此文转自: https://zhuanlan.zhihu.com/p/34629262
Unity对Shader文件进行编译的时候,DX9和DX11的版本会直接生成汇编码。
length(i.worldPos)DX9
dp4 r0.x, v0, v0
rsq r0.x, r0.x
rcp_pp oC0, r0.xDX11
dp4 r0.x, v1.xyzw, v1.xyzw
sqrt o0.xyzw, r0.xxxx
由于这些代码是最终的指令,大部分指令执行时间是“差不多”的,可以用来预估计算量。但移动平台则是各厂商驱动各自进行的编译,各家都不一样,不好判断。
但DX9毕竟针对的是非常古老的硬件,很难想象现代GPU还会和它保持一样。实际的指令应该会更接近于DX11。
以下为列表(用|隔开的数据,前面的部分是计算单分量时的指令数,后面的部分是计算float4时的指令数)
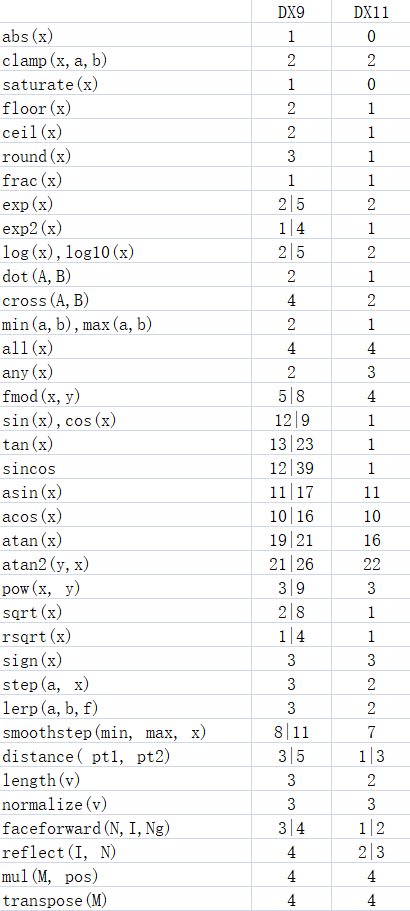
总结一下便是:
- 反三角函数非常费
- abs和saturate是免费的
- 除了反三角函数外,fmod和smoothstep比预期更费
- log,exp,sqrt(单分量)的成本实际上很低,所以由他们组合成的pow也不高
- sin,cos在DX11使用了专门一条单指令,成为了低成本函数
另外还有个基本常识:绝大部分GPU是一次性计算4个分量,计算一个float4和只计算单个float耗时是一样的。当计算float时,剩下三个分量的时长会被浪费。
然而,每条指令的时间成本确实可能是不一样的。这个和具体硬件有关。
很难找到移动平台具体GPU的数据,可以参考下文看看一些主流GPU的情况,相信他们总是有一些共性的。
shader function or instruction cost (performance)
结果是,1/x, sin(x), cos(x), log2(x), exp2(x), 1/sqrt(x)这些指令的时间成本是一样的,而且和普通的四则运算很接近(个人猜测是通过查表实现的)。
但是sin,cos毕竟在旧硬件上成本较高,由于不清楚硬件的具体情况,还是要尽可能少用。
预估成本还有一个办法,是根据公开的GPU的GFLOPS(Floating-point Operations Per Second每秒执行浮点运算次数)

来评估每个着色器理论极限算力,便能知道一个着色器里可以允许多少条基本指令。
这当然很不精确,因为纹理采样,顶点,光栅化等等众多成本都没有考虑在内,但是有一定的参考价值。
iPhone 4s使用的芯片是Apple A5,它的FLOPS是12.8G,屏幕分辨率是960x640,分到一帧的一个像素后,结果是
12.8*1024^3/960/640/60 = 372。
根据FLOPS的定义,时间最短的基本指令“乘加(MAD)”需要花掉2FLOPS,那么单个屏幕像素能执行186条指令。
假设Overdraw是5,那么一个像素着色器能执行37指令。
虽然37指令这个结果显然比实际多多了,但起码是在合适的数量级范围内。可以通过帧率测试来计算“损耗比例”到底是多少。
而且,这样做我们其实得到了一个上限值。如果你在像素单元的指令数超过了37(比如用了两次atan2),那从物理角度是绝对不可能达到满帧的。