前段时间看了网上开源的DeepQA项目,对于想了解如何实现聊天机器人是个不错的入门之选。本项目制作了语料集作为背景数据集,实现中文聊天机器人。
环境配置:python3.7,IDE是pycharm的windows环境。话不多少,源码如下:https://github.com/chenjj9527/chatbot_Chinese.git
一、中文聊天机器人
1.1、模型构造
聊天机器人大多都是采用seq2seq结构,更细化的说可以指RNN网络或者LSTM网络。模型构造这个函数就是利用TensorFlow框架定义网络模型的结构,如果你对RNN网络或者LSTM网络不是很了解,可以参考https://blog.csdn.net/zzz_cming/article/details/79235475,就可以知道下面RNN网络是怎样识别一句话,其中的cell是怎样的工作原理了。
def get_model(feed_previous=False):
"""
构造模型
"""
learning_rate = tf.Variable(float(init_learning_rate), trainable=False, dtype=tf.float32)
learning_rate_decay_op = learning_rate.assign(learning_rate * 0.9)
encoder_inputs = []
decoder_inputs = []
target_weights = []
for i in range(input_seq_len):
encoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="encoder{0}".format(i)))
for i in range(output_seq_len + 1):
decoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="decoder{0}".format(i)))
for i in range(output_seq_len):
target_weights.append(tf.placeholder(tf.float32, shape=[None], name="weight{0}".format(i)))
# decoder_inputs左移一个时序作为targets
targets = [decoder_inputs[i + 1] for i in range(output_seq_len)]
cell = tf.contrib.rnn.BasicLSTMCell(size)
# 这里输出的状态我们不需要
outputs, _ = seq2seq.embedding_attention_seq2seq(
encoder_inputs,
decoder_inputs[:output_seq_len],
cell,
num_encoder_symbols=num_encoder_symbols,
num_decoder_symbols=num_decoder_symbols,
embedding_size=size,
output_projection=None,
feed_previous=feed_previous,
dtype=tf.float32)
# 计算加权交叉熵损失
loss = seq2seq.sequence_loss(outputs, targets, target_weights)
# 梯度下降优化器
opt = tf.train.GradientDescentOptimizer(learning_rate)
# 优化目标:让loss最小化
update = opt.apply_gradients(opt.compute_gradients(loss))
# 模型持久化
saver = tf.train.Saver(tf.global_variables())
return encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate
1.2、训练数据集加载
先看一下我自己做的问答集,question中的每一个问题依次对应answer中的一个答案,两个文件组成一个问答对构成训练集,
注意:question与answer的行数必须相同,不然会报错,且不能出现空行;
注意:数据集一定要根据需要进行扩充;
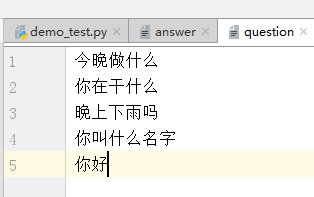

下面的代码就是通过path地址,读取两个数据集中的数据,做一定的必要处理(必要处理在下——第三个小标题),合并到一个train_set中返回:
def get_train_set():
"""
得到训练问答集
"""
global num_encoder_symbols, num_decoder_symbols
train_set = []
with open('./samples/question', 'r', encoding='utf-8') as question_file:
with open('./samples/answer', 'r', encoding='utf-8') as answer_file:
while True:
question = question_file.readline()
answer = answer_file.readline()
if question and answer:
# strip()方法用于移除字符串头尾的字符
question = question.strip()
answer = answer.strip()
# 得到分词id
question_id_list = get_id_list_from(question)
answer_id_list = get_id_list_from(answer)
if len(question_id_list) > 0 and len(answer_id_list) > 0:
answer_id_list.append(EOS_ID)
train_set.append([question_id_list, answer_id_list])
else:
break
return train_set
1.3、构造样本数据
如果我们将所有的数据不加处理直接放入同一个train_set中返回,程序是无法区别哪些是问题哪些是答案、问题的长度读取到哪答案的长度读取到哪——我们需要给问题和答案做一些小标记:
①、我们事先定义好输入、输出的长度,这样读取的长度、输出的长度就固定下来了,程序只需每次通过固定长度就可以取出想要的数据;
②、对于输入长度超标的数据,我们只能选择截断原有的输入——不过我们可以增大输入序列长度啊,这样不就不会被截断了
③、对于长度不够输出序列长度的输出,我们采用末尾添0,保证所有的输入、输出长度都相同;
GO_ID = 1 # 输出序列起始标记 EOS_ID = 2 # 结尾标记 PAD_ID = 0 # 空值填充0 batch_num = 1000 # 参与训练的问答对个数 input_seq_len = 25 # 输入序列长度 output_seq_len = 50 # 输出序列长度
上面就是定义输入、输出序列长度,以及起始标记、结束填充,下面就是构造样本数据函数代码
def get_samples(train_set, batch_num):
"""
构造样本数据:传入的train_set是处理好的问答集
batch_num:让train_set训练集里多少问答对参与训练
# train_set = [[[5, 7, 9], [11, 13, 15, EOS_ID]], [[7, 9, 11], [13, 15, 17, EOS_ID]], [[15, 17, 19], [21, 23, 25, EOS_ID]]]
"""
raw_encoder_input = []
raw_decoder_input = []
if batch_num >= len(train_set):
batch_train_set = train_set
else:
random_start = random.randint(0, len(train_set)-batch_num)
batch_train_set = train_set[random_start:random_start+batch_num]
# 添加起始标记、结束填充
for sample in batch_train_set:
raw_encoder_input.append([PAD_ID] * (input_seq_len - len(sample[0])) + sample[0])
raw_decoder_input.append([GO_ID] + sample[1] + [PAD_ID] * (output_seq_len - len(sample[1]) - 1))
encoder_inputs = []
decoder_inputs = []
target_weights = []
for length_idx in range(input_seq_len):
encoder_inputs.append(np.array([encoder_input[length_idx] for encoder_input in raw_encoder_input], dtype=np.int32))
for length_idx in range(output_seq_len):
decoder_inputs.append(np.array([decoder_input[length_idx] for decoder_input in raw_decoder_input], dtype=np.int32))
target_weights.append(np.array([
0.0 if length_idx == output_seq_len - 1 or decoder_input[length_idx] == PAD_ID else 1.0 for decoder_input in raw_decoder_input
], dtype=np.float32))
return encoder_inputs, decoder_inputs, target_weights
1.4、训练过程
训练过程就是激活TensorFlow框架,往模型中feed数据,并得到训练的loss,最后是保存参数
def train():
"""
训练过程
"""
train_set = get_train_set()
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model()
sess.run(tf.global_variables_initializer())
# 训练很多次迭代,每隔100次打印一次loss,可以看情况直接ctrl+c停止
previous_losses = []
for step in range(epochs):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = get_samples(train_set, batch_num)
input_feed = {}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([len(sample_decoder_inputs[0])], dtype=np.int32)
[loss_ret, _] = sess.run([loss, update], input_feed)
if step % 100 == 0:
print('step=', step, 'loss=', loss_ret, 'learning_rate=', learning_rate.eval())
#print('333', previous_losses[-5:])
if len(previous_losses) > 5 and loss_ret > max(previous_losses[-5:]):
sess.run(learning_rate_decay_op)
previous_losses.append(loss_ret)
# 模型参数保存
saver.save(sess, './model/'+ str(epochs)+ '/demo_')
#saver.save(sess, './model/' + str(epochs) + '/demo_' + step)
1.5、预测过程
预测过程就是读取model文件夹下的参数文件进行预测
def predict():
"""
预测过程
"""
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model(feed_previous=True)
saver.restore(sess, './model/'+str(epochs)+'/demo_')
sys.stdout.write("you ask>> ")
sys.stdout.flush()
input_seq = sys.stdin.readline()
while input_seq:
input_seq = input_seq.strip()
input_id_list = get_id_list_from(input_seq)
if (len(input_id_list)):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = seq_to_encoder(' '.join([str(v) for v in input_id_list]))
input_feed = {}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([2], dtype=np.int32)
# 预测输出
outputs_seq = sess.run(outputs, input_feed)
# 因为输出数据每一个是num_decoder_symbols维的,因此找到数值最大的那个就是预测的id,就是这里的argmax函数的功能
outputs_seq = [int(np.argmax(logit[0], axis=0)) for logit in outputs_seq]
# 如果是结尾符,那么后面的语句就不输出了
if EOS_ID in outputs_seq:
outputs_seq = outputs_seq[:outputs_seq.index(EOS_ID)]
outputs_seq = [wordToken.id2word(v) for v in outputs_seq]
print("chatbot>>", " ".join(outputs_seq))
else:
print("WARN:词汇不在服务区")
sys.stdout.write("you ask>>")
sys.stdout.flush()
input_seq = sys.stdin.readline()
二、源码说明
2.1、模型训练
点击demo_test.py文件,依次点击:run、Edit Configuration,出现如下窗口:
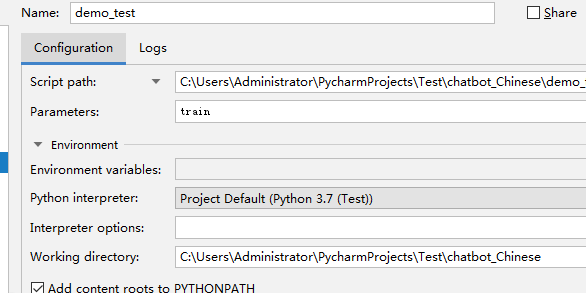
在以上Parameters中填入以下内容train,确定后再运行demo_test.py文件;
train
在面板中得到如下训练信息:
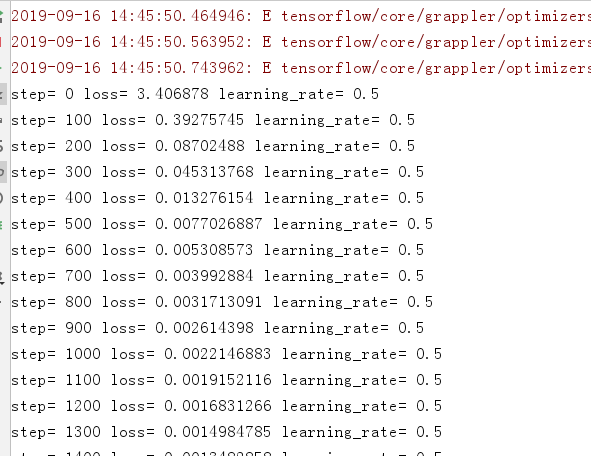
训练结束后,可以在model文件夹下看到生成的模型参数,到这里,训练就结束了。如下所示:

2.2、模型测试
点击demo_test.py文件,依次点击:run、Edit Configuration,出现如下窗口:

将以上Parameters中填入的内容train换成任意一个字符,点击OK后再运行demo_test.py文件,进入如下人机交互式:

三、源码展示
3.1、demo_test.py文件
# -*- coding:utf-8 -*-
import sys
import numpy as np
import tensorflow as tf
from tensorflow.contrib.legacy_seq2seq.python.ops import seq2seq
import word_token
import jieba
import random
size = 8 # LSTM神经元size
GO_ID = 1 # 输出序列起始标记
EOS_ID = 2 # 结尾标记
PAD_ID = 0 # 空值填充0
min_freq = 1 # 样本频率超过这个值才会存入词表
epochs = 2000 # 训练次数
batch_num = 1000 # 参与训练的问答对个数
input_seq_len = 25 # 输入序列长度
output_seq_len = 50 # 输出序列长度
init_learning_rate = 0.5 # 初始学习率
wordToken = word_token.WordToken()
# 放在全局的位置,为了动态算出 num_encoder_symbols 和 num_decoder_symbols
max_token_id = wordToken.load_file_list(['./samples/question', './samples/answer'], min_freq)
num_encoder_symbols = max_token_id + 5
num_decoder_symbols = max_token_id + 5
def get_id_list_from(sentence):
"""
得到分词后的ID
"""
sentence_id_list = []
seg_list = jieba.cut(sentence)
for str in seg_list:
id = wordToken.word2id(str)
if id:
sentence_id_list.append(wordToken.word2id(str))
return sentence_id_list
def get_train_set():
"""
得到训练问答集
"""
global num_encoder_symbols, num_decoder_symbols
train_set = []
with open('./samples/question', 'r', encoding='utf-8') as question_file:
with open('./samples/answer', 'r', encoding='utf-8') as answer_file:
while True:
question = question_file.readline()
answer = answer_file.readline()
if question and answer:
# strip()方法用于移除字符串头尾的字符
question = question.strip()
answer = answer.strip()
# 得到分词id
question_id_list = get_id_list_from(question)
answer_id_list = get_id_list_from(answer)
if len(question_id_list) > 0 and len(answer_id_list) > 0:
answer_id_list.append(EOS_ID)
train_set.append([question_id_list, answer_id_list])
else:
break
return train_set
def get_samples(train_set, batch_num):
"""
构造样本数据:传入的train_set是处理好的问答集
batch_num:让train_set训练集里多少问答对参与训练
"""
raw_encoder_input = []
raw_decoder_input = []
if batch_num >= len(train_set):
batch_train_set = train_set
else:
random_start = random.randint(0, len(train_set)-batch_num)
batch_train_set = train_set[random_start:random_start+batch_num]
# 添加起始标记、结束填充
for sample in batch_train_set:
raw_encoder_input.append([PAD_ID] * (input_seq_len - len(sample[0])) + sample[0])
raw_decoder_input.append([GO_ID] + sample[1] + [PAD_ID] * (output_seq_len - len(sample[1]) - 1))
encoder_inputs = []
decoder_inputs = []
target_weights = []
for length_idx in range(input_seq_len):
encoder_inputs.append(np.array([encoder_input[length_idx] for encoder_input in raw_encoder_input], dtype=np.int32))
for length_idx in range(output_seq_len):
decoder_inputs.append(np.array([decoder_input[length_idx] for decoder_input in raw_decoder_input], dtype=np.int32))
target_weights.append(np.array([
0.0 if length_idx == output_seq_len - 1 or decoder_input[length_idx] == PAD_ID else 1.0 for decoder_input in raw_decoder_input
], dtype=np.float32))
return encoder_inputs, decoder_inputs, target_weights
def seq_to_encoder(input_seq):
"""
从输入空格分隔的数字id串,转成预测用的encoder、decoder、target_weight等
"""
input_seq_array = [int(v) for v in input_seq.split()]
encoder_input = [PAD_ID] * (input_seq_len - len(input_seq_array)) + input_seq_array
decoder_input = [GO_ID] + [PAD_ID] * (output_seq_len - 1)
encoder_inputs = [np.array([v], dtype=np.int32) for v in encoder_input]
decoder_inputs = [np.array([v], dtype=np.int32) for v in decoder_input]
target_weights = [np.array([1.0], dtype=np.float32)] * output_seq_len
return encoder_inputs, decoder_inputs, target_weights
def get_model(feed_previous=False):
"""
构造模型
"""
learning_rate = tf.Variable(float(init_learning_rate), trainable=False, dtype=tf.float32)
learning_rate_decay_op = learning_rate.assign(learning_rate * 0.9)
encoder_inputs = []
decoder_inputs = []
target_weights = []
for i in range(input_seq_len):
encoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="encoder{0}".format(i)))
for i in range(output_seq_len + 1):
decoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="decoder{0}".format(i)))
for i in range(output_seq_len):
target_weights.append(tf.placeholder(tf.float32, shape=[None], name="weight{0}".format(i)))
# decoder_inputs左移一个时序作为targets
targets = [decoder_inputs[i + 1] for i in range(output_seq_len)]
cell = tf.contrib.rnn.BasicLSTMCell(size)
# 这里输出的状态我们不需要
outputs, _ = seq2seq.embedding_attention_seq2seq(
encoder_inputs,
decoder_inputs[:output_seq_len],
cell,
num_encoder_symbols=num_encoder_symbols,
num_decoder_symbols=num_decoder_symbols,
embedding_size=size,
output_projection=None,
feed_previous=feed_previous,
dtype=tf.float32)
# 计算加权交叉熵损失
loss = seq2seq.sequence_loss(outputs, targets, target_weights)
# 梯度下降优化器
opt = tf.train.GradientDescentOptimizer(learning_rate)
# 优化目标:让loss最小化
update = opt.apply_gradients(opt.compute_gradients(loss))
# 模型持久化
saver = tf.train.Saver(tf.global_variables())
return encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate
def train():
"""
训练过程
"""
train_set = get_train_set()
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model()
sess.run(tf.global_variables_initializer())
# 训练很多次迭代,每隔100次打印一次loss,可以看情况直接ctrl+c停止
previous_losses = []
for step in range(epochs):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = get_samples(train_set, batch_num)
input_feed = {}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([len(sample_decoder_inputs[0])], dtype=np.int32)
[loss_ret, _] = sess.run([loss, update], input_feed)
if step % 100 == 0:
print('step=', step, 'loss=', loss_ret, 'learning_rate=', learning_rate.eval())
#print('333', previous_losses[-5:])
if len(previous_losses) > 5 and loss_ret > max(previous_losses[-5:]):
sess.run(learning_rate_decay_op)
previous_losses.append(loss_ret)
# 模型参数保存
saver.save(sess, './model/'+ str(epochs)+ '/demo_')
#saver.save(sess, './model/' + str(epochs) + '/demo_' + step)
def predict():
"""
预测过程
"""
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model(feed_previous=True)
saver.restore(sess, './model/'+str(epochs)+'/demo_')
sys.stdout.write("you ask>> ")
sys.stdout.flush()
input_seq = sys.stdin.readline()
while input_seq:
input_seq = input_seq.strip()
input_id_list = get_id_list_from(input_seq)
if (len(input_id_list)):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = seq_to_encoder(' '.join([str(v) for v in input_id_list]))
input_feed = {}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([2], dtype=np.int32)
# 预测输出
outputs_seq = sess.run(outputs, input_feed)
# 因为输出数据每一个是num_decoder_symbols维的,因此找到数值最大的那个就是预测的id,就是这里的argmax函数的功能
outputs_seq = [int(np.argmax(logit[0], axis=0)) for logit in outputs_seq]
# 如果是结尾符,那么后面的语句就不输出了
if EOS_ID in outputs_seq:
outputs_seq = outputs_seq[:outputs_seq.index(EOS_ID)]
outputs_seq = [wordToken.id2word(v) for v in outputs_seq]
print("chatbot>>", " ".join(outputs_seq))
else:
print("WARN:词汇不在服务区")
sys.stdout.write("you ask>>")
sys.stdout.flush()
input_seq = sys.stdin.readline()
if __name__ == "__main__":
if sys.argv[1] == 'train':
train()
else:
predict()
3.2、word_token.py文件
# -*- coding:utf-8 -*-
import sys
import jieba
class WordToken(object):
def __init__(self):
# 最小起始id号, 保留的用于表示特殊标记
self.START_ID = 4
self.word2id_dict = {}
self.id2word_dict = {}
def load_file_list(self, file_list, min_freq):
"""
加载样本文件列表,全部切词后统计词频,按词频由高到低排序后顺次编号
并存到self.word2id_dict和self.id2word_dict中
file_list = [question, answer]
min_freq: 最小词频,超过最小词频的词才会存入词表
"""
words_count = {}
for file in file_list:
with open(file, 'r', encoding='utf-8') as file_object:
for line in file_object.readlines():
line = line.strip()
seg_list = jieba.cut(line)
for str in seg_list:
if str in words_count:
words_count[str] = words_count[str] + 1
else:
words_count[str] = 1
sorted_list = [[v[1], v[0]] for v in words_count.items()]
sorted_list.sort(reverse=True)
for index, item in enumerate(sorted_list):
word = item[1]
if item[0] < min_freq:
break
self.word2id_dict[word] = self.START_ID + index
self.id2word_dict[self.START_ID + index] = word
return index
def word2id(self, word):
# 判断word是不是字符串
if not isinstance(word, str):
print("Exception: error word not unicode")
sys.exit(1)
if word in self.word2id_dict:
return self.word2id_dict[word]
else:
return None
def id2word(self, id):
id = int(id)
if id in self.id2word_dict:
return self.id2word_dict[id]
else:
return None
下面我们介绍下网上开源的DeepQA项目,这个项目说的很详细,还有很多功能值得借鉴。
四、DeepQA项目简单介绍
DeepQA源码GitHub地址:https://github.com/Conchylicultor/DeepQA
下载源码、解压、并在pycharm下建立工程。
本文只讲解DeepQA项目的demo,不涉及website版,有兴趣的伙伴可以自己研究chatbot_website下的文件。
建立工程后可得到如下图示:
1.data文件夹:**是用来保存语料数据的,在DeepQA源码GitHub地址中对这个文件夹有详细说明。简单介绍如下:打开data文件夹,是右上图所示:
①、cornell下是康奈尔电影对话语料库,也是默认的语料数据,.txt格式;
②、如果你自己想使用自己的语料库,则需要将自己准备的语料存入lightweight文件夹中(下面针对自己的语料库会有更详细的操作介绍);
③、samples文件夹存储由语料库.txt格式转化而来的.pkl文件,.pkl文件才是程序读取的语料格式;
④、test文件夹下有一个同名不同格式的samples.txt文件,用来存储测试语料;
2.save文件夹:用来保存由训练得到的model模型参数,主要是里面的.ckpt文件存储模型参数;model_predictions.txt保存内测输出(下有详细介绍);
3.main.py是主函数:训练train、测试test的入口;
4.chatbot.py是主要参数程序:里面包括各种参数调整的接口(下有详细介绍);

五、使用默认康奈尔(cornell)电影对话语料库做chatbot
5.1、模型训练
1、下载解压DeepQA源码,新建pycharm工程后,直接运行main.py,即可开始训练。运行窗口如下所示:

2、请注意chatbot.py程序130行–135行的模型参数调整,分别是训练批次numEpochs、保存参数的步长saveEvery、批量batchsize、学习率lr、dropout参数:(这里根据大家需求,自行调参)

3、语料读取完毕后,就可以在data/samples文件夹下查看由语料库中的.txt文件生成的.pkl文件:

4、最后就是开始漫长的训练,训练完成后,可以在save/model文件夹下查看生成的model参数文件:(此时应该是没有model_predictions.txt文件,内测测试后才会生成model_predictions.txt文件,下有介绍)
5.2、模型测试
5.2.1、内测——生成model_predictions.txt文件
先打开data/cornell文件夹,查看到其下有两个.txt文件,这就是康奈尔训练语料集,再打开data/test文件夹,查看到其下samples.txt文件就是测试语料集,最后打开main.py文件,依次点击:run、Edit Configuration,得到如下窗口:

在Parameters中填入下面的内容:
--test
确定后再点击运行main.py文件,在对话窗口得到成功信息后,就可以在save/model文件夹下看到生成的model_predictions.txt文件;
打开model_predictions.txt文件——这个文件是由训练语料集得到的model来预测data/test/samples.txt文件得到的预测回答内容,如下所示

5.2.2、外测——进入人机对话模式
外测的操作步骤如内测一致,依次点击:run、Edit Configuration,最后在Parameters中填入的内容改成如下:
--test interactive
就可以在对话窗口中进入人机交互模式。
到这里一个简单的chatbot聊天机器人就完成了。训练次数与语料库质量直接影响模型效果。
六、使用自己的语料库做chatbot
使用自己的语料库做chatbot其实也很简单——就是准备一些语料,修改一些参数。
6.1、如何制作自己的语料库
需要在data/lightweight文件夹下制作自己的训练语料库,在data/test/samples.txt制作自己的测试语料库
以下方法只是简单制作方法,制作详细方法请参考——DeepQA项目如何制作自己的语料库
6.1.1、训练语料制作
在data/lightweight文件夹下新建<name>.txt文本文件,注意<name>需要使用自己的文件名。在文本文件中输入自己的语料:不同语境间用===分割,上下即为问答对形式;

6.1.2、测试语料
在data/test文件夹下的samples.txt中重新输入测试语料,测试语料只在内测时候生成model_predictions.txt文件用到;也是上下问答对形式,但不必用===区分语境;
6.2、训练自己的语料库
每一次重新训练之前,都要先查看data/samples文件夹下之前生成的两个.pkl文件是否已经删除——我并没有对这一点进行过深究,只是发现程序具有检查.pkl格式文件的能力?如果不提早删除,程序会先读取已存在的.pkl文件,如果这样就意味着新语料并没有参与新的训练。
训练自己的语料库的步骤我们也已经做过多次轻车熟路了——先打开main.py文件,依次点击:run、Edit Configuration,在Parameters中填入下面的内容,再点击运行main.py文件;请注意<name>要与你的文件名一致;
--corpus lightweight --datasetTag <name>
成功读取语料集后,就可以在data/samples查看到新生成的.pkl文件,同样训练结束后可以在save/model文件夹下查看新生成的model参数文件;
6.3、测试自己的语料库结果
内测与外测的步骤都与上述内/外测的步骤一模一样:
内测:依次点击:run、Edit Configuration,在Parameters中填入下面的内容后,点击运行main.py文件,就可以在得到成功信息后,在save/model文件夹下看到生成的model_predictions.txt文件
--test
外测:依次点击:run、Edit Configuration,在Parameters中填入的内容改成如下,最后点击运行main.py文件
--test interactive
就可以在对话窗口中进入人机交互模式。语料库质量差、语料库对话数据少、训练次数过低都会导致交互预测结果差的状况产生。
在训练2W次的模型,外测进入交互窗口后,如果输入的问题是data/lightweight文件夹下自己语料库中的问题(问题+符号都需要一字不差,问题不区分语种),这时候百分百答出问题正确答案,但如果不是自己语料库内的问题、或者不是百分百自己语料库内的中文问题,总会重复出错,可能由于我的语料集包含的场景过少,问题覆盖面小,训练过拟合导致正确答案只能由完整问题才能答出;因为DeepQA项目面对的语种是英语,对英语有模糊回答处理,所以回答英语问题置信度尚可,但如果我们将训练集改成全中文形式,DeepQA并没有像jieba分词一样类似的操作,所以得到的回答预测总是差强人意。