数据链接:http://data.sd.gov.cn/cmpt/cmptDetail.html?id=26
评分标准:给定一个阀值,可根据混淆矩阵计算TPR(覆盖率)和FPR(打扰率) TPR = TP /(TP + FN) FPR = FP /(FP + TN) 其中,TP、FN、FP、TN分别为真正例、假反例、假正例、真反例。 这里的评分指标,首先计算了3个覆盖率TPR: TPR1:FPR=0.001时的TPR TPR2:FPR=0.005时的TPR TPR3:FPR=0.01时的TPR 最终成绩= 0.4 * TPR1 + 0.3 * TPR2 + 0.3 * TPR3
代码如下:
def tpr_weight_funtion(y_true,y_predict): d = pd.DataFrame() d['prob'] = list(y_predict) d['y'] = list(y_true) d = d.sort_values(['prob'], ascending=[0]) y = d.y PosAll = pd.Series(y).value_counts()[1] NegAll = pd.Series(y).value_counts()[0] pCumsum = d['y'].cumsum() nCumsum = np.arange(len(y)) - pCumsum + 1 pCumsumPer = pCumsum / PosAll nCumsumPer = nCumsum / NegAll TR1 = pCumsumPer[abs(nCumsumPer-0.001).idxmin()] TR2 = pCumsumPer[abs(nCumsumPer-0.005).idxmin()] TR3 = pCumsumPer[abs(nCumsumPer-0.01).idxmin()] return 0.4 * TR1 + 0.3 * TR2 + 0.3 * TR3
其他的就不多说的,直接上第一版的代码
# -*- coding: utf-8 -*- """ Created on Wed Jan 27 09:44:50 2021 @author: Administrator """ import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import datetime import warnings warnings.filterwarnings('ignore') #%%导入数据 train = pd.read_csv('E:\山东竞赛\公积金逾期预测\公积金逾期预测-数据\公积金逾期预测-数据\train.csv') test = pd.read_csv('E:\山东竞赛\公积金逾期预测\公积金逾期预测-数据\公积金逾期预测-数据\test.csv') ''' XINGBIE 3 CSNY 393 HYZK 4 ZHIYE 7 ZHICHEN 4 ZHIWU 2 XUELI 2 DWJJLX 28 DWSSHY 21 ''' #%%性别 train.XINGBIE.value_counts(normalize=True) #男女比列63%:36% test.XINGBIE.value_counts(normalize=True) #65%:34% #%%先复制一个表 train_copy = train.copy() #%%出生年月 train_copy.CSNY.value_counts(normalize=True).sort_index() train_copy = train_copy[~train_copy.CSNY.isin([190364572800])] train_copy.shape #(39999, 21) train_copy['birthday'] = train_copy.apply(lambda x:datetime.datetime.fromtimestamp(x.CSNY),axis=1) train_copy.birthday.value_counts(normalize=True).sort_index().to_excel('tmp25.xlsx') import pycard as pc train_copy['to_date'] = datetime.date(2020, 9, 30) train_copy['age'] = pc.month_diff(train_copy['to_date'],train_copy['birthday']) train_copy['age'] = train_copy['age']/12 train_copy['age'] = train_copy['age'].astype('int') train_copy.age.value_counts(normalize=True).sort_index().to_excel('tmp25.xlsx') #%%测试集 test.CSNY.value_counts(normalize=True).sort_index() test.CSNY[test.CSNY==150445008000] = 1330531200 test.shape #(39999, 21) test['birthday'] = test.apply(lambda x:datetime.datetime.fromtimestamp(x.CSNY),axis=1) test['to_date'] = datetime.date(2020, 9, 30) test['age'] = pc.month_diff(test['to_date'],test['birthday']) test['age'] = test['age']/12 test['age'] = test['age'].astype('int') test.age.value_counts(normalize=True).sort_index().to_excel('tmp25.xlsx') #%%婚姻状况 train_copy.HYZK.value_counts(normalize=True) #99.99%都是一类 test.HYZK.value_counts(normalize=True) #100%都是一类 train_copy.pop('HYZK') test.pop('HYZK') #%%职业 train_copy.ZHIYE.value_counts(normalize=True) #99.99%都是一类 test.ZHIYE.value_counts(normalize=True) #100%都是一类 train_copy.pop('ZHIYE') test.pop('ZHIYE') #%%职称 train_copy.ZHICHEN.value_counts(normalize=True) #99.99%都是一类 test.ZHICHEN.value_counts(normalize=True) #100%都是一类 train_copy.pop('ZHICHEN') test.pop('ZHICHEN') #%%职务 train_copy.ZHIWU.value_counts(normalize=True) #99.99%都是一类 test.ZHIWU.value_counts(normalize=True) #3-7分,有干扰数据 train_copy.pop('ZHIWU') test.pop('ZHIWU') #%%学历 train_copy.XUELI.value_counts(normalize=True) #99.99%都是一类 test.XUELI.value_counts(normalize=True) #100%都是一类 train_copy.pop('XUELI') test.pop('XUELI') #%%单位 train_copy.DWJJLX.value_counts(normalize=True) #99.99%都是一类 test.DWJJLX.value_counts(normalize=True) #100%都是一类 #%%重复,删除一个 train_copy.pop('GRYJCE') test.pop('GRYJCE') #%%个人缴存基 #年利率;济南现行政策中5年以下是2.75,5年以上是3.25。职工若第二次贷款,利率上浮10%。 #%%类别型变量的iv值计算 cate_col = ['DWJJLX', 'DWSSHY','GRZHZT','DKLL'] import pycard as pc cate_iv_woedf = pc.WoeDf() clf = pc.NumBin() for i in cate_col: cate_iv_woedf.append(pc.cross_woe(train_copy[i] ,train_copy.label)) cate_iv_woedf.to_excel('tmp25') #%%类别变量处理 map_dict={140:0, 142:0, 143:0, 149:0, 171:0, 172:0, 173:0, 174:0, 175:0, 210:0, 230:0, 310:0, 330:0, 390:0, 130:0, 159:0, 300:0, 120:1, 160:1, 200:1, 150:1, 141:1, 170:1, 110:2, 900:3, 100:4, 179:4, 190:4} train_copy['DWJJLX_bin'] = train_copy.DWJJLX.map(map_dict) map_dict1 = {19:0, 11:0, 10:0, 7:0, 3:0, 0:0, 6:0, 2:1, 4:1, 13:1, 9:2, 1:2, 12:3, 14:3, 8:3, 17:4, 18:4, 5:4, 16:5, 15:5, 20:5} train_copy['DWSSHY_bin'] = train_copy.DWSSHY.map(map_dict1) from numpy import * train_copy['GRZHZT_bin'] = pd.cut(train_copy.GRZHZT,bins=[-inf, 1, inf]) train_copy['DKLL_bin'] = pd.cut(train_copy.DKLL,bins=[-inf, 2.75, inf]) #%%测试集 test['DWJJLX_bin'] = test.DWJJLX.map(map_dict) test['DWSSHY_bin'] = test.DWSSHY.map(map_dict1) test['GRZHZT_bin'] = pd.cut(test.GRZHZT,bins=[-inf, 1, inf]) test['DKLL_bin'] = pd.cut(test.DKLL,bins=[-inf, 2.75, inf]) #%%数值型 num_col=['GRJCJS', 'GRZHYE', 'GRZHSNJZYE', 'GRZHDNGJYE', 'DWYJCE', 'DKFFE', 'DKYE','age','tiqu', 'DKFFE_GRJCJS', 'DKFFE_GRZHYE', 'DKFFE_DWYJCE', 'DKFFE_DKYE', 'DKFFE_age', 'GRJCJS_age', 'GRZHYE_age'] train_copy[num_col].describe() #%%构造变量 #提取金额 GRZHDNGJYE = -提取金额+DWYJCE*12 train_copy['tiqu'] = train_copy.DWYJCE*12*2-train_copy.GRZHDNGJYE train_copy['tiqu'].max() train_copy['DKFFE_GRJCJS'] = train_copy.DKFFE/train_copy.GRJCJS train_copy['DKFFE_GRZHYE'] = train_copy.DKFFE/train_copy.GRZHYE train_copy['DKFFE_DWYJCE'] = train_copy.DKFFE/train_copy.DWYJCE train_copy['DKFFE_DKYE'] = train_copy.DKYE/train_copy.DKFFE train_copy['DKFFE_age'] = train_copy.DKFFE/train_copy.age train_copy['GRJCJS_age'] = train_copy.GRJCJS/train_copy.age train_copy['GRZHYE_age'] = train_copy.GRZHYE/train_copy.age #%%数值型变量的iv num_col=['GRJCJS', 'GRZHYE', 'GRZHSNJZYE', 'GRZHDNGJYE', 'DWYJCE', 'DKFFE', 'DKYE','age','tiqu', 'DKFFE_DKYE'] num_iv_woedf = pc.WoeDf() clf = pc.NumBin() for i in num_col: clf.fit(train_copy[i] ,train_copy.label) clf.generate_transform_fun() num_iv_woedf.append(clf.woe_df_) num_iv_woedf.to_excel('tmp25') train_copy['GRJCJS_bin'] = pd.cut(train_copy.GRJCJS,bins=[-inf, 1197.25, 3745.75, 4489.25, 9801.75, 12446.0, inf]) train_copy['GRZHYE_bin'] = pd.cut(train_copy.GRZHYE,bins=[-inf, 1324.0175, 5607.4651, 16688.3525, 25816.3701, 39361.7637, 65252.7266, inf]) train_copy['GRZHSNJZYE_bin'] = pd.cut(train_copy.GRZHSNJZYE,bins=[-inf, 240.7625, 397.5475, 21479.625, 30042.8545, inf]) train_copy['GRZHDNGJYE_bin'] = pd.cut(train_copy.GRZHDNGJYE,bins=[-inf, 204.94, 237.5275, 3905.64, 4846.5601, 6378.79, inf]) train_copy['DWYJCE_bin'] = pd.cut(train_copy.DWYJCE,bins=[-inf, 351.595, 657.11, 739.3075, 1384.8, 1702.08, inf]) train_copy['DKFFE_bin'] = pd.cut(train_copy.DKFFE,bins=[-inf, 129487.0, 168487.0, 250487.0, 339987.0, inf]) train_copy['DKYE_bin'] = pd.cut(train_copy.DKYE,bins=[-inf, 237.0875, 40012.8418, 63379.4609, 113304.7031, 141377.0547, 150237.0547, 272994.5781, inf]) train_copy['age_bin'] = pd.cut(train_copy.age,bins=[-inf, 10.0, 29.5, 31.5, 32.5, 34.5, 35.5, 48.5, inf]) train_copy['tiqu_bin'] = pd.cut(train_copy.tiqu,bins=[-inf, 6500.6951, 9509.8101, 14111.0801, 15543.5, 22686.7305, inf]) train_copy['DKFFE_DKYE_bin'] = pd.cut(train_copy.DKFFE_DKYE,bins=[-inf, 0.5167, 0.7419, 0.8772, 0.9046, 0.929, 0.9385, 0.9727, inf]) train_copy = train_copy[['label','DWJJLX_bin', 'DWSSHY_bin', 'GRZHZT_bin', 'DKLL_bin','GRJCJS_bin', 'GRZHYE_bin', 'GRZHSNJZYE_bin', 'GRZHDNGJYE_bin', 'DWYJCE_bin','DKFFE_bin', 'DKYE_bin', 'age_bin', 'tiqu_bin', 'DKFFE_DKYE_bin']] #%%调箱后的iv iv_col = ['DWJJLX_bin', 'DWSSHY_bin', 'GRZHZT_bin', 'DKLL_bin','GRJCJS_bin', 'GRZHYE_bin', 'GRZHSNJZYE_bin', 'GRZHDNGJYE_bin', 'DWYJCE_bin', 'DKFFE_bin', 'DKYE_bin', 'age_bin', 'tiqu_bin', 'DKFFE_DKYE_bin'] cate_iv_woedf = pc.WoeDf() for i in iv_col: cate_iv_woedf.append(pc.cross_woe(train_copy[i] ,train_copy.label)) cate_iv_woedf.to_excel('tmp25') len(iv_col) #%%woe转换 cate_iv_woedf.bin2woe(train_copy,iv_col) model_col = ['label','DWJJLX_woe', 'DWSSHY_woe', 'GRZHZT_woe', 'DKLL_woe', 'GRJCJS_woe', 'GRZHYE_woe', 'GRZHSNJZYE_woe', 'GRZHDNGJYE_woe', 'DWYJCE_woe', 'DKFFE_woe', 'DKYE_woe','age_woe', 'tiqu_woe', 'DKFFE_DKYE_woe'] model_data = train_copy[model_col] model_data.info() model_data = model_data.astype(float64) #%%建模 import pandas as pd import matplotlib.pyplot as plt #导入图像库 import matplotlib import seaborn as sns import statsmodels.api as sm from sklearn.metrics import roc_curve, auc,confusion_matrix from sklearn.model_selection import train_test_split X = model_data[['DWJJLX_woe', 'DWSSHY_woe', 'GRZHZT_woe', 'DKLL_woe', 'GRJCJS_woe', 'GRZHYE_woe', 'GRZHSNJZYE_woe', 'GRZHDNGJYE_woe', 'DWYJCE_woe', 'DKFFE_woe', 'DKYE_woe','age_woe', 'tiqu_woe', 'DKFFE_DKYE_woe']] Y = model_data['label'] x_train,x_test,y_train,y_test=train_test_split(X,Y,test_size=0.3,random_state=0) #(10127, 44) X1=sm.add_constant(x_train) #在X前加上一列常数1,方便做带截距项的回归 logit=sm.Logit(y_train.astype(float),X1.astype(float)) result=logit.fit() result.summary() result.params resu_1 = result.predict(X1.astype(float)) fpr, tpr, threshold = roc_curve(y_train, resu_1) rocauc = auc(fpr, tpr) plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([0, 1]) plt.ylim([0, 1]) plt.ylabel('真正率') plt.xlabel('假正率') plt.show() X3 = sm.add_constant(x_test) resu = result.predict(X3.astype(float)) fpr, tpr, threshold = roc_curve(y_test, resu) rocauc = auc(fpr, tpr) plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc) plt.legend(loc='lower right') plt.plot([0, 1], [0, 1], 'r--') plt.xlim([0, 1]) plt.ylim([0, 1]) plt.ylabel('真正率') plt.xlabel('假正率') plt.show() def tpr_weight_funtion(y_true,y_predict): d = pd.DataFrame() d['prob'] = list(y_predict) d['y'] = list(y_true) d = d.sort_values(['prob'], ascending=[0]) y = d.y PosAll = pd.Series(y).value_counts()[1] NegAll = pd.Series(y).value_counts()[0] pCumsum = d['y'].cumsum() nCumsum = np.arange(len(y)) - pCumsum + 1 pCumsumPer = pCumsum / PosAll nCumsumPer = nCumsum / NegAll TR1 = pCumsumPer[abs(nCumsumPer-0.001).idxmin()] TR2 = pCumsumPer[abs(nCumsumPer-0.005).idxmin()] TR3 = pCumsumPer[abs(nCumsumPer-0.01).idxmin()] return 0.4 * TR1 + 0.3 * TR2 + 0.3 * TR3 tpr_weight_funtion(y_train,resu_1)
然后是测试集
#%%测试集 test['tiqu'] = test.DWYJCE*12*2-test.GRZHDNGJYE test['DKFFE_DKYE'] = test.DKYE/test.DKFFE test['GRJCJS_bin'] = pd.cut(test.GRJCJS,bins=[-inf, 1197.25, 3745.75, 4489.25, 9801.75, 12446.0, inf]) test['GRZHYE_bin'] = pd.cut(test.GRZHYE,bins=[-inf, 1324.0175, 5607.4651, 16688.3525, 25816.3701, 39361.7637, 65252.7266, inf]) test['GRZHSNJZYE_bin'] = pd.cut(test.GRZHSNJZYE,bins=[-inf, 240.7625, 397.5475, 21479.625, 30042.8545, inf]) test['GRZHDNGJYE_bin'] = pd.cut(test.GRZHDNGJYE,bins=[-inf, 204.94, 237.5275, 3905.64, 4846.5601, 6378.79, inf]) test['DWYJCE_bin'] = pd.cut(test.DWYJCE,bins=[-inf, 351.595, 657.11, 739.3075, 1384.8, 1702.08, inf]) test['DKFFE_bin'] = pd.cut(test.DKFFE,bins=[-inf, 129487.0, 168487.0, 250487.0, 339987.0, inf]) test['DKYE_bin'] = pd.cut(test.DKYE,bins=[-inf, 237.0875, 40012.8418, 63379.4609, 113304.7031, 141377.0547, 150237.0547, 272994.5781, inf]) test['age_bin'] = pd.cut(test.age,bins=[-inf, 10.0, 29.5, 31.5, 32.5, 34.5, 35.5, 48.5, inf]) test['tiqu_bin'] = pd.cut(test.tiqu,bins=[-inf, 6500.6951, 9509.8101, 14111.0801, 15543.5, 22686.7305, inf]) test['DKFFE_DKYE_bin'] = pd.cut(test.DKFFE_DKYE,bins=[-inf, 0.5167, 0.7419, 0.8772, 0.9046, 0.929, 0.9385, 0.9727, inf]) #%%建模 cate_iv_woedf.bin2woe(test,iv_col) model_col.remove('label') test.isnull().sum() model_data_1 = test[model_col] model_data_1 = model_data_1.astype(float) X4 = sm.add_constant(model_data_1) resu = result.predict(X4.astype(float))
最终结果才0.305,我看auc还是不错的,但是结果就是,这样,最高的那位好像达到了0.615
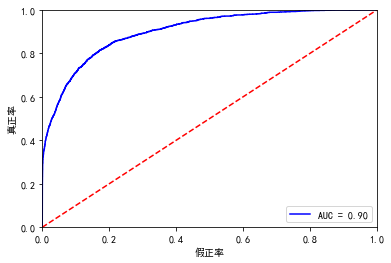
目前没有时间去做了,等过年再慢慢研究吧