1.中文分词器:
第一步在solrhome下面的schema.xml下配置中文分词的域:
<fieldType name="text_ik" class="solr.TextField">
<analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
<field name="text_ik" type="text_ik" indexed="true" stored="true" multiValued="false" />
<field name="content_ik" type="text_ik" indexed="true" stored="true" multiValued="true" />
第二步:导jar包:IKAnalyzer2012FF_u1.jar,放在web-inf下面的lib文件夹下面。
第三步:配置资源,在web-inf下面建一个classes文件,新建IKAnalyzer.cfg.xml文件,里面内容:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic;</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">stopword.dic;</entry>
</properties>
看你需要几个自定义的扩展字典,因为这个ik分词器现在也没有跟新了,很多网络词汇也没收录,所以我们需要自己扩展,
 这个文件也放在classes下面,里面的字典自己定义。
这个文件也放在classes下面,里面的字典自己定义。
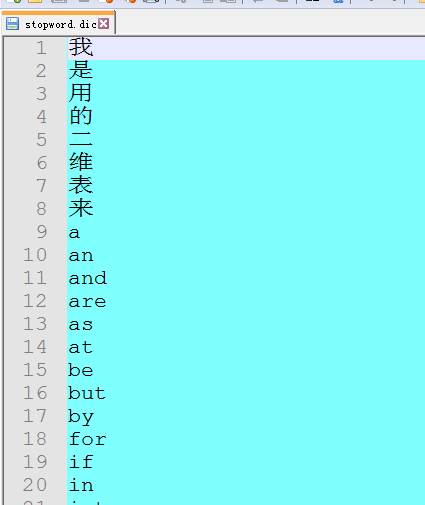 也可以自己去定义,
也可以自己去定义,
接下来重启tomcat就行了,好我们来看看效果
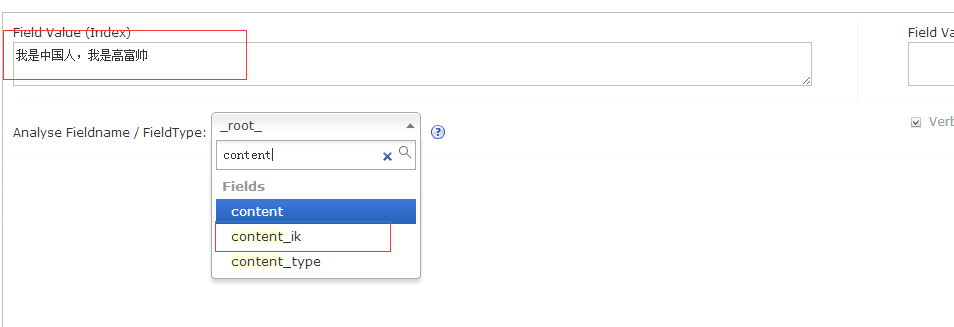
注意,我这里只添加了两个采用ik分词器的分词的域,记得选择对,看看结果:
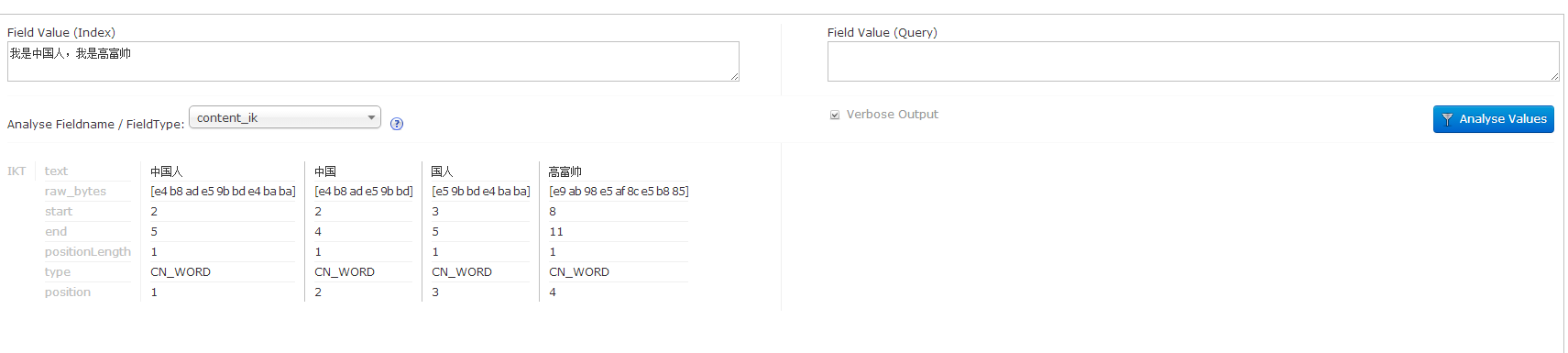
好,中文分词就介绍到这里。
第二部分:后台管理页面导入数据:
第一步:在solrhome下面的collection1下面加lib文件夹:放下面三个包,MySQL的自己去别的项目下载,solr的在D:solrsolr-4.10.3dist,下面找,

第二步:在D:solrsolrhome4.1collection1conf下面的solrconfig.xml下面加
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">data-config.xml</str>
</lst>
</requestHandler>
注明:data-config.xml可以随便取名字,接下来在D:solrsolrhome4.1collection1conf 建一个刚刚solrconfig.xml中配置的那个名字,
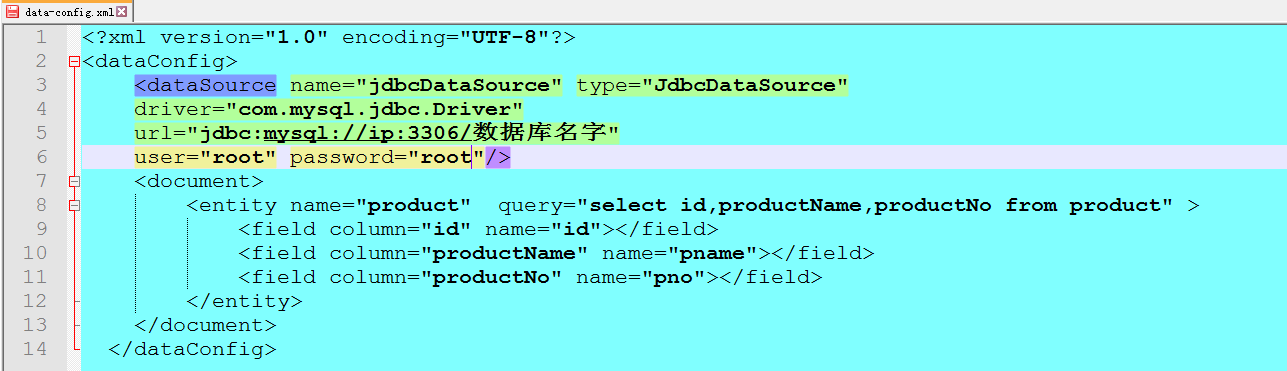
<?xml version="1.0" encoding="UTF-8"?>
<dataConfig>
<dataSource name="jdbcDataSource" type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://ip:3306/数据库名字"
user="root" password="root"/>
<document>
<entity name="product" query="select id,productName,productNo from product" >
<field column="id" name="id"></field>
<field column="productName" name="pname"></field>
<field column="productNo" name="pno"></field>
</entity>
</document>
</dataConfig>
id必须有,column是数据库的字段,name是域,但是我们的schema.xml是没有这两个域的,需要自己添加,我这里添加的是使用ik分词的,
<field name="pname" type="text_ik" indexed="true" stored="true" multiValued="true" />
<field name="pno" type="text_ik" indexed="true" stored="true" multiValued="true" />
<field name="product_keyworlds" type="text_ik" indexed="true" stored="false" multiValued="true" />
<copyField source="pname" dest="product_keyworlds"/>
<copyField source="pno" dest="product_keyworlds"/>
添加了复制域,就是我们前台页面传来的我们可以通过这个区搜索,不用再去指定域了,还需要判断,直接指定到product_keywords就行了。
好,配置完成。
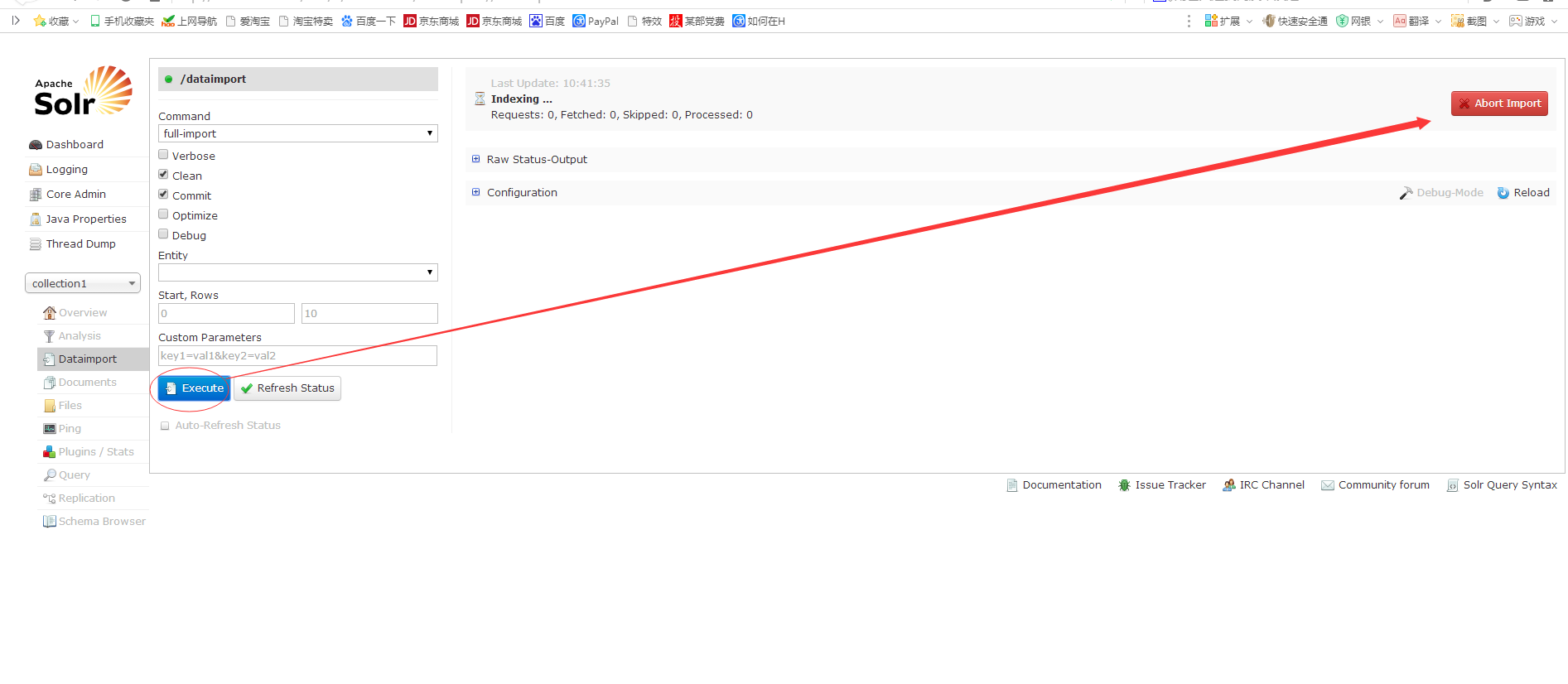
测试,好正在建索引,索引位置在collection1下面的data下面的index下面。
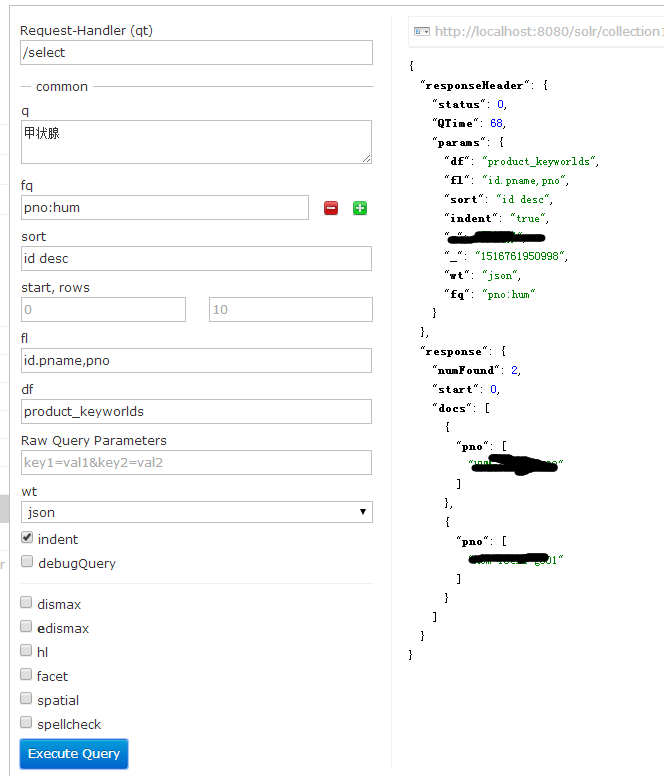
注:也可以按照价格按区间查询,比如添加过滤条件,fq price:[10 TO *]大于等于10的所有
好结果查询出来了。到这里是不是觉得学会solr了呢,还远远不够,我们需要使用solrj,下篇就是对solrj的使用。