0 MapReduce的定义
- 源自于Google的MapReduce论文
- 发表于2004年12月
- Hadoop MapReduce是Google MapReduce克隆版
- MapReduce特点
- 易于编程
- 良好的扩展性
- 高容错性
- 适合PB级以上海量数据的离线处理
- MapReduce不擅长的方面
- 实时计算
- 像MySQL一样,在毫秒级或者秒级内返回结果
- 流式计算
- MapReduce的输入数据集是静态的,不能动态变化
- MapReduce自身的设计特点决定了数据源必须是静态的
- DAG计算
- 多个应用程序存在依赖关系,后一个应用程序的
- 输入为前一个的输出
- 实时计算
1 MapReduce编程模型--Wordcount实例
- 场景:有大量文件,里面存储了单词,且一个单词占一行
- 任务:如何统计每个单词出现的次数?
- 类似应用场景:
- 搜索引擎中,统计最流行的K个搜索词;
- 统计搜索词频率,帮助优化搜索词提示
- 三种问题
- Case 1:整个文件可以加载到内存中;sort datafile | uniq -c;
- Case 2:文件太大不能加载到内存中,但每一行<word, count>可以存放到内存中;
- Case 3:文件太大无法加载到内存中,且<word, count>也不用保存在内存中;
- 将三种问题范化为:有一批文件(规模为TB级或者 PB级),如何统计这些文件中所有单词出现的次数;
- 方案:首先,分别统计每个文件中单词出现次数,然后累加不同文件中同一个单词出现次数;
- 典型的MapReduce过程。
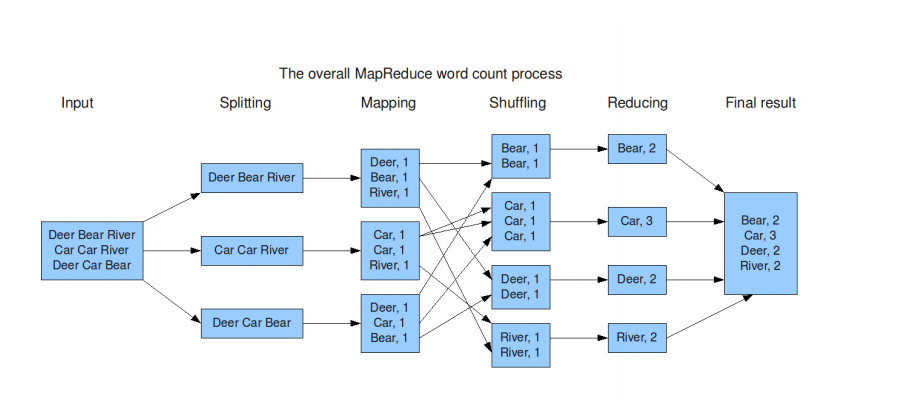
input阶段,我们取出文件中的一些数据
splitting阶段,我们将取出的单词进行分片
Mapping阶段,将单词进行统计,可以看出统计结果中有很多重复的结果
Shuffling阶段,进行hash分片,放入对应的桶,这样我们需要的结果就是每一个桶放的数据进行了归类
Reducing阶段,进行数据整合,求出每个词的出现的次数
Final result阶段,最后获取到的结果
map(key, value):
// key: document name(文件名字); value: text of document(文件内容)
for each word w in value:(循环处理每一个行数据)
emit(w, 1)
reduce(key, values):
// key: a word(一个词); values: an iterator over counts(这个词出现次数的集合list)
result = 0
for each count v in values:(对出现次数集合进行处理)
result += v
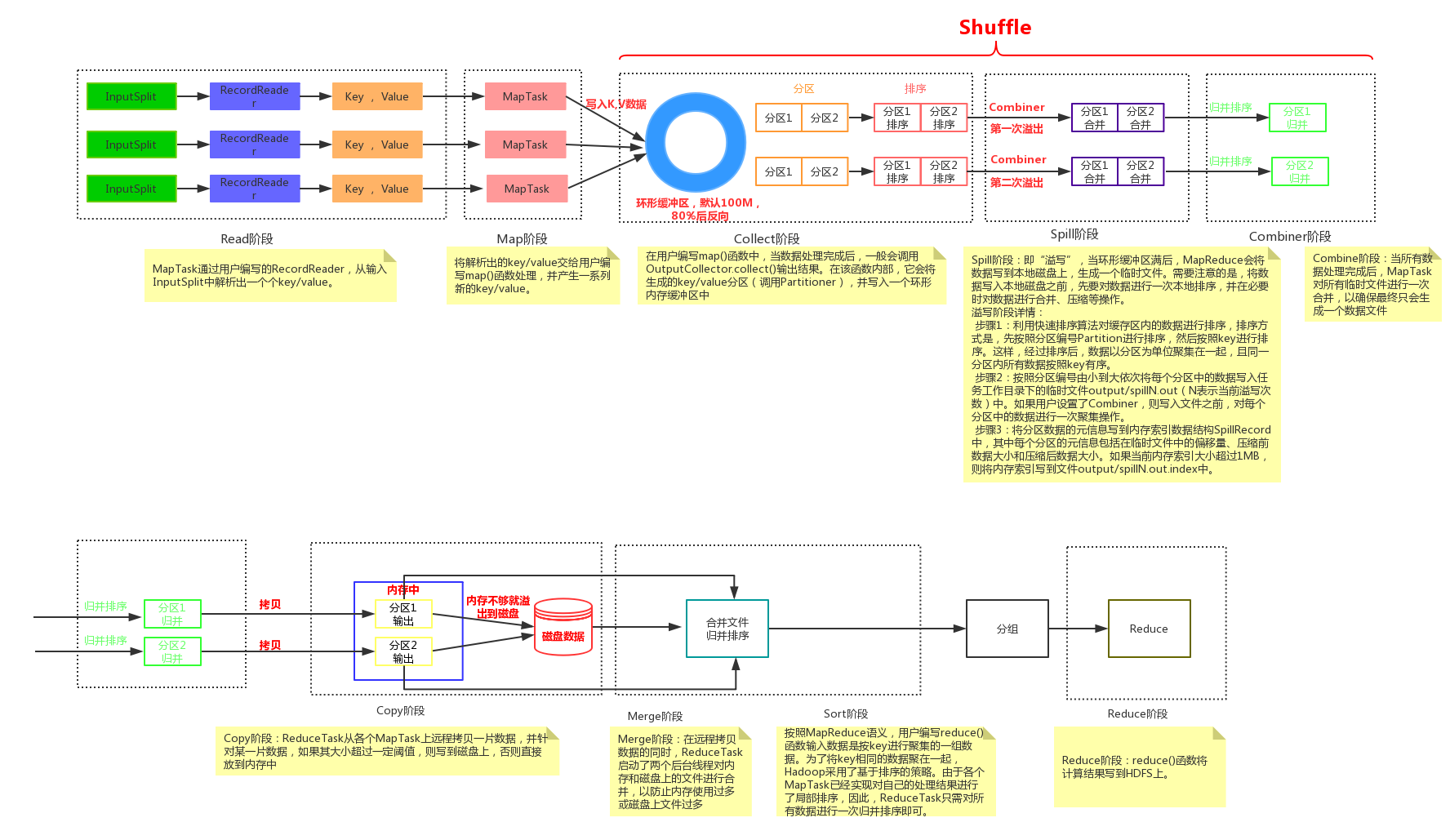
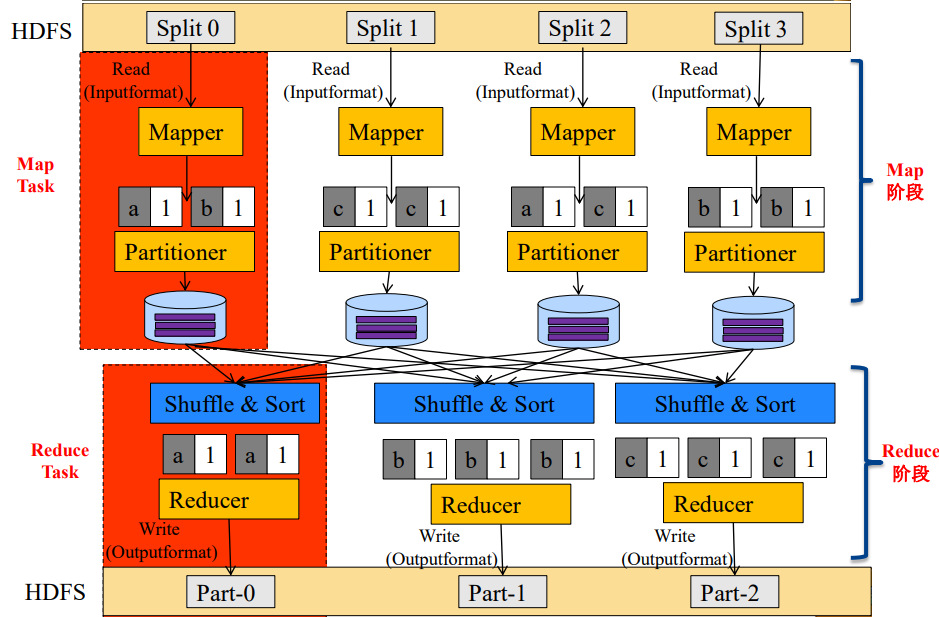
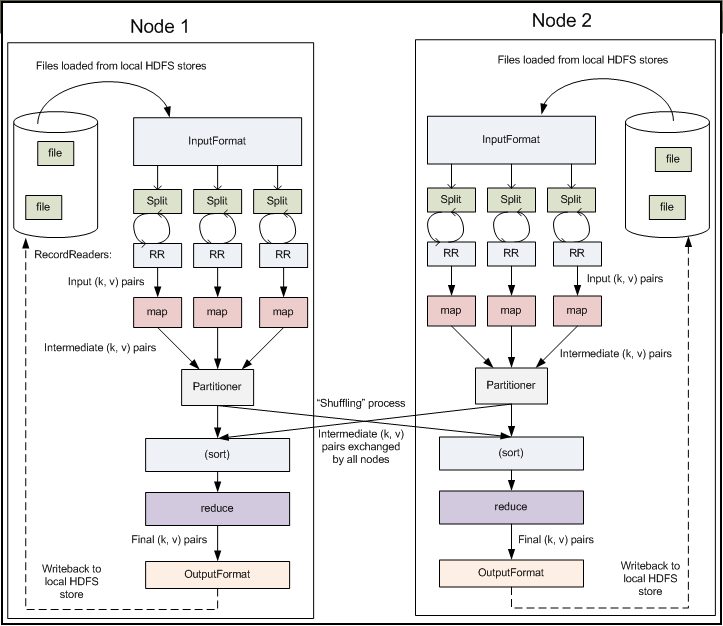
emit(key,result)- MapReduce将作业的整个运行过程分为两个阶段:Map阶段和Reduce阶段
- Map阶段由一定数量的
Map Task组成- 输入数据格式解析:
InputFormat - 输入数据处理:
Mapper - 数据分组:
Partitioner
- 输入数据格式解析:
- Reduce阶段由一定数量的
Reduce Task组成- 数据远程拷贝
- 数据按照key排序
- 数据处理:
Reducer - 数据输出格式:
OutputFormat
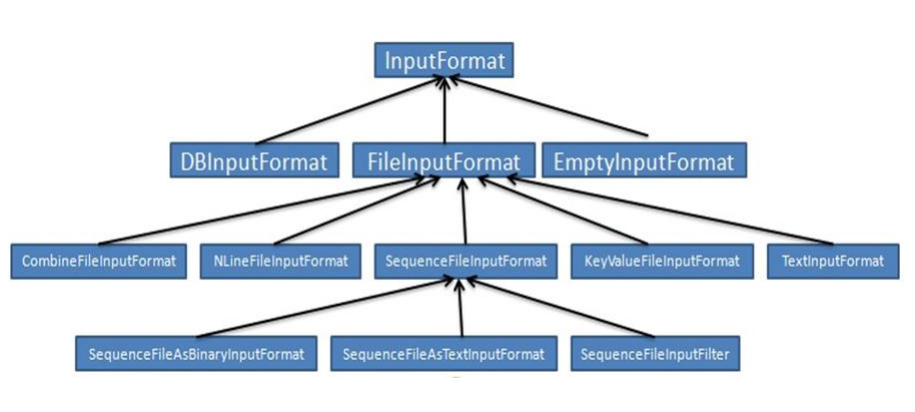
- InputFormat
- 文件分片(InputSplit)方法
- 处理跨行问题
- 将分片数据解析成key/value对
- 默认实现是TextInputFormat
- TextInputFormat
- Key是行在文件中的偏移量,value是行内容
- 若行被截断,则读取下一个block的前几个字符
- 文件分片(InputSplit)方法
- Split与Block
- Block
- HDFS中最小的数据存储单位
- 默认是64MB
- Spit
- MapReduce中最小的计算单元
- 默认与Block一一对应
- Block与Split
- Split与Block是对应关系是任意的,可由用户控制
- Block
- Combiner
- Combiner可做看local reducer
- 合并相同的key对应的value(wordcount例子)
- 通常与Reducer逻辑一样
- 好处
- 减少Map Task输出数据量(磁盘IO)
- 减少Reduce-Map网络传输数据量(网络IO)
- 如何正确使用
- 结果可叠加
- Combiner可做看local reducer
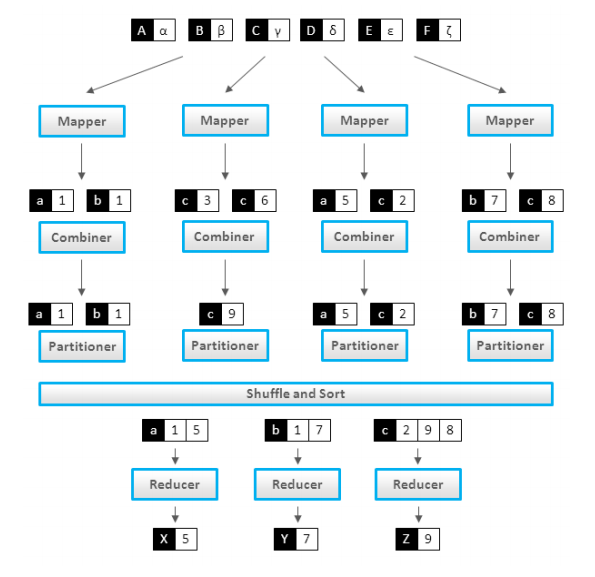
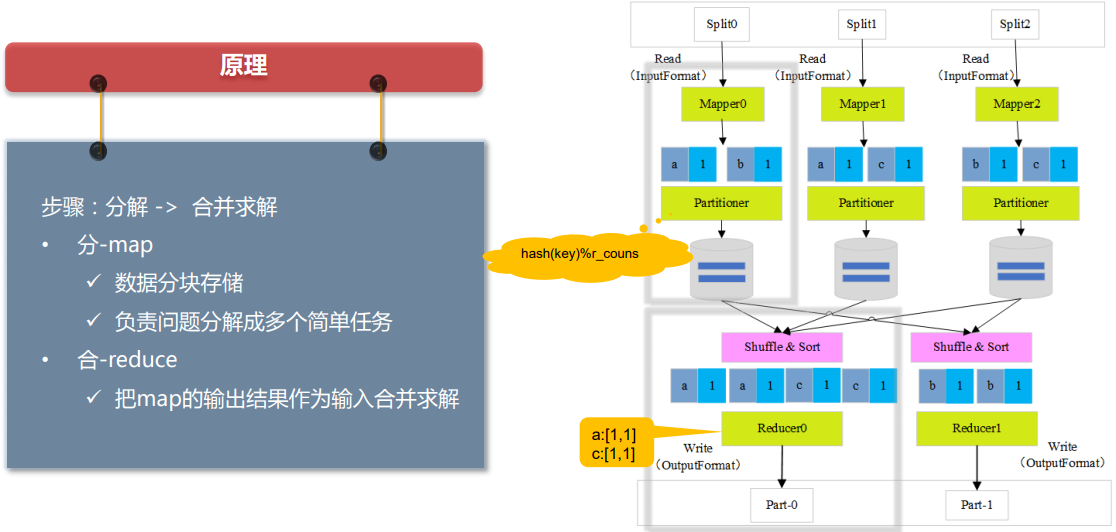
- Partitioner
- Partitioner决定了Map Task输出的每条数据
- 交给哪个Reduce Task处理
- 默认实现:hash(key) mod R
- R是Reduce Task数目
- 允许用户自定义
- 很多情况需自定义Partitioner
- 比如“hash(hostname(URL)) mod R”确保相同域名的网页交给同一个Reduce Task处理
- Partitioner决定了Map Task输出的每条数据
- 编程模型总结
- Map阶段
- InputFormat(默认TextInputFormat)
- Mapper
- Combiner(local reducer)
- Partitioner
- Reduce阶段
- Reducer
- OutputFormat(默认TextOutputFormat)
- Map阶段
2 MapReduce的架构
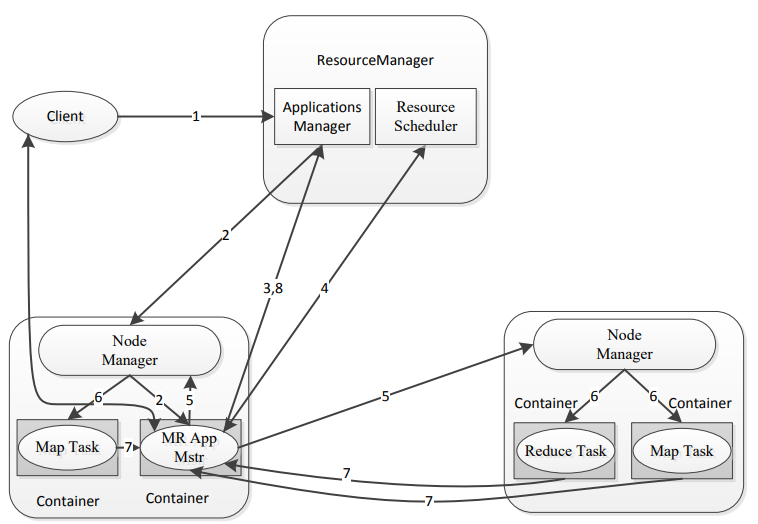
1.客户端发送MR任务到RM上
2.RM分配资源,找到对应的NM,启动对应的Application Master
3.Application Master向Applications Master注册
4.Application Master向Resource Scheduler申请资源
5.找到对应的NM
6.启动对应的Container里的Map Task或者是Reduce Task任务
7.Map Task和Reduce Task对Application Master汇报心跳,任务进度
8.Application Master向Applications Master汇报整体任务进度,如果执行完了Applications Master会将Application Master移除

- 容错性
- MRAppMaster容错性
- 一旦运行失败,由YARN的ResourceManager负责重新启动,最多重启次数可由用户设置,默认是2次。一旦超过最高重启次数,则作业运行失败。
- Map Task/Reduce Task
- Task周期性向MRAppMaster汇报心跳;
- 一旦Task挂掉,则MRAppMaster将为之重新申请资源,并运行之。最多重新运行次数可由用户设置,默认4次。
- MRAppMaster容错性
- 数据本地性

- 什么是数据本地性(data locality)
- 如果任务运行在它将处理的数据所在的节点,则称该任务具有“数据本地性”
- 本地性可避免跨节点或机架数据传输,提高运行效率
- 数据本地性分类
- 同节点(node-local)
- 同机架(rack-local)
- 其他(off-switch)
- 什么是数据本地性(data locality)
- 推测执行机制任务并行执行
- 作业完成时间取决于最慢的任务完成时间
- 一个作业由若干个Map任务和Reduce任务构成
- 因硬件老化、软件Bug等,某些任务可能运行非常慢
- 推测执行机制
- 发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度
- 为拖后腿任务启动一个备份任务,同时运行
- 谁先运行完,则采用谁的结果
- 不能启用推测执行机制
- 任务间存在严重的负载倾斜
- 特殊任务,比如任务向数据库中写数据
- 作业完成时间取决于最慢的任务完成时间

3 常见MapReduce应用场景
- 简单的数据统计,比如网站pv、uv统计
- 搜索引擎建索引
- 海量数据查找
- 复杂数据分析算法实现
- 聚类算法
- 分类算法
- 推荐算法
- 图算法
4 MapReduce编程接口介绍
4.1 MapReduce编程接口
- Hadoop提供了三种编程方式;Java编程接口是所有编程方式的基础;
- Java(最原始的方式)
- Hadoop Streaming(支持多语言)
- Hadoop Pipes(支持C/C++)
- 不同的编程接口只是暴露给用户的形式不同而已,内部执行引擎是一样的;
- 不同编程方式效率不同。
- Java编程接口组成;新API具有更好的扩展性;
- 旧API:所在java包:org.apache.hadoop.mapred
- 新API:所在java包:(org.apache.hadoop.mapreduce)[org.apache.hadoop.mapreduce]
- 两种编程接口只是暴露给用户的形式不同而已,内部执行引擎是一样的;
- 旧API可以完全兼容Hadoop 2.0,但新API不行。
从hadoop 1.0.0开始,所有发行版均包含新旧两类API;
- Hadoop Streaming
- 与Linux管道机制一致
- 通过标准输入输出实现进程间通信
- 标准输入输出是任何语言都有的
- 几个举例:
- cat 1.txt | grep “dong” | sort
cat 1.txt | python grep.py | java sort.jar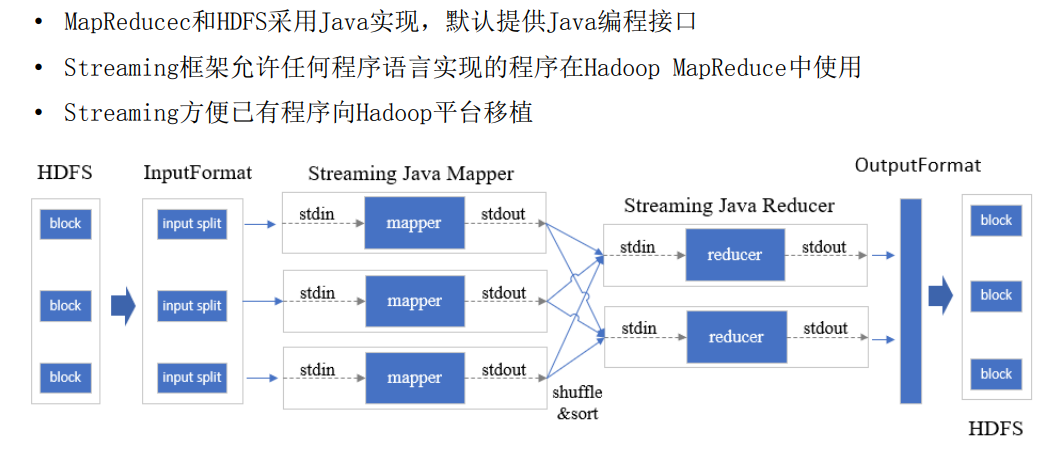
- Hadoop Streaming优缺点

- Hadoop Streaming/pipes

- 数据流

Mapreduce流程