直接附上代码
# -*- coding: utf-8 -*- """ Created on Sat Jan 16 15:18:33 2021 @author: Administrator """ import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import datetime import warnings warnings.filterwarnings('ignore') #%%导入数据 data_train = pd.read_csv('D:/python_home/阿里云金融风控-贷款违约预测/train.csv') data_test_a = pd.read_csv('D:/python_home/阿里云金融风控-贷款违约预测/testA.csv') #%%基本的数据描述 data_train.shape,data_test_a.shape #((800000, 47), (200000, 46)) data_train.columns ''' Index(['id', 'loanAmnt', 'term', 'interestRate', 'installment', 'grade', 'subGrade', 'employmentTitle', 'employmentLength', 'homeOwnership', 'annualIncome', 'verificationStatus', 'issueDate', 'isDefault', 'purpose', 'postCode', 'regionCode', 'dti', 'delinquency_2years', 'ficoRangeLow', 'ficoRangeHigh', 'openAcc', 'pubRec', 'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc', 'initialListStatus', 'applicationType', 'earliesCreditLine', 'title', 'policyCode', 'n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14'], dtype='object') ''' data_test_a.columns ''' Index(['id', 'loanAmnt', 'term', 'interestRate', 'installment', 'grade', 'subGrade', 'employmentTitle', 'employmentLength', 'homeOwnership', 'annualIncome', 'verificationStatus', 'issueDate', 'purpose', 'postCode', 'regionCode', 'dti', 'delinquency_2years', 'ficoRangeLow', 'ficoRangeHigh', 'openAcc', 'pubRec', 'pubRecBankruptcies', 'revolBal', 'revolUtil', 'totalAcc', 'initialListStatus', 'applicationType', 'earliesCreditLine', 'title', 'policyCode', 'n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10', 'n11', 'n12', 'n13', 'n14'], dtype='object') ''' #%%看一下变量的取值的个数,用来划分数值型还是类别型 for i in list(data_train.columns): print(i, data_train[i].nunique()) ''' id 800000 loanAmnt 1540 贷款金额 term 2 interestRate 641 installment 72360 grade 7 subGrade 35 employmentTitle 248683 employmentLength 11 homeOwnership 6 annualIncome 44926 verificationStatus 3 issueDate 139 isDefault 2 purpose 14 postCode 932 regionCode 51 dti 6321 delinquency_2years 30 ficoRangeLow 39 ficoRangeHigh 39 openAcc 75 pubRec 32 pubRecBankruptcies 11 revolBal 71116 revolUtil 1286 totalAcc 134 initialListStatus 2 applicationType 2 earliesCreditLine 720 title 39644 policyCode 1 n0 39 n1 33 n2 50 n3 50 n4 46 n5 65 n6 107 n7 70 n8 102 n9 44 n10 76 n11 5 n12 5 n13 28 n14 31 ''' cate_col = ['term', 'grade', 'subGrade', 'employmentLength', 'homeOwnership', 'verificationStatus', 'isDefault', 'purpose', 'pubRecBankruptcies', 'initialListStatus', 'applicationType', 'policyCode','n11', 'n12'] num_col = [i for i in list(data_train.columns)[1:] if i not in cate_col] data_train[cate_col].nunique() #%%类别变量的iv值计算 import pycard as pc cate_iv_woedf = pc.WoeDf() clf = pc.NumBin() for i in cate_col: cate_iv_woedf.append(pc.cross_woe(data_train[i] ,data_train.isDefault)) cate_iv_woedf.to_excel('tmp11') cate_use_col = ['term','grade','verificationStatus'] #%%数值型变量的iv值计算 num_col.remove('issueDate') num_col.remove('earliesCreditLine') #上面这两个是时间日期的东西,后面再做处理吧 num_iv_woedf = pc.WoeDf() clf = pc.NumBin() for i in num_col: clf.fit(data_train[i] ,data_train.isDefault) clf.generate_transform_fun() num_iv_woedf.append(clf.woe_df_) num_iv_woedf.to_excel('tmp12') from numpy import * data_train['loanAmnt_bin'] = pd.cut(data_train.loanAmnt,bins=[-inf, 3512.5, 9012.5, 10012.5, 11987.5, 15012.5, 28012.5, inf]) #interestRate data_train['interestRate_bin'] = pd.cut(data_train.interestRate,bins=[-inf, 7.885, 9.73, 11.415, 13.175, 15.975, 17.785, 21.985, inf]) #annualIncome data_train['annualIncome_bin'] = pd.cut(data_train.annualIncome,bins=[-inf, 37001.5996, 45670.5, 60995.5, 70017.5, 86462.0, 100670.5, 160030.0, inf]) #dti,先用均值填充,再分 data_train['dti'] = data_train['dti'].fillna(data_train['dti'].mean()) data_train['dti_bin'] = pd.cut(data_train.dti,bins=[-inf, 10.745, 14.845, 18.255, 21.745, 25.325, 30.195, 33.225, inf]) #ficoRangeLow data_train['ficoRangeLow_bin'] = pd.cut(data_train.ficoRangeLow,bins=[-inf, 667.5, 682.5, 692.5, 702.5, 717.5, 732.5, 767.5, inf]) #revolUtil,均值填充,再分 data_train['revolUtil'] = data_train['revolUtil'].fillna(data_train['revolUtil'].mean()) data_train['revolUtil_bin'] = pd.cut(data_train.revolUtil,bins=[-inf, 19.75, 29.35, 38.55, 47.95, 56.55, 86.85, inf]) #n14 空值作为一列, data_train['n14_bin'] = pd.cut(data_train.n14,bins=[-inf, 0.5, 1.5, 2.5, 3.5, 4.5, 6.5, inf]) woe_col = [i for i in ['term','grade','verificationStatus']+list(data_train.columns)[-7:]] #%% cate_iv_woedf = pc.WoeDf() clf = pc.NumBin() for i in woe_col: cate_iv_woedf.append(pc.cross_woe(data_train[i] ,data_train.isDefault)) cate_iv_woedf.to_excel('tmp11') data_train.grade[data_train.grade =='G'] = 'F' #%%woe转换 pc.obj_info(cate_iv_woedf) cate_iv_woedf.bin2woe(data_train,woe_col) model_col = [i for i in ['id', 'isDefault']+list(data_train.columns)[-10:]] data_train[model_col].isnull().sum() data_train[model_col].info() model_data = data_train[model_col] model_data = model_data.astype(float) model_data.n14_woe[model_data.n14_woe.isnull()]=0.34984133 #%%建模 import pandas as pd import matplotlib.pyplot as plt #导入图像库 import matplotlib import seaborn as sns import statsmodels.api as sm from sklearn.metrics import roc_curve, auc from sklearn.model_selection import train_test_split X = model_data[['_woe', 'g_woe', 'verificationSt_woe', 'loanAmnt_woe', 'interestRate_woe', 'annualIncome_woe', 'dti_woe', 'ficoRangeLow_woe', 'revolUtil_woe', 'n14_woe']] Y = model_data['isDefault'] x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=0) #(10127, 44) X1=sm.add_constant(x_train) #在X前加上一列常数1,方便做带截距项的回归 logit=sm.Logit(y_train.astype(float),X1.astype(float)) result=logit.fit() result.summary() result.params X3 = sm.add_constant(x_test) resu = result.predict(X3.astype(float)) fpr, tpr, threshold = roc_curve(y_test, resu) rocauc = auc(fpr, tpr) plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([0, 1]) plt.ylim([0, 1]) plt.ylabel('真正率') plt.xlabel('假正率') plt.show() resu_1 = result.predict(X1.astype(float)) fpr, tpr, threshold = roc_curve(y_train, resu_1) rocauc = auc(fpr, tpr) plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([0, 1]) plt.ylim([0, 1]) plt.ylabel('真正率') plt.xlabel('假正率') plt.show()
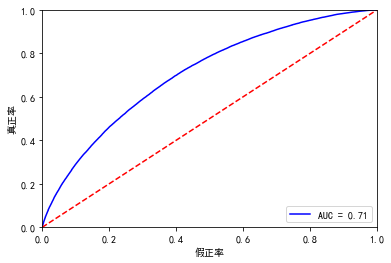
最后结果是 0.7026,比上次的0.6829 多了约2%,目前排名榜上最高分是0.7492,距离目标还差5%左右
看了看别人写的代码,效果能达到7.348,现附上链接:https://blog.csdn.net/qq_44694861/article/details/109753004?spm=5176.12282029.0.0.209a4288OlvFjo
代码如下:
# -*- coding: utf-8 -*- """ Created on Tue Feb 9 10:04:26 2021 @author: Administrator """ #%% import pandas as pd import datetime import warnings warnings.filterwarnings('ignore') from sklearn.model_selection import StratifiedKFold #warnings.filterwarnings('ignore') #%matplotlib inline from sklearn.metrics import roc_auc_score ## 数据降维处理的 from sklearn.model_selection import train_test_split from catboost import CatBoostClassifier #pip3 install --user catboost -i https://pypi.tuna.tsinghua.edu.cn/simple/ #%% train = pd.read_csv('D:/python_home/阿里云金融风控-贷款违约预测/train.csv') testA = pd.read_csv('D:/python_home/阿里云金融风控-贷款违约预测/testA.csv') #%% numerical_fea = list(train.select_dtypes(exclude=['object']).columns) numerical_fea.remove('isDefault') train[numerical_fea] = train[numerical_fea].fillna(train[numerical_fea].median()) testA[numerical_fea] = testA[numerical_fea].fillna(testA[numerical_fea].median()) #issueDate for data in [train]: data['issueDate'] = pd.to_datetime(data['issueDate'],format='%Y-%m-%d') data['grade'] = data['grade'].map({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7}) data['employmentLength'] = data['employmentLength'].map({'1 year':1,'2 years':2,'3 years':3,'4 years':4,'5 years':5,'6 years':6,'7 years':7,'8 years':8,'9 years':9,'10+ years':10,'< 1 year':0}) data['subGrade'] = data['subGrade'].map({'E2':1,'D2':2,'D3':3,'A4':4,'C2':5,'A5':6,'C3':7,'B4':8,'B5':9,'E5':10, 'D4':11,'B3':12,'B2':13,'D1':14,'E1':15,'C5':16,'C1':17,'A2':18,'A3':19,'B1':20, 'E3':21,'F1':22,'C4':23,'A1':24,'D5':25,'F2':26,'E4':27,'F3':28,'G2':29,'F5':30, 'G3':31,'G1':32,'F4':33,'G4':34,'G5':35}) data['earliesCreditLine'] = data['earliesCreditLine'].apply(lambda s: int(s[-4:])) # data['n15']=data['n8']*data['n10'] for data in [testA]: data['issueDate'] = pd.to_datetime(data['issueDate'],format='%Y-%m-%d') data['grade'] = data['grade'].map({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7}) data['employmentLength'] = data['employmentLength'].map({'1 year':1,'2 years':2,'3 years':3,'4 years':4,'5 years':5,'6 years':6,'7 years':7,'8 years':8,'9 years':9,'10+ years':10,'< 1 year':0}) data['subGrade'] = data['subGrade'].map({'E2':1,'D2':2,'D3':3,'A4':4,'C2':5,'A5':6,'C3':7,'B4':8,'B5':9,'E5':10, 'D4':11,'B3':12,'B2':13,'D1':14,'E1':15,'C5':16,'C1':17,'A2':18,'A3':19,'B1':20, 'E3':21,'F1':22,'C4':23,'A1':24,'D5':25,'F2':26,'E4':27,'F3':28,'G2':29,'F5':30, 'G3':31,'G1':32,'F4':33,'G4':34,'G5':35}) data['earliesCreditLine'] = data['earliesCreditLine'].apply(lambda s: int(s[-4:])) print("数据预处理完成!") #%% sub=testA[['id']].copy() sub['isDefault']=0 testA=testA.drop(['id','issueDate'],axis=1) data_x=train.drop(['isDefault','id','issueDate'],axis=1) data_y=train[['isDefault']].copy() x, val_x, y, val_y = train_test_split( data_x, data_y, test_size=0.25, random_state=1, stratify=data_y ) col=['grade','subGrade','employmentTitle','homeOwnership','verificationStatus','purpose','postCode','regionCode', 'initialListStatus','applicationType','policyCode'] for i in data_x.columns: if i in col: data_x[i] = data_x[i].astype('str') for i in testA.columns: if i in col: testA[i] = testA[i].astype('str') #%% model=CatBoostClassifier( loss_function="Logloss", eval_metric="AUC", task_type="CPU", learning_rate=0.1, iterations=500, random_seed=2020, od_type="Iter", depth=7) answers = [] mean_score = 0 n_folds = 5 sk = StratifiedKFold(n_splits=n_folds, shuffle=True, random_state=2019) for train, test in sk.split(data_x, data_y): x_train = data_x.iloc[train] y_train = data_y.iloc[train] x_test = data_x.iloc[test] y_test = data_y.iloc[test] clf = model.fit(x_train,y_train, eval_set=(x_test,y_test),verbose=500,cat_features=col) yy_pred_valid=clf.predict(x_test) print('cat验证的auc:{}'.format(roc_auc_score(y_test, yy_pred_valid))) mean_score += roc_auc_score(y_test, yy_pred_valid) / n_folds y_pred_valid = clf.predict(testA,prediction_type='Probability')[:,-1] answers.append(y_pred_valid) print('mean valAuc:{}'.format(mean_score)) #%% cat_pre=sum(answers)/n_folds sub['isDefault']=cat_pre sub.to_csv('金融预测.csv',index=False)
注意事项:
1.catboost只能识别字符类型和数值类型的数据
2.代码需要很长的时间去跑