一、标签为数值变量
一般常见于回归相关的问题。
1.1类别变量+数值标签
关于类别变量与数值标签的关系,我们一般会观察下面的结果。
- 每个类别情况下对应的均值,这个可以直接使用pandas进行绘制;
- 均值反映的信息并不十分详细,如果希望得到更加具体的分布,可以使用boxplot进行绘制。
如果不同类别之间的标签分布相差较大,则说明该类别信息是非常有有价值的,如果所有类别的标签都是一样的分布,则该类别信息的区分度相对较低。
数据链接 https://tianchi.aliyun.com/competition/entrance/231784/information,可以看我另一篇文章:https://www.cnblogs.com/cgmcoding/p/13279789.html
1. pandas直接绘图
手动挡和自动挡的价格分布
#%%导入模块 import pandas as pd import numpy as np from scipy import stats import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline plt.rc("font",family="SimHei",size="12") #解决中文无法显示的问题 import pycard as pc #波士顿房价数据集 df = pd.read_csv('D:/迅雷下载/used_car_train_20200313.csv',sep=' ') var = 'gearbox' label = 'price' df.groupby(var)[label].mean().plot(kind = 'bar')

2. boxplot绘图
plt.figure(figsize=[10,6])
sns.boxplot(x=var, y=label, data=df)
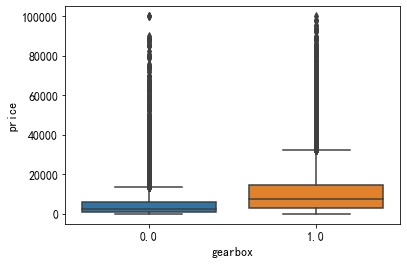
但是当该特征的类别特别多的时候,不建议画图
1.2数值变量+数值标签
关于数值变量与数值标签的关系,我们一般会观察下面的结果。
- 数值特征与数值标签的pearson相关系数;如果该数值的绝对值越大,往往说明该特征能为模型带来非常大的帮助。
- 观察数值特征与数值标签的时候,一般采用散点图即可,也可以使用regplot绘制出拟合的曲线。
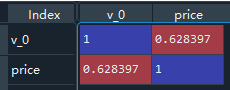
1. person相关系数
df[['v_0',label]].corr('pearson')
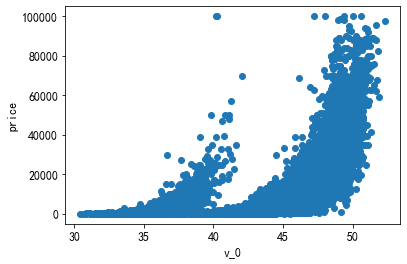
2. scatter绘图
plt.scatter(x='v_0', y = label, data = df); plt.xlabel('v_0') plt.ylabel(label)
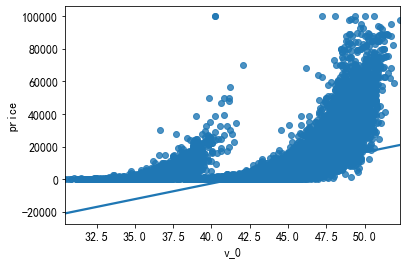
3. regplot绘图
sns.regplot(x=df['v_0'] , y=df[label])
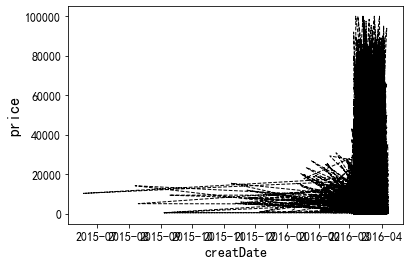
1.3 时间变量+数值标签
关于时间与数值标签,我们主要希望随着时间变化,数据是否表现除了某些特殊的模式(周期性等),以及是否出现了明显的异常现象等等。时间变量与数值变量的可视化直接使用plot函数即可。
1. plot绘图
df['creatDate'] = pd.to_datetime(df['creatDate'], format='%Y%m%d', errors='coerce') plt.plot(df.creatDate, df[label].values, color='black', linestyle='--', linewidth='1', label=label) plt.xlabel('creatDate', fontsize=14) plt.ylabel(label, fontsize=16)
二、标签为二元变量
一般常见于二分类问题。
2.1 类别变量+二元标签
关于类别变量与二元标签的关系可以直接通过barplot函数进行可视化,如果不同类之间的分布差不大,那说明该类别变量大概率是意义不大的。
df = pd.read_csv('E:/谷歌下载/seaborn-data-master/titanic.csv') var = 'pclass' label = 'survived' df.groupby(var)[label].mean() ''' pclass 1 0.629630 2 0.472826 3 0.242363 Name: survived, dtype: float64 '''
画图
sns.barplot(x=var, y=label , data=df)

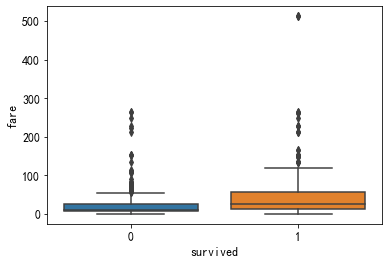
2.2 数值变量+二元标签
数值变量与二元标签的关系一般可以通过下面的两种方式分析:
- 对数值变量进行分桶,然后基于类别变量与二元标签的关系进行分析;
- 使用boxplot函数,观测在不同标签下,数值特征的分布差异。
sns.boxplot(df[label], df['fare'])
2.3标签为N(>2)元类别变量
也就是我们常说的多分类问题。在观测标签为多分类的问题时,因为标签是多个类别的,我们可以通过两种策略对其进行观察。
- 将多分类转化为多个二分类然后进行观测,这么做最大的问题是我们需要分析量大大增加了,会使得问题变得更加繁琐;
- 采用和数值变量+二元标签的策略对模型进行观测。
''' 随机模拟产出多分类标签 ''' multi_label = 'y_generated' df['y_generated'] = np.random.randint(low =0.5, high = 3.5, size = df.shape[0])
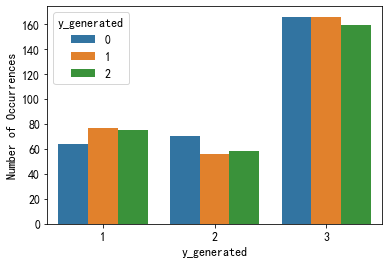
3.1 类别变量+N标签
直接使用countplot,将hue的位置设置为标签的名称即可。
sns.countplot(x='pclass', hue=multi_label, data=df) plt.ylabel('Number of Occurrences', fontsize=12) plt.xlabel(multi_label, fontsize=12) plt.show()
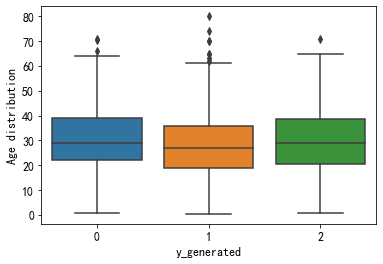
3.2 数值变量+N元标签
直接使用boxplot即可,观测在每个类处数值变量的分布情况。如果所有类处的数值变量分布都类似,那可能该数值变量带来的影响会相对较小,反之影响较大。
sns.boxplot(x=multi_label, y='age', data=df) plt.ylabel('Age distribution', fontsize=12) plt.xlabel(multi_label, fontsize=12) plt.show()
文章参考:https://mp.weixin.qq.com/s/yPhrYp7gL28W5H5GatmCXA,只做笔记,不做商业用途