A Tutorial on Network Embeddings
NE 的中心思想就是找到一种映射函数,该函数将网络中的每个节点转换为低维度的潜在表示
典型例子 DeepWalk:
其学习 Zachary’s Karate network 网络中的拓扑结构信息并转换成一个二维的潜在表示(latent representation)
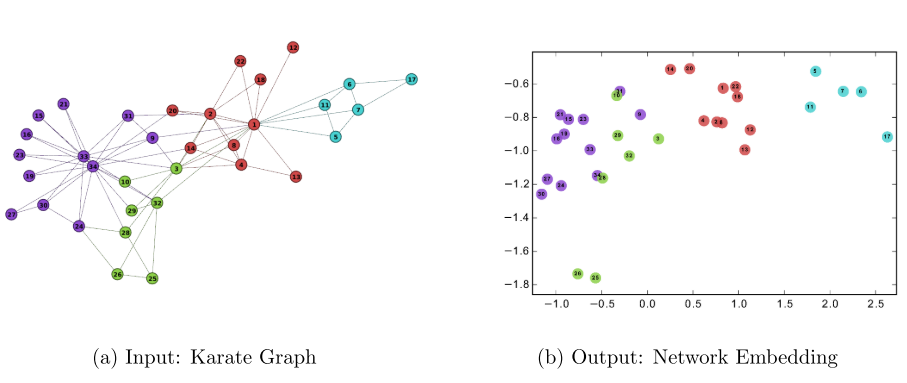
目标
- 适应性
- 随着网络发展,新的表示不需要重复学习
- 可扩展
- 短时间处理较大规模网络
- 社区感知
- 潜在节点间的距离可用于评估网络节点间的相似性度量
- 低维
- 标记数据稀疏时,低维模型能够更好的推广,并加速收敛和推理
- 持续
- 需要潜在的表示在连续的空间内模拟社区成员关系,连续的表示使社区有更平滑的边界,促进分类
此文包含
- 无监督网络嵌入方法在无特征的同质网络的应用
- 调研特征网络和部分标记网络中的网络嵌入
- 讨论异构网络嵌入方法
网络嵌入发展
传统意义的Graph Embedding
- 降维
- PCA
- 多维缩放(MDS)
- 将特征矩阵 M 的每一行投影到k 维向量,保留k 维空间中原始矩阵中不同对象距离
- Isomap 算法
- (MDS 的扩展)通过将每个节点与特定距离内的节点连接构造邻域图,以保持非线性流形的整体结构
- 局部线性嵌入( LLE )
这些方法都在小型网络上提供良好性能,但其时间复杂度至少为二次,故无法在大规模网络上运行
深度学习
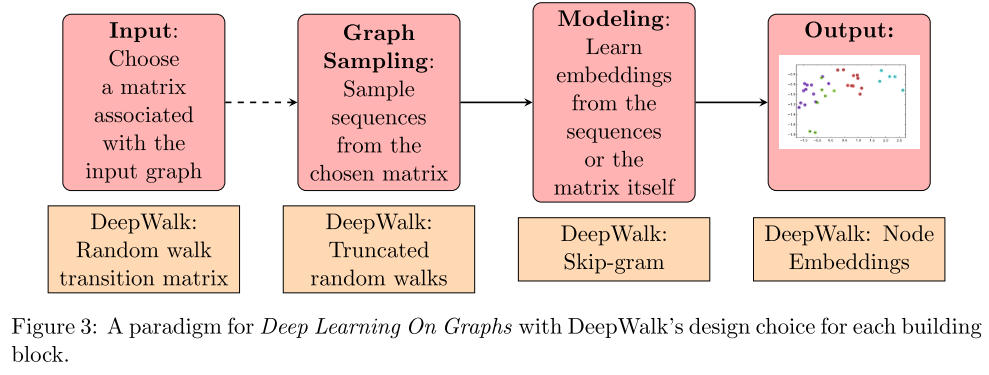
- DeepWalk
- 通过将节点视为单词并生成短随机游走作为句子来弥补网络嵌入和单词嵌入的差距。然后,可以将诸如 Skip-gram 之类的神经语言模型应用于这些随机游走以获得网络嵌入。
- 按需生成随机游走。skim-gram 针对每个样本进行了优化
- DeepWalk 是可扩展的,生成随机游走和优化 Skip-gram 模型的过程都是高效且平凡的并行化
- 引入了深度学习图形的范例
无向网络的网络嵌入

- LINE
- 为了更好的保存网络的结构信息,提出了一阶相似度和二阶相似度的概念,并在目标函数中结合了两者
- 使用广度优先算法,只有距离给定节点最多两跳的节点才被视为相邻节点
- 使用负抽样 skip-gram
- Node2vec
- 反映网络的结构
- deepwalk 的扩展(deepwalk 完全时随机的),引入偏向的随机游走,增加 p,q 两个参数,p(控制访问走过的node,即往回走,q 控制没走过的node ,向外走)
- DeepWalk和node2vec算法是先在网络中随机游走,得到node的序列。两个node同时出现在一个序列中的频率越高,两个node的相似度越高。然后构建一个神经网络,神经网络的输入是node,输出是其他node与输入的node同时出现的概率。同时出现的概率越高,两个node的相似度越高。为了保持相似度一致,得到目标函数
- Walklets
- 不要游走,跳过!在线学习多尺度网络嵌入
- 进一步学习节点不同权重的网络嵌入,以不同的粒度捕获网络的结构信息。
- GraRep
- 通过将图形邻接矩阵提升到不同的幂来利用不同尺度的节点共现信息,将奇异值分解(SVD)应用于邻接矩阵的幂以获得节点的低维表示
- GraphAttention
- 不是预先确定超参数来控制上下文节点分布,而是自动学习对图转换矩阵的幂集数的关注
- 通过设置隐藏层,这些层里的节点能够注意其邻近节点的特征,我们能够(隐含地)为邻近的不同节点指定不同的权重,不需要进行成本高昂的矩阵运算(例如反演),也无需事先知道图的结构
- SDNE
- https://blog.csdn.net/wangyang163wy/article/details/79698563
- 通过深度自动编码器保持 2 跳邻居之间的接近度。它通过最小化它们的表示之间的欧几里德距离来进一步保持相邻节点之间的接近度
- 具有多层非线性函数,从而能够捕获到高度非线性的网络结构。然后使用一阶和二阶邻近关系来保持网络结构。二阶邻近关系被无监督学习用来捕获全局的网络结构,一阶邻近关系使用监督学习来保留网络的局部结构
- DNGR
- 基于深度神经网络的学习网络嵌入的方法
改进
HARP
- network embedding的时候保持网络高阶的结构特征,具体的做法是通过将原网络图进行合并,合并为多个层次的网络图
- 通过递归地粗粒化方式,将原网络图的节点和边通过合并划分成一系列分层的结构更小的网络图,然后再利用现有的算法进行不断的特征提取,从而实现最终的network embedding特征提取
特征网络嵌入( Attributed Network Embeddings )
无监督网络嵌入方法仅利用网络结构信息来获得低维度的网络特征。但是现实世界网络中的节点和边缘通常与附加特征相关联,这些特征称为属性(attribute)。
例如在诸如 Twitter 的社交网络站点中,用户(节点)发布的文本内容是可用的。因此期望网络嵌入方法还从节点属性和边缘属性中的丰富内容中学习
挑战:特征的稀疏性,如何将它们合并到现有的网络嵌入框架中
方法:
- TADW
- Network repre- sentation learning with rich text information
- 研究节点与文本特征相关联情况,首先证明了deepwalk 实质上是将转移概率矩阵 分解为两个低维矩阵,它将文本矩阵合并到矩阵分解过程中
联合建模网络结构和节点特征
- CENE
- 结合网络结构和节点特征
- 将文本内容视为特殊类型的节点,并利用节点-节点链接和节点内容链接进行节点嵌入。 优化目标是共同最小化两种类型链路的损失。
节点标签,引文网络中的出版地和日期等
典型方法是:优化用于生成节点嵌入和用于预测节点标签的损失
- GENE
- 将组的信息考虑到Network Embedding学习中,同一组的节点即使直接没有边,一般也会存在一些内在关系
- 每个相同的组也会学到一个向量表示,组向量有两个用处:1)在利用周围节点预测中心节点时,组向量也会加入预测; 2)组向量也会预测组中的其他节点。最后目标函数是将上述两项相加而成
- Max margin DeepWalk(MMDW)
- 第一部分是基于矩阵分解的节点嵌入模型
- 第二部分是将学习的表示作为特征来训练标记节点上的最大边缘 SVM 分类器。通过引入偏置梯度,可以联合更新两个部分中的参数。
异构网络嵌入
- Chang [13] 提出了异构网络的深度嵌入框架
- 为每种模态(如图像,文本)构建一个特征表示,然后将不同模态的嵌入映射到同一个嵌入空间
- 优化目标:最大化链接节点嵌入间的相似性、最小化未链接节点的嵌入