一、学习视频自我小结
二元分类
1、计算机保存一个图片,通过保存红、绿、蓝三个颜色的像素矩阵。
2、这些像素值提取出来,然后放入一个特征向量 x ,如果图片的大小为64x64像素,那么向量 x 的总维度,将是64乘以64乘以3,这是三个像素矩阵中像素的总量

3、二分类问题中,我们的目标就是习得一个分类器,它以图片的特征向量x作为输入,然后预测输出 y 结果为1还是0,也就是预测图片中是否有猫
4、符号定义 :
x :
表示一个 n_x维数据,为输入数据,维度为 (n_x,1);
y :
表示输出结果,取值为 ( 0 , 1 ) ;
( x ( i ) , y ( i ) ) :
表示第组数据,可能是训练数据,也可能是测试数据,此处默认为训练数据;
X = [ x ( 1 ) , x ( 2 ) , ⋯ , x ( m ) ]:
表示所有的训练数据集的输入值,放在一个 n_x * m 的矩阵中,其中 m 表示样本数目;
Y = [ y ( 1 ) , y ( 2 ) , ⋯ , y ( m ) ]:
对应表示所有训练数据集的输出值,维度为 1 ∗ m 。
用一对 ( x , y ) 来表示一个单独的样本,x 代表 n_x 维的特征向量,y 表示标签(输出结果)只能为0或1。 而训练集将由 m 个训练样本组成,其中(x(1),y(1)) 表示第一个样本的输入和输出, (x(2),y(2)) 表示第二个样本的输入和输出,直到最后一个样本(x(m),y(m)) ,然后所有的这些一起表示整个训练集。有时候为了强调这是训练样本的个数,会写作 Mtrain,当涉及到测试集的时候,我们会使用来 Mtest 表示测试集的样本数,所以这是测试集的样本数:
Logistic 回归
1、你想知道某张图片是否是猫,我们前面用y={0,1}来表示是否是吗,那现在我们根据输入的特征向量X,利用算法得到预测y帽(一个概率值)。准确来说x是个图片,我们希望y帽告诉这个图片是猫图的概率
2、因为前面说过特征向量x是个nx维的,所以w*x+b,w也应该是nx维,b是个一维实数,可能你会想到用线性回归来求y帽,即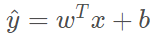 ,但是y帽是个概率,应该在(0,1),要不然没意义,所以我们用 sigmoid 作用在w*x+b这个量上,也就是
,但是y帽是个概率,应该在(0,1),要不然没意义,所以我们用 sigmoid 作用在w*x+b这个量上,也就是
3、 sigmoid 函数可以很好地将 (−∞,∞)内的数映射到 (0,1) 上。于是我们可以将 g(z)≥0.5时分为"1"类, g(z)<0.5 时分为"0"类。
二、运行实例代码
报错:tf.placeholder() is not compatible with eager execution.
解决--在代码中添加这样一句:
tf.compat.v1.disable_eager_execution()
三、实现Typora 笔记与博客园联动
写好typora笔记后
1、cmd 输入e:
2、输入cd 笔记文档
3、dotnet-cnblog proc -f Logistic回归损失函数.md

4、然后会生成一个cnblog.md,把里面的内容复制到博客园即可