这东西套路性极强,我记录一下自己的一个作业做模板。
1.给了个文本格式数据源:index wares price number
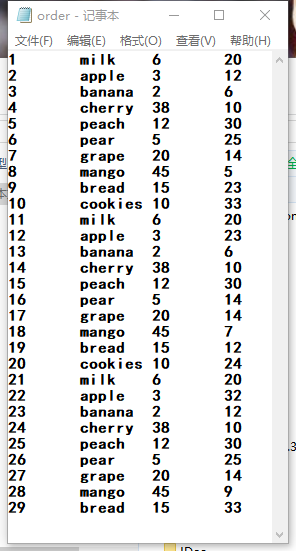
2.要求计算每种商品的总价格,并且以 商品 , 总数量, 总价, 的格式输出
3.具体代码
Oder类
1 package oracle.oder; 2 import org.apache.hadoop.io.Writable; 3 import java.io.DataInput; 4 import java.io.DataOutput; 5 import java.io.IOException; 6 7 /** 8 * 1实现writable接口 重写序列化和反序列化方法 9 * 2根据业务需求,设计类中的属性 10 * 3生成setter和getter方法 11 * 4生成空参构造 ,给反序列化用 12 * 5生成gotring(0 自定义输出格式 13 * 6实现序列和反序列方法 14 */ 15 public class Oder implements Writable { 16 17 private long price; 18 private long number; 19 private long sumprice; 20 21 public Oder() { 22 23 } 24 25 @Override 26 public String toString() { 27 return price + 28 " " + number + 29 " "+ sumprice 30 ; 31 } 32 33 public void write(DataOutput out) throws IOException { 34 35 out.writeLong(price); 36 out.writeLong(number); 37 out.writeLong(sumprice); 38 } 39 40 public void readFields(DataInput in) throws IOException { 41 42 price=in.readLong(); 43 number=in.readLong(); 44 sumprice=in.readLong(); 45 } 46 47 public long getPrice() { 48 return price; 49 } 50 51 public void setPrice(long price) { 52 this.price = price; 53 } 54 55 public long getNumber() { 56 return number; 57 } 58 59 public void setNumber(long number) { 60 this.number = number; 61 } 62 63 public long getSumprice() { 64 return sumprice; 65 } 66 67 public void setSumprice(long sumprice) { 68 this.sumprice = sumprice; 69 } 70 }
OderMapper类
package oracle.oder;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OderMapper extends Mapper<LongWritable, Text, Text,Oder> {
Text k = new Text();
Oder oder = new Oder();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1获取一行数据
String line = value.toString();
//2切割一行数据
String[] fields = line.split(" ");
//3封装一个对象
//3.1封装key(商品名称)
k.set(fields[1]);
//3.2封装value
//封装价格
long price= Long.parseLong(fields[fields.length-2]);
//封装数量
long number= Long.parseLong(fields[fields.length-1]);
oder.setPrice(price);
oder.setNumber(number);
//4写出
context.write(k,oder);
}
}
OderReduce类
package oracle.oder;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OderReduce extends Reducer<Text,Oder,Text,Oder>{
@Override
protected void reduce(Text key, Iterable<Oder> values, Context context) throws IOException, InterruptedException {
//求和
//数量累加
//针对相同商品数量求和
long sum_number = 0;
long price_ = 0;
for (Oder oder : values) {
sum_number += oder.getNumber();
price_=oder.getPrice();
}
Oder v = new Oder();
v.setPrice(price_);
v.setNumber(sum_number);
v.setSumprice(sum_number * price_);
//输出
context.write(key,v);
}
}
OderDriver类
package oracle.oder;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OderDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//封装输出输入路径
args = new String[]{"C:/Users/未云/桌面desktop/大数据搭建/作业/input", "C:/Users/未云/桌面desktop/大数据搭建/作业/output"};
System.setProperty("hadoop.home.dir", "E:/hadoop-2.7.2/");
//1获取job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2设置jar加载路径
job.setJarByClass(OderDriver.class);
//3关联mapper和reducer
job.setMapperClass(OderMapper.class);
job.setReducerClass(OderReduce.class);
//4设置map输出的key和value
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Oder.class);
//5设置最终输出的key和value
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Oder.class);
//6设置输入路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//7提交job
boolean result=job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
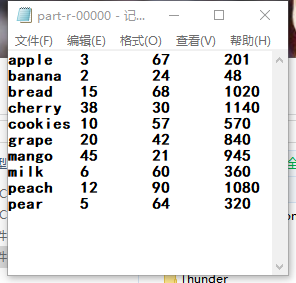
4.输出效果
感谢闫老师
15:51:08