缓存
缓存构建的基本思想是利用时间局限性原理,通过空间换时间来达到加速数据获取的目的,同时由于缓存空间的成本较高,在实际设计架构中还要考虑访问延迟和成本的权衡问题。
业务系统读写缓存有 3 种模式:
- Cache Aside(旁路缓存),先更新db,后删除缓存
- Read/Write Through(读写穿透),cache服务更新缓存,并更新db。
- Write Behind Caching(异步缓存写入),cache服务甘心缓存,异步更新dn。
Cache Aside模式(旁路缓存)
1.Write: 更新 DB 后,直接将 key 从 cache 中删除,然后由 DB 驱动缓存数据的更新;
2.Read: 是先读 cache,如果 cache 没有,则读 DB,同时将从 DB 中读取的数据回写到 cache。
特点:
确保数据以DB 结果为准
适用场景:
对数据一致性要求比较高的业务,或者是缓存数据更新比较复杂的业务,比如需要通过多个原始数据进行计算后设置的缓存数据
Read/Write Through模式(读写穿透)
1. Write: 存储服务收到业务应用的写请求时,会首先查 cache,如果数据在 cache 中不存在,则只更新 DB,如果数据在 cache 中存在,则先更新 cache,然后更新 DB。
2. Read: 存储服务收到读请求时,如果命中 cache 直接返回,否则先从 DB 加载,回写到 cache 后返回响应。
特点:
- 存储服务封装了所有的数据处理细节,业务应用端代码只用关注业务逻辑本身,系统的隔离性更佳。
- 进行写操作时,如果 cache 中没有数据则不更新,有缓存数据才更新,内存效率更高。
适用场景:
用户最新Feed列表
Write Behind Caching模式(异步缓存写入)
1.Write: 只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB
2.Read: 如果命中 cache 直接返回,否则先从 DB 加载,回写到 cache 后返回响应。
特点:
写性能最高,定期异步刷新,存在数据丢失概率
适用场景:
适合变更频率特别高,但对一致性要求不太高的业务,特别是可以合并写请求的业务,比如对一些计数业务
这里用的最多的是旁路模式
缓存与数据库的一致性问题
1、先删缓存,再更新数据库
如果有 2 个线程要并发「读写」数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致。
可见,先删除缓存,后更新数据库,当发生「读+写」并发时,还是存在数据不一致的情况。
解决方案:延时双删(没法完全保证)
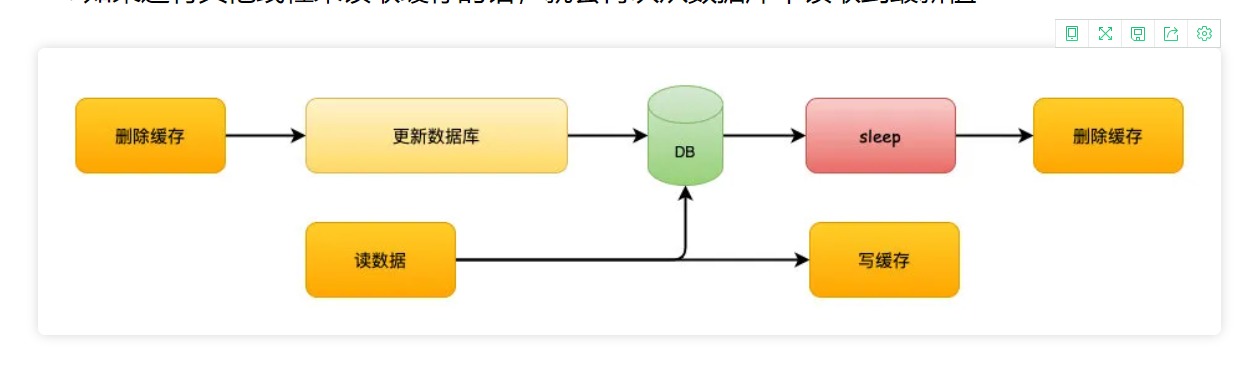
2、先更新数据库,再删缓存
依旧是 2 个线程并发「读写」数据:
- 缓存中 X 不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),也发生不一致。
这种情况「理论」来说是可能发生的,但实际真的有可能发生吗?
其实概率「很低」,这是因为它必须满足 3 个条件:
- 缓存刚好已失效
- 读请求 + 写请求并发
- 更新数据库 + 删除缓存的时间(步骤 3-4),要比读数据库 + 写缓存时间长(步骤 2 和 5)
也就是步骤5通常会在步骤四的前面。
这种方案并发条件下数据一致性的可能性很小,但第二步执行失败会导致数据一致性的问题。
解决方案
(1)、消息队列

异步重试,确保步骤二成功
消息可靠性投递,确保消费者成功消费消息。
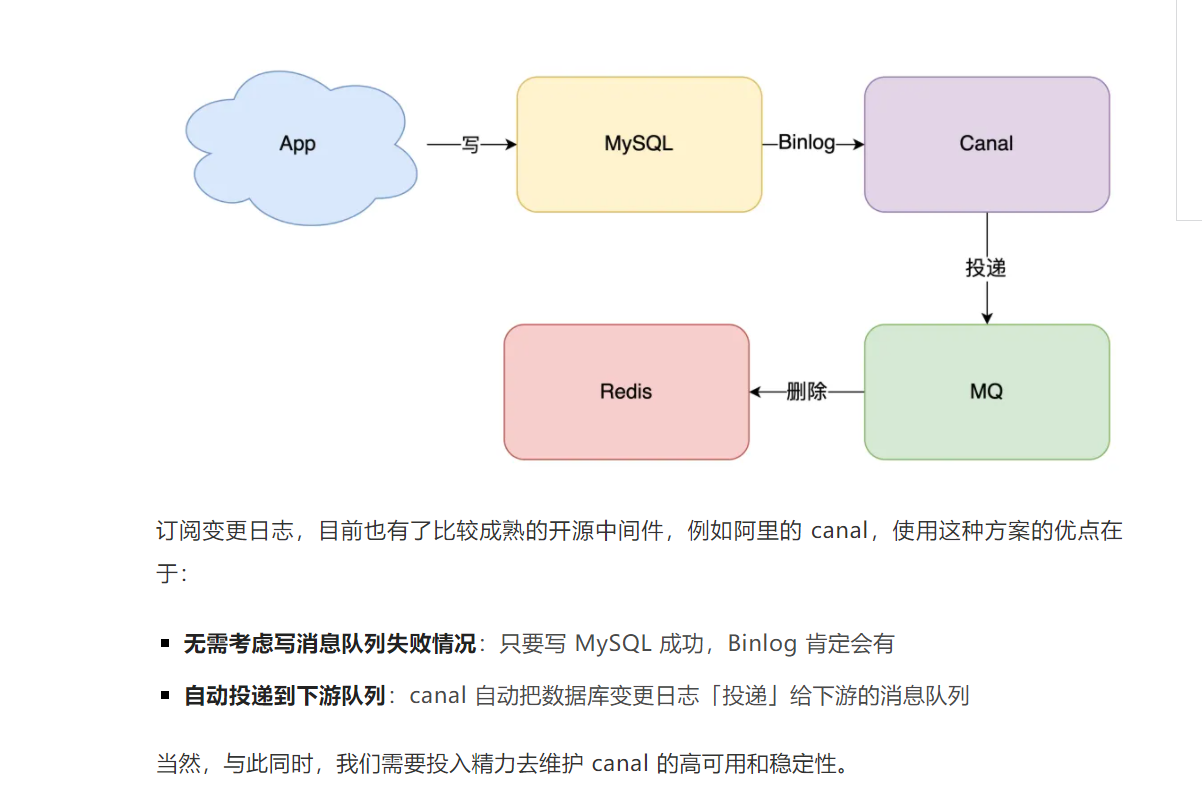
(2)binlog日志 + MQ
订阅数据库变更日志,再操作缓存。具体来讲就是,我们的业务应用在修改数据时,「只需」修改数据库,无需操作缓存。
可以做到强一致吗?
性能和一致性不能同时满足,为了性能考虑,通常会采用「最终一致性」的方案。
要想做到强一致,最常见的方案是 2PC、3PC、Paxos、Raft 这类一致性协议,但它们的性能往往比较差,而且这些方案也比较复杂,还要考虑各种容错问题。
相反,这时我们换个角度思考一下,我们引入缓存的目的是什么?
没错,性能。
一旦我们决定使用缓存,那必然要面临一致性问题。性能和一致性就像天平的两端,无法做到都满足要求。
而且,就拿我们前面讲到的方案来说,当操作数据库和缓存完成之前,只要有其它请求可以进来,都有可能查到「中间状态」的数据。
所以如果非要追求强一致,那必须要求所有更新操作完成之前期间,不能有「任何请求」进来。
虽然我们可以通过加「分布锁」的方式来实现,但我们要付出的代价,很可能会超过引入缓存带来的性能提升。
所以,既然决定使用缓存,就必须容忍「一致性」问题,我们只能尽可能地去降低问题出现的概率。
同时我们也要知道,缓存都是有「失效时间」的,就算在这期间存在短期不一致,我们依旧有失效时间来兜底,这样也能达到最终一致。
参考:
https://mp.weixin.qq.com/s/D4Ik6lTA_ySBOyD3waNj1w
https://mp.weixin.qq.com/s/dYvM8_6SQnYRB6KjPsprbw