户的常规业务行为,比如登录、下单、支付等,分析数据,对异常情况进行报警提示。
本项目限于数据,我们只实现热门统计和风险控制中的部分内容,将包括以下四大模块:实时热门商品统计、实时流量统计、恶意登录监控和订单支付失效监控。

由于对实时性要求较高,我们会用flink作为数据处理的框架。在项目中,我们将综合运用flink的各种API,基于EventTime去处理基本的业务需求,并且灵活地使用底层的processFunction,基于状态编程和CEP去处理更加复杂的情形。
1.3 数据源解析
我们准备了一份淘宝用户行为数据集,保存为csv文件。本数据集包含了淘宝上某一天随机一百万用户的所有行为(包括点击、购买、收藏、喜欢)。数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
|
字段名 |
数据类型 |
说明 |
|
userId |
Long |
加密后的用户ID |
|
itemId |
Long |
加密后的商品ID |
|
categoryId |
Int |
加密后的商品所属类别ID |
|
behavior |
String |
用户行为类型,包括(‘pv’, ‘’buy, ‘cart’, ‘fav’) |
|
timestamp |
Long |
行为发生的时间戳,单位秒 |
另外,我们还可以拿到web服务器的日志数据,这里以apache服务器的一份log为例,每一行日志记录了访问者的IP、userId、访问时间、访问方法以及访问的url,具体描述如下:
|
字段名 |
数据类型 |
说明 |
|
ip |
String |
访问的 IP |
|
userId |
Long |
访问的 user ID |
|
eventTime |
Long |
访问时间 |
|
method |
String |
访问方法 GET/POST/PUT/DELETE |
|
url |
String |
访问的 url |
由于行为数据有限,在实时热门商品统计模块中可以使用UserBehavior数据集,而对于恶意登录监控和订单支付失效监控,我们只以示例数据来做演示。
第2章 实时热门商品统计
首先要实现的是实时热门商品统计,我们将会基于UserBehavior数据集来进行分析。
项目主体用Scala编写,采用IDEA作为开发环境进行项目编写,采用maven作为项目构建和管理工具。首先我们需要搭建项目框架。
2.1 创建Maven项目
2.1.1 项目框架搭建
打开IDEA,创建一个maven项目,命名为UserBehaviorAnalysis。由于包含了多个模块,我们可以以UserBehaviorAnalysis作为父项目,并在其下建一个名为HotItemsAnalysis的子项目,用于实时统计热门top N商品。
在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为HotItemsAnalysis。
父项目只是为了规范化项目结构,方便依赖管理,本身是不需要代码实现的,所以UserBehaviorAnalysis下的src文件夹可以删掉。
2.1.2 声明项目中工具的版本信息
我们整个项目需要的工具的不同版本可能会对程序运行造成影响,所以应该在最外层的UserBehaviorAnalysis中声明所有子模块共用的版本信息。
在pom.xml中加入以下配置:
UserBehaviorAnalysis/pom.xml
|
<properties> <scala.binary.version>2.11</scala.binary.version> |
2.1.3 添加项目依赖
对于整个项目而言,所有模块都会用到flink相关的组件,所以我们在UserBehaviorAnalysis中引入公有依赖:
UserBehaviorAnalysis/pom.xml
|
<dependencies> <dependency> <artifactId>kafka_${scala.binary.version}</artifactId> <version>${kafka.version}</version> </dependencies> |
同样,对于maven项目的构建,可以引入公有的插件:
|
<build> jar-with-dependencies </descriptorRef> |
在HotItemsAnalysis子模块中,我们并没有引入更多的依赖,所以不需要改动pom文件。
2.1.4 数据准备
在src/main/目录下,可以看到已有的默认源文件目录是java,我们可以将其改名为scala。将数据文件UserBehavior.csv复制到资源文件目录src/main/resources下,我们将从这里读取数据。
至此,我们的准备工作都已完成,接下来可以写代码了。
2.2 模块代码实现
我们将实现一个“实时热门商品”的需求,可以将“实时热门商品”翻译成程序员更好理解的需求:每隔5分钟输出最近一小时内点击量最多的前N个商品。将这个需求进行分解我们大概要做这么几件事情:
• 抽取出业务时间戳,告诉Flink框架基于业务时间做窗口
• 过滤出点击行为数据
• 按一小时的窗口大小,每5分钟统计一次,做滑动窗口聚合(Sliding Window)
• 按每个窗口聚合,输出每个窗口中点击量前N名的商品
2.2.1 程序主体
在src/main/scala下创建HotItems.scala文件,新建一个单例对象。定义样例类UserBehavior和ItemViewCount,在main函数中创建StreamExecutionEnvironment 并做配置,然后从UserBehavior.csv文件中读取数据,并包装成UserBehavior类型。代码如下:
HotItemsAnalysis/src/main/scala/HotItems.scala
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timestamp: Long)
case class ItemViewCount(itemId: Long, windowEnd: Long, count: Long)
object HotItems {
def main(args: Array[String]): Unit = {
// 创建一个 StreamExecutionEnvironment
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 设定Time类型为EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 为了打印到控制台的结果不乱序,我们配置全局的并发为1,这里改变并发对结果正确性没有影响
env.setParallelism(1)
val stream = env
// 以window下为例,需替换成自己的路径
.readTextFile("YOUR_PATH\resources\UserBehavior.csv")
.map(line => {
val linearray = line.split(",")
UserBehavior(linearray(0).toLong, linearray(1).toLong, linearray(2).toInt, linearray(3), linearray(4).toLong)
})
// 指定时间戳和watermark
.assignAscendingTimestamps(_.timestamp * 1000)
env.execute("Hot Items Job")
}
这里注意,我们需要统计业务时间上的每小时的点击量,所以要基于EventTime来处理。那么如果让Flink按照我们想要的业务时间来处理呢?这里主要有两件事情要做。
第一件是告诉Flink我们现在按照EventTime模式进行处理,Flink默认使用ProcessingTime处理,所以我们要显式设置如下:
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
第二件事情是指定如何获得业务时间,以及生成Watermark。Watermark是用来追踪业务事件的概念,可以理解成EventTime世界中的时钟,用来指示当前处理到什么时刻的数据了。由于我们的数据源的数据已经经过整理,没有乱序,即事件的时间戳是单调递增的,所以可以将每条数据的业务时间就当做Watermark。这里我们用 assignAscendingTimestamps来实现时间戳的抽取和Watermark的生成。
注:真实业务场景一般都是乱序的,所以一般不用assignAscendingTimestamps,而是使用BoundedOutOfOrdernessTimestampExtractor。
.assignAscendingTimestamps(_.timestamp * 1000)
这样我们就得到了一个带有时间标记的数据流了,后面就能做一些窗口的操作。
2.2.2 过滤出点击事件
在开始窗口操作之前,先回顾下需求“每隔5分钟输出过去一小时内点击量最多的前N个商品”。由于原始数据中存在点击、购买、收藏、喜欢各种行为的数据,但是我们只需要统计点击量,所以先使用filter将点击行为数据过滤出来。
.filter(_.behavior == "pv")
2.2.3 设置滑动窗口,统计点击量
由于要每隔5分钟统计一次最近一小时每个商品的点击量,所以窗口大小是一小时,每隔5分钟滑动一次。即分别要统计[09:00, 10:00), [09:05, 10:05), [09:10, 10:10)…等窗口的商品点击量。是一个常见的滑动窗口需求(Sliding Window)。
.keyBy("itemId")
.timeWindow(Time.minutes(60), Time.minutes(5))
.aggregate(new CountAgg(), new WindowResultFunction());
我们使用.keyBy("itemId")对商品进行分组,使用.timeWindow(Time size, Time slide)对每个商品做滑动窗口(1小时窗口,5分钟滑动一次)。然后我们使用 .aggregate(AggregateFunction af, WindowFunction wf) 做增量的聚合操作,它能使用AggregateFunction提前聚合掉数据,减少state的存储压力。较之 .apply(WindowFunction wf) 会将窗口中的数据都存储下来,最后一起计算要高效地多。这里的CountAgg实现了AggregateFunction接口,功能是统计窗口中的条数,即遇到一条数据就加一。
// COUNT统计的聚合函数实现,每出现一条记录就加一
class CountAgg extends AggregateFunction[UserBehavior, Long, Long] {
override def createAccumulator(): Long = 0L
override def add(userBehavior: UserBehavior, acc: Long): Long = acc + 1
override def getResult(acc: Long): Long = acc
override def merge(acc1: Long, acc2: Long): Long = acc1 + acc2
}
聚合操作.aggregate(AggregateFunction af, WindowFunction wf)的第二个参数WindowFunction将每个key每个窗口聚合后的结果带上其他信息进行输出。我们这里实现的WindowResultFunction将<主键商品ID,窗口,点击量>封装成了ItemViewCount进行输出。
// 商品点击量(窗口操作的输出类型)
case class ItemViewCount(itemId: Long, windowEnd: Long, count: Long)
代码如下:
// 用于输出窗口的结果
class WindowResultFunction extends WindowFunction[Long, ItemViewCount, Tuple, TimeWindow] {
override def apply(key: Tuple, window: TimeWindow, aggregateResult: Iterable[Long],
collector: Collector[ItemViewCount]) : Unit = {
val itemId: Long = key.asInstanceOf[Tuple1[Long]].f0
val count = aggregateResult.iterator.next
collector.collect(ItemViewCount(itemId, window.getEnd, count))
}
}
现在我们就得到了每个商品在每个窗口的点击量的数据流。
2.2.4 计算最热门Top N商品
为了统计每个窗口下最热门的商品,我们需要再次按窗口进行分组,这里根据ItemViewCount中的windowEnd进行keyBy()操作。然后使用ProcessFunction实现一个自定义的TopN函数TopNHotItems来计算点击量排名前3名的商品,并将排名结果格式化成字符串,便于后续输出。
.keyBy("windowEnd")
.process(new TopNHotItems(3)); // 求点击量前3名的商品
ProcessFunction是Flink提供的一个low-level API,用于实现更高级的功能。它主要提供了定时器timer的功能(支持EventTime或ProcessingTime)。本案例中我们将利用timer来判断何时收齐了某个window下所有商品的点击量数据。由于Watermark的进度是全局的,在processElement方法中,每当收到一条数据ItemViewCount,我们就注册一个windowEnd+1的定时器(Flink框架会自动忽略同一时间的重复注册)。windowEnd+1的定时器被触发时,意味着收到了windowEnd+1的Watermark,即收齐了该windowEnd下的所有商品窗口统计值。我们在onTimer()中处理将收集的所有商品及点击量进行排序,选出TopN,并将排名信息格式化成字符串后进行输出。
这里我们还使用了ListState<ItemViewCount>来存储收到的每条ItemViewCount消息,保证在发生故障时,状态数据的不丢失和一致性。ListState是Flink提供的类似Java List接口的State API,它集成了框架的checkpoint机制,自动做到了exactly-once的语义保证。
// 求某个窗口中前 N 名的热门点击商品,key 为窗口时间戳,输出为 TopN 的结果字符串
class TopNHotItems(topSize: Int) extends KeyedProcessFunction[Tuple, ItemViewCount, String] {
private var itemState : ListState[ItemViewCount] = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
// 命名状态变量的名字和状态变量的类型
val itemsStateDesc = new ListStateDescriptor[ItemViewCount]("itemState-state", classOf[ItemViewCount])
// 定义状态变量
itemState = getRuntimeContext.getListState(itemsStateDesc)
}
override def processElement(input: ItemViewCount, context: KeyedProcessFunction[Tuple, ItemViewCount, String]#Context, collector: Collector[String]): Unit = {
// 每条数据都保存到状态中
itemState.add(input)
// 注册 windowEnd+1 的 EventTime Timer, 当触发时,说明收齐了属于windowEnd窗口的所有商品数据
// 也就是当程序看到windowend + 1的水位线watermark时,触发onTimer回调函数
context.timerService.registerEventTimeTimer(input.windowEnd + 1)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Tuple, ItemViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
// 获取收到的所有商品点击量
val allItems: ListBuffer[ItemViewCount] = ListBuffer()
import scala.collection.JavaConversions._
for (item <- itemState.get) {
allItems += item
}
// 提前清除状态中的数据,释放空间
itemState.clear()
// 按照点击量从大到小排序
val sortedItems = allItems.sortBy(_.count)(Ordering.Long.reverse).take(topSize)
// 将排名信息格式化成 String, 便于打印
val result: StringBuilder = new StringBuilder
result.append("====================================
")
result.append("时间: ").append(new Timestamp(timestamp - 1)).append("
")
for(i <- sortedItems.indices){
val currentItem: ItemViewCount = sortedItems(i)
// e.g. No1: 商品ID=12224 浏览量=2413
result.append("No").append(i+1).append(":")
.append(" 商品ID=").append(currentItem.itemId)
.append(" 浏览量=").append(currentItem.count).append("
")
}
result.append("====================================
")
// 控制输出频率,模拟实时滚动结果
Thread.sleep(1000)
out.collect(result.toString)
}
}
最后我们可以在main函数中将结果打印输出到控制台,方便实时观测:
.print();
至此整个程序代码全部完成,我们直接运行main函数,就可以在控制台看到不断输出的各个时间点统计出的热门商品。
2.2.5 完整代码
最终完整代码如下:
case class UserBehavior(userId: Long, itemId: Long, categoryId: Int, behavior: String, timestamp: Long)
case class ItemViewCount(itemId: Long, windowEnd: Long, count: Long)
object HotItems {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream = env
.readTextFile("YOUR_PATH\resources\UserBehavior.csv")
.map(line => {
val linearray = line.split(",")
UserBehavior(linearray(0).toLong, linearray(1).toLong, linearray(2).toInt, linearray(3), linearray(4).toLong)
})
.assignAscendingTimestamps(_.timestamp * 1000)
.filter(_.behavior=="pv")
.keyBy("itemId")
.timeWindow(Time.minutes(60), Time.minutes(5))
.aggregate(new CountAgg(), new WindowResultFunction())
.keyBy(1)
.process(new TopNHotItems(3))
.print()
env.execute("Hot Items Job")
}
// COUNT 统计的聚合函数实现,每出现一条记录加一
class CountAgg extends AggregateFunction[UserBehavior, Long, Long] {
override def createAccumulator(): Long = 0L
override def add(userBehavior: UserBehavior, acc: Long): Long = acc + 1
override def getResult(acc: Long): Long = acc
override def merge(acc1: Long, acc2: Long): Long = acc1 + acc2
}
// 用于输出窗口的结果
class WindowResultFunction extends WindowFunction[Long, ItemViewCount, Tuple, TimeWindow] {
override def apply(key: Tuple, window: TimeWindow, aggregateResult: Iterable[Long],
collector: Collector[ItemViewCount]) : Unit = {
val itemId: Long = key.asInstanceOf[Tuple1[Long]].f0
val count = aggregateResult.iterator.next
collector.collect(ItemViewCount(itemId, window.getEnd, count))
}
}
// 求某个窗口中前 N 名的热门点击商品,key 为窗口时间戳,输出为 TopN 的结果字符串
class TopNHotItems(topSize: Int) extends KeyedProcessFunction[Tuple, ItemViewCount, String] {
private var itemState : ListState[ItemViewCount] = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
// 命名状态变量的名字和状态变量的类型
val itemsStateDesc = new ListStateDescriptor[ItemViewCount]("itemState-state", classOf[ItemViewCount])
// 从运行时上下文中获取状态并赋值
itemState = getRuntimeContext.getListState(itemsStateDesc)
}
override def processElement(input: ItemViewCount, context: KeyedProcessFunction[Tuple, ItemViewCount, String]#Context, collector: Collector[String]): Unit = {
// 每条数据都保存到状态中
itemState.add(input)
// 注册 windowEnd+1 的 EventTime Timer, 当触发时,说明收齐了属于windowEnd窗口的所有商品数据
// 也就是当程序看到windowend + 1的水位线watermark时,触发onTimer回调函数
context.timerService.registerEventTimeTimer(input.windowEnd + 1)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Tuple, ItemViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
// 获取收到的所有商品点击量
val allItems: ListBuffer[ItemViewCount] = ListBuffer()
import scala.collection.JavaConversions._
for (item <- itemState.get) {
allItems += item
}
// 提前清除状态中的数据,释放空间
itemState.clear()
// 按照点击量从大到小排序
val sortedItems = allItems.sortBy(_.count)(Ordering.Long.reverse).take(topSize)
// 将排名信息格式化成 String, 便于打印
val result: StringBuilder = new StringBuilder
result.append("====================================
")
result.append("时间: ").append(new Timestamp(timestamp - 1)).append("
")
for(i <- sortedItems.indices){
val currentItem: ItemViewCount = sortedItems(i)
// e.g. No1: 商品ID=12224 浏览量=2413
result.append("No").append(i+1).append(":")
.append(" 商品ID=").append(currentItem.itemId)
.append(" 浏览量=").append(currentItem.count).append("
")
}
result.append("====================================
")
// 控制输出频率,模拟实时滚动结果
Thread.sleep(1000)
out.collect(result.toString)
}
}
}
2.2.6 更换Kafka 作为数据源
实际生产环境中,我们的数据流往往是从Kafka获取到的。如果要让代码更贴近生产实际,我们只需将source更换为Kafka即可:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream = env
.addSource(new FlinkKafkaConsumer[String]("hotitems", new SimpleStringSchema(), properties))
当然,根据实际的需要,我们还可以将Sink指定为Kafka、ES、Redis或其它存储,这里就不一一展开实现了。
第3章 实时流量统计
3.1 模块创建和数据准备
在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为NetworkTrafficAnalysis。在这个子模块中,我们同样并没有引入更多的依赖,所以也不需要改动pom文件。
在src/main/目录下,将默认源文件目录java改名为scala。将apache服务器的日志文件apache.log复制到资源文件目录src/main/resources下,我们将从这里读取数据。
3.2 代码实现
我们现在要实现的模块是 “实时流量统计”。对于一个电商平台而言,用户登录的入口流量、不同页面的访问流量都是值得分析的重要数据,而这些数据,可以简单地从web服务器的日志中提取出来。我们在这里实现最基本的“页面浏览数”的统计,也就是读取服务器日志中的每一行log,统计在一段时间内用户访问url的次数。
具体做法为:每隔5秒,输出最近10分钟内访问量最多的前N个URL。可以看出,这个需求与之前“实时热门商品统计”非常类似,所以我们完全可以借鉴此前的代码。
在src/main/scala下创建TrafficAnalysis.scala文件,新建一个单例对象。定义样例类ApacheLogEvent,这是输入的日志数据流;另外还有UrlViewCount,这是窗口操作统计的输出数据类型。在main函数中创建StreamExecutionEnvironment 并做配置,然后从apache.log文件中读取数据,并包装成ApacheLogEvent类型。
需要注意的是,原始日志中的时间是“dd/MM/yyyy:HH:mm:ss”的形式,需要定义一个DateTimeFormat将其转换为我们需要的时间戳格式:
.map(line => {
val linearray = line.split(" ")
val sdf = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss")
val timestamp = sdf.parse(linearray(3)).getTime
ApacheLogEvent(linearray(0), linearray(2), timestamp,
linearray(5), linearray(6))
})
完整代码如下:
NetworkTrafficAnalysis/src/main/scala/TrafficAnalysis.scala
case class ApacheLogEvent(ip: String, userId: String, eventTime: Long, method: String, url: String)
case class UrlViewCount(url: String, windowEnd: Long, count: Long)
object TrafficAnalysis {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val stream = env
// 以window下为例,需替换成自己的路径
.readTextFile("YOUR_PATH\resources\apache.log")
.map(line => {
val linearray = line.split(" ")
val simpleDateFormat = new SimpleDateFormat("dd/MM/yyyy:HH:mm:ss")
val timestamp = simpleDateFormat.parse(linearray(3)).getTime
ApacheLogEvent(linearray(0), linearray(2), timestamp, linearray(5), linearray(6))
})
.assignTimestampsAndWatermarks(new
BoundedOutOfOrdernessTimestampExtractor[ApacheLogEvent]
(Time.milliseconds(1000)) {
override def extractTimestamp(t: ApacheLogEvent): Long = {
t.eventTime
}
})
.keyBy("url")
.timeWindow(Time.minutes(10), Time.seconds(5))
.aggregate(new CountAgg(), new WindowResultFunction())
.keyBy(1)
.process(new TopNHotUrls(5))
.print()
env.execute("Traffic Analysis Job")
}
class CountAgg extends AggregateFunction[ApacheLogEvent, Long, Long] {
override def createAccumulator(): Long = 0L
override def add(apacheLogEvent: ApacheLogEvent, acc: Long): Long = acc + 1
override def getResult(acc: Long): Long = acc
override def merge(acc1: Long, acc2: Long): Long = acc1 + acc2
}
class WindowResultFunction extends WindowFunction[Long, UrlViewCount, Tuple, TimeWindow] {
override def apply(key: Tuple, window: TimeWindow, aggregateResult: Iterable[Long], collector: Collector[UrlViewCount]) : Unit = {
val url: String = key.asInstanceOf[Tuple1[String]].f0
val count = aggregateResult.iterator.next
collector.collect(UrlViewCount(url, window.getEnd, count))
}
}
class TopNHotUrls(topsize: Int) extends KeyedProcessFunction[Tuple, UrlViewCount, String] {
private var urlState : ListState[UrlViewCount] = _
override def open(parameters: Configuration): Unit = {
super.open(parameters)
val urlStateDesc = new ListStateDescriptor[UrlViewCount]("urlState-state", classOf[UrlViewCount])
urlState = getRuntimeContext.getListState(urlStateDesc)
}
override def processElement(input: UrlViewCount, context: KeyedProcessFunction[Tuple, UrlViewCount, String]#Context, collector: Collector[String]): Unit = {
// 每条数据都保存到状态中
urlState.add(input)
context.timerService.registerEventTimeTimer(input.windowEnd + 1)
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[Tuple, UrlViewCount, String]#OnTimerContext, out: Collector[String]): Unit = {
// 获取收到的所有URL访问量
val allUrlViews: ListBuffer[UrlViewCount] = ListBuffer()
import scala.collection.JavaConversions._
for (urlView <- urlState.get) {
allUrlViews += urlView
}
// 提前清除状态中的数据,释放空间
urlState.clear()
// 按照访问量从大到小排序
val sortedUrlViews = allUrlViews.sortBy(_.count)(Ordering.Long.reverse)
.take(topSize)
// 将排名信息格式化成 String, 便于打印
var result: StringBuilder = new StringBuilder
result.append("====================================
")
result.append("时间: ").append(new Timestamp(timestamp - 1)).append("
")
for (i <- sortedUrlViews.indices) {
val currentUrlView: UrlViewCount = sortedUrlViews(i)
// e.g. No1: URL=/blog/tags/firefox?flav=rss20 流量=55
result.append("No").append(i+1).append(":")
.append(" URL=").append(currentUrlView.url)
.append(" 流量=").append(currentUrlView.count).append("
")
}
result.append("====================================
")
// 控制输出频率,模拟实时滚动结果
Thread.sleep(1000)
out.collect(result.toString)
}
}
}
第4章 恶意登录监控
4.1 模块创建和数据准备
继续在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为LoginFailDetect。在这个子模块中,我们将会用到flink的CEP库来实现事件流的模式匹配,所以需要在pom文件中引入CEP的相关依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
同样,在src/main/目录下,将默认源文件目录java改名为scala。
4.2 代码实现
对于网站而言,用户登录并不是频繁的业务操作。如果一个用户短时间内频繁登录失败,就有可能是出现了程序的恶意攻击,比如密码暴力破解。因此我们考虑,应该对用户的登录失败动作进行统计,具体来说,如果同一用户(可以是不同IP)在2秒之内连续两次登录失败,就认为存在恶意登录的风险,输出相关的信息进行报警提示。这是电商网站、也是几乎所有网站风控的基本一环。
4.2.1 状态编程
由于同样引入了时间,我们可以想到,最简单的方法其实与之前的热门统计类似,只需要按照用户ID分流,然后遇到登录失败的事件时将其保存在ListState中,然后设置一个定时器,2秒后触发。定时器触发时检查状态中的登录失败事件个数,如果大于等于2,那么就输出报警信息。
在src/main/scala下创建LoginFail.scala文件,新建一个单例对象。定义样例类LoginEvent,这是输入的登录事件流。由于没有现成的登录数据,我们用几条自定义的示例数据来做演示。
代码如下:
LoginFailDetect/src/main/scala/LoginFail.scala
case class LoginEvent(userId: Long, ip: String, eventType: String, eventTime: Long)
object LoginFail {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val loginEventStream = env.fromCollection(List(
LoginEvent(1, "192.168.0.1", "fail", 1558430842),
LoginEvent(1, "192.168.0.2", "fail", 1558430843),
LoginEvent(1, "192.168.0.3", "fail", 1558430844),
LoginEvent(2, "192.168.10.10", "success", 1558430845)
))
.assignAscendingTimestamps(_.eventTime * 1000)
.keyBy(_.userId)
.process(new MatchFunction())
.print()
env.execute("Login Fail Detect Job")
}
class MatchFunction extends KeyedProcessFunction[Long, LoginEvent, LoginEvent] {
// 定义状态变量
lazy val loginState: ListState[LoginEvent] = getRuntimeContext.getListState(
new ListStateDescriptor[LoginEvent]("saved login", classOf[LoginEvent]))
override def processElement(login: LoginEvent,
context: KeyedProcessFunction[Long, LoginEvent,
LoginEvent]#Context, out: Collector[LoginEvent]): Unit = {
if (login.eventType == "fail") {
loginState.add(login)
}
// 注册定时器,触发事件设定为2秒后
context.timerService.registerEventTimeTimer(login.eventTime + 2 * 1000)
}
override def onTimer(timestamp: Long,
ctx: KeyedProcessFunction[Long, LoginEvent,
LoginEvent]#OnTimerContext, out: Collector[LoginEvent]): Unit = {
val allLogins: ListBuffer[LoginEvent] = ListBuffer()
import scala.collection.JavaConversions._
for (login <- loginState.get) {
allLogins += login
}
loginState.clear()
if (allLogins.length > 1) {
out.collect(allLogins.head)
}
}
}
}
4.2.2 CEP编程
上一节的代码实现中我们可以看到,直接把每次登录失败的数据存起来、设置定时器一段时间后再读取,这种做法尽管简单,但和我们开始的需求还是略有差异的。这种做法只能隔2秒之后去判断一下这期间是否有多次失败登录,而不是在一次登录失败之后、再一次登录失败时就立刻报警。这个需求如果严格实现起来,相当于要判断任意紧邻的事件,是否符合某种模式。这听起来就很复杂了,那有什么方式可以方便地实现呢?
很幸运,flink为我们提供了CEP(Complex Event Processing,复杂事件处理)库,用于在流中筛选符合某种复杂模式的事件。接下来我们就基于CEP来完成这个模块的实现。
在src/main/scala下继续创建LoginFailWithCep.scala文件,新建一个单例对象。样例类LoginEvent由于在LoginFail.scala已经定义,我们在同一个模块中就不需要再定义了。
代码如下:
LoginFailDetect/src/main/scala/LoginFailWithCep.scala
object LoginFailWithCep {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val loginEventStream = env.fromCollection(List(
LoginEvent(1, "192.168.0.1", "fail", 1558430842),
LoginEvent(1, "192.168.0.2", "fail", 1558430843),
LoginEvent(1, "192.168.0.3", "fail", 1558430844),
LoginEvent(2, "192.168.10.10", "success", 1558430845)
)).assignAscendingTimestamps(_.eventTime * 1000)
// 定义匹配模式
val loginFailPattern = Pattern.begin[LoginEvent]("begin")
.where(_.eventType == "fail")
.next("next")
.where(_.eventType == "fail")
.within(Time.seconds(2))
// 在数据流中匹配出定义好的模式
val patternStream = CEP.pattern(loginEventStream.keyBy(_.userId), loginFailPattern)
// .select方法传入一个 pattern select function,当检测到定义好的模式序列时就会调用
val loginFailDataStream = patternStream
.select((pattern: Map[String, Iterable[LoginEvent]]) => {
val first = pattern.getOrElse("begin", null).iterator.next()
val second = pattern.getOrElse("next", null).iterator.next()
(second.userId, second.ip, second.eventType)
})
// 将匹配到的符合条件的事件打印出来
loginFailDataStream.print()
env.execute("Login Fail Detect Job")
}
}
第5章 订单支付实时监控
5.1 模块创建和数据准备
同样地,在UserBehaviorAnalysis下新建一个 maven module作为子项目,命名为OrderTimeoutDetect。在这个子模块中,我们同样将会用到flink的CEP库来实现事件流的模式匹配,所以需要在pom文件中引入CEP的相关依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
同样,在src/main/目录下,将默认源文件目录java改名为scala。
5.2 代码实现
在电商平台中,最终创造收入和利润的是用户下单购买的环节;更具体一点,是用户真正完成支付动作的时候。用户下单的行为可以表明用户对商品的需求,但在现实中,并不是每次下单都会被用户立刻支付。当拖延一段时间后,用户支付的意愿会降低。所以为了让用户更有紧迫感从而提高支付转化率,同时也为了防范订单支付环节的安全风险,电商网站往往会对订单状态进行监控,设置一个失效时间(比如15分钟),如果下单后一段时间仍未支付,订单就会被取消。
我们将会利用CEP库来实现这个功能。我们先将事件流按照订单号orderId分流,然后定义这样的一个事件模式:在15分钟内,事件“create”与“pay”严格紧邻:
val orderPayPattern = Pattern.begin[OrderEvent]("begin")
.where(_.eventType == "create")
.next("next")
.where(_.eventType == "pay")
.within(Time.seconds(5))
这样调用.select方法时,就可以同时获取到匹配出的事件和超时未匹配的事件了。
在src/main/scala下继续创建OrderTimeout.scala文件,新建一个单例对象。定义样例类OrderEvent,这是输入的订单事件流;另外还有OrderResult,这是输出显示的订单状态结果。由于没有现成的数据,我们还是用几条自定义的示例数据来做演示。
完整代码如下:
OrderTimeoutDetect/src/main/scala/OrderTimeout.scala
case class OrderEvent(orderId: Long, eventType: String, eventTime: Long)
case class OrderResult(orderId: Long, eventType: String)
object OrderTimeout {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val orderEventStream = env.fromCollection(List(
OrderEvent(1, "create", 1558430842),
OrderEvent(2, "create", 1558430843),
OrderEvent(2, "pay", 1558430844)
)).assignAscendingTimestamps(_.eventTime * 1000)
// 定义一个带匹配时间窗口的模式
val orderPayPattern = Pattern.begin[OrderEvent]("begin")
.where(_.eventType == "create")
.next("next")
.where(_.eventType == "pay")
.within(Time.minutes(15))
// 定义一个输出标签
val orderTimeoutOutput = OutputTag[OrderResult]("orderTimeout")
// 订单事件流根据 orderId 分流,然后在每一条流中匹配出定义好的模式
val patternStream = CEP.pattern(orderEventStream.keyBy("orderId"), orderPayPattern)
val complexResult = patternStream.select(orderTimeoutOutput) {
// 对于已超时的部分模式匹配的事件序列,会调用这个函数
(pattern: Map[String, Iterable[OrderEvent]], timestamp: Long) => {
val createOrder = pattern.get("begin")
OrderResult(createOrder.get.iterator.next().orderId, "timeout")
}
} {
// 检测到定义好的模式序列时,就会调用这个函数
pattern: Map[String, Iterable[OrderEvent]] => {
val payOrder = pattern.get("next")
OrderResult(payOrder.get.iterator.next().orderId, "success")
}
}
// 拿到同一输出标签中的 timeout 匹配结果(流)
val timeoutResult = complexResult.getSideOutput(orderTimeoutOutput)
complexResult.print()
timeoutResult.print()
env.execute("Order Timeout Detect Job")
}
}