一、生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [ x*2 for x in range(5)]
>>> L
[0, 2, 4, 6, 8]
>>> g = ( x*2 for x in range(5) )
>>> g
<generator object <genexpr> at 0x000000000321EF68>
创建L和g的区别仅在于最外层的[]和(),L是一个list,而g是一个generator。我们可以直接打印出list的每一个元素,但我们怎么打印出generator的每一个元素呢?如果要一个一个打印出来,可以通过next()函数获得generator的下一个返回值:
>>> next(g)
0
>>> next(g)
2
>>> next(g)
4
>>> next(g)
6
>>> next(g)
8
>>> next(g)
Traceback (most recent call last):
File "<pyshell#11>", line 1, in <module>
next(g)
StopIteration
>>> g
<generator object <genexpr> at 0x000000000321EF68>
>>> g = ( x*2 for x in range(5) )
>>> for n in g:
print(n)
0
2
4
6
8
generator保存的是算法,每次调用next(g),就计算出g的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出StopIteration的错误。当然,这种不断调用next(g)实在是太变态了,正确的方法是使用for循环,因为generator也是可迭代对象。所以,我们创建了一个generator后,基本上永远不会调用next(),而是通过for循环来迭代它,并且不需要关心StopIteration的错误。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
比如,著名的斐波拉契数列(Fibonacci),除第一个和第二个数外,任意一个数都可由前两个数相加得到:
1, 1, 2, 3, 5, 8, 13, 21, 34, ...
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
>>> def fib(max):
n,a,b = 0,0,1
while n<max:
print(b)
a,b =b,a+b
n=n+1
return 'done'
>>> fib(10)
1
1
2
3
5
8
13
21
34
55
'done'
'''仔细观察,可以看出,fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。
也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
'''
>>> def fib(max):
n,a,b = 0,0,1
while n<max:
yield b
a,b =b,a+b
n=n+1
return 'done'
>>> f=fib(5)
>>> f
<generator object fib at 0x000000000321EF68>
>>> print(next(f))
1
>>> print(next(f))
1
>>> print(next(f))
2
>>> print(next(f))
3
>>> print(next(f))
5
>>> print(next(f))
Traceback (most recent call last):
File "<pyshell#49>", line 1, in <module>
print(next(f))
StopIteration: done
在上面fib的例子,我们在循环过程中不断调用yield,就会不断中断。当然要给循环设置一个条件来退出循环,不然就会产生一个无限数列出来。同样的,把函数改成generator后,我们基本上从来不会用next()来获取下一个返回值,而是直接使用for循环来迭代:
>>> for n in fib(5):
... print(n)
...
1
1
2
3
5
'''
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中:
'''
>>> g=fib(5)
>>> while True:
try:
x=next(g)
print('g:',x)
except StopIteration as e:
print('Generator return value:', e.value)
break
g: 1
g: 2
g: 3
g: 5
g: 8
Generator return value: done
通过yield实现在单线程的情况下实现并发运算的效果:(暂时保留)
二、迭代器
迭代是Python最强大的功能之一,是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
而生成器不但可以作用于for循环,还可以被next()函数不断调用并返回下一个值,直到最后抛出StopIteration错误表示无法继续返回下一个值了。
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的,例如:
for x in [1, 2, 3, 4, 5]:
pass
#实际上完全等价于:
# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:
try:
# 获得下一个值:
x = next(it)
except StopIteration:
# 遇到StopIteration就退出循环
break
三、装饰器
理解了好几天,开始写装饰器,先说定义:装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。假设我们要增强一个函数的功能,比如,在函数调用前后自动打印时间,但又不希望修改函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
def use_logging(func):
print("%s is running" % func.__name__) #_name_获取函数的名字,也就是bar
func()
def bar():
print('i am bar')
use_logging(bar)
'''执行结果:
bar is running
i am bar
'''
逻辑上不难理解, 但是这样的话,我们每次都要将一个函数作为参数传递给use_logging函数。而且这种方式已经破坏了原有的代码逻辑结构,之前执行业务逻辑时,执行运行bar(),但是现在不得不改成use_logging(bar)。那么有没有更好的方式的呢?当然有,答案就是装饰器。
1.无参装饰器
import time
def timer(func):
def deco():
start_time = time.time()
func()
stop_time = time.time()
print("The func run time is %s" %(stop_time-start_time))
return deco
@timer #相当于time1=timer(time1)
def time1():
time.sleep(1)
print("In the time")
time1()
'''
In the time
The func run time is 1.0000569820404053
'''
2.有参装饰器
import time
def timer(timeout=0):
def decorator(func):
def wrapper(*args,**kwargs):
start=time.time()
func(*args,**kwargs)
stop=time.time()
print 'run time is %s ' %(stop-start)
print timeout
return wrapper
return decorator
@timer(2)
def test(list_test):
for i in list_test:
time.sleep(0.1)
print '-'*20,i
#timer(timeout=10)(test)(range(10))
test(range(10))
四、Json & pickle 数据序列化
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
我们把变量从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。Python提供了pickle模块来实现序列化。
>>> import pickle
>>> d = dict(name='Bob', age=20, score=88)
>>> pickle.dumps(d)
b'\x80\x03}q\x00(X\x03\x00\x00\x00ageq\x01K\x14X\x05\x00\x00\x00scoreq\x02KXX\x04\x00\x00\x00nameq\x03X\x03\x00\x00\x00Bobq\x04u.'
#pickle.dumps()方法把任意对象序列化成一个bytes,然后,就可以把这个bytes写入文件。
>>> f = open('dump.txt', 'wb')
>>> pickle.dump(d, f)
>>> f.close()
#当我们要把对象从磁盘读到内存时,可以先把内容读到一个bytes,然后用pickle.loads()方法反序列化出对象。
>>> f = open('dump.txt', 'rb')
>>> d = pickle.load(f)
>>> f.close()
>>> d
{'age': 20, 'score': 88, 'name': 'Bob'}
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
>>> import json
>>> d = dict(name='Bob', age=20, score=88)
>>> json.dumps(d)
'{"age": 20, "score": 88, "name": "Bob"}'
dumps()方法返回一个str,内容就是标准的JSON。
要把JSON反序列化为Python对象,用loads()或者对应的load()方法,前者把JSON的字符串反序列化。
>>> json_str = '{"age": 20, "score": 88, "name": "Bob"}'
>>> json.loads(json_str)
{'age': 20, 'score': 88, 'name': 'Bob'}
文件读取操作:


global log 127.0.0.1 local2 daemon maxconn 256 log 127.0.0.1 local2 info defaults log global mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms option dontlognull listen stats :8888 stats enable stats uri /admin stats auth admin:1234 frontend oldboy.org bind 0.0.0.0:80 option httplog option httpclose option forwardfor log global acl www hdr_reg(host) -i www.oldboy.org use_backend www.oldboy.org if www backend www.oldboy.org server 100.1.7.9 100.1.7.9 weight 20 maxconn 3000 backend www.newboy.org server 100.1.7.9 100.1.7.9 weight 20 maxconn 3000
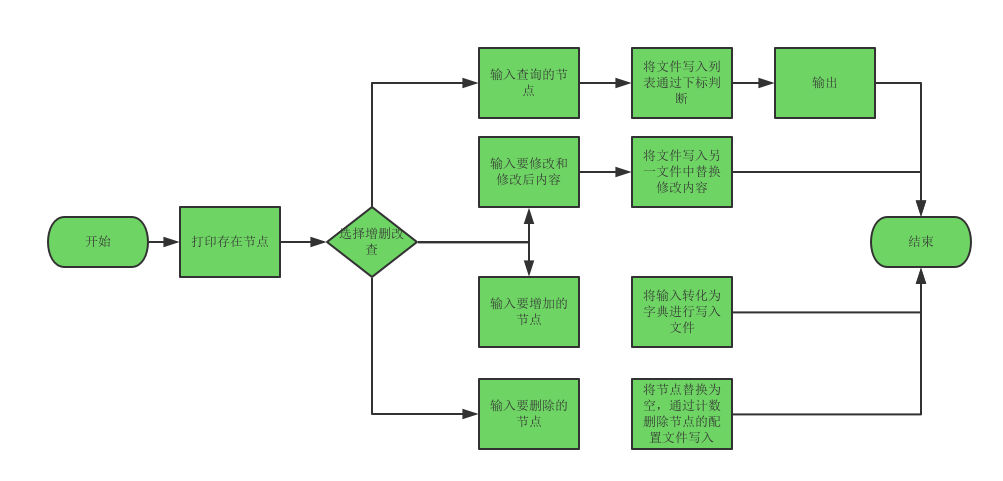
f = open('haproxy.txt', encoding='utf-8') lines = [] c = 0 d =99999 print("显示所有节点:") with open('haproxy.txt', encoding='utf-8') as e: for line in e: pass if "backend " in line and "use_backend" not in line: print(line) choose_input = input( "1 查询\n" "2 修改\n" "3 增加\n" "4 删除\n" "请输入要选择的操作序号[1|2|3|4]:") if str.isdigit(choose_input): choose_input = int(choose_input) if choose_input == 1: user_input = input("例如www.oldboy.org,手打,不要复制粘贴,因为是网页会出错不是程序的错误\n" "请输入要查询的主机名:") a = ("backend %s\n" % user_input) for i in f: lines.append(i.strip().split()) c += 1 if a in i: d = c f.close() print(' '.join(lines[d-1]), "\n", ' '.join(lines[d])) if choose_input == 3: user_input=input("例如{'bakend': 'www.oldboy.org','record':{'server': '100.1.7.9','weight': 20,'maxconn': 3000}}\n" "请输入要增加的节点:") arg=eval(user_input) with open("haproxy.txt","a",encoding="utf-8") as e: e.write("bakend ") e.write(arg['bakend']) e.write("\n record ") e.write(arg['record']['server']) e.write(" ") e.write(arg['record']['server']) e.write(" weight ") e.write(str(arg['record']['weight'])) e.write(" maxconn ") e.write(str(arg['record']['maxconn'])) e.write('\n') f.close() if choose_input == 2: user_input=input("例如:www.newboy.org" "请输入要修改的内容:") user_input2=input("例如:www.newboy.com" "请输入修改后的内容:") f = open('haproxy.txt', encoding='utf-8') f_new=open("haproxybak.txt","w",encoding='utf-8') for lines in f: if user_input in lines: lines = lines.replace(user_input,user_input2) f_new.write(lines) f.close() f_new.close() print("修改完毕,请查看haproxybak.txt") if choose_input == 4: user_input=input("例如:www.oldboy.org" "请输入要删除的内容:") a = ("backend %s\n" % user_input) f = open('haproxy.txt', encoding='utf-8') f_new=open("haproxybak.txt","w",encoding='utf-8') for lines in f: if a in lines: lines = lines.replace(a,'') d = c + 1 elif d == c : lines = "" f_new.write(lines) c += 1 f.close() f_new.close() print("节点已删除,请查看haproxybak.txt") else: print("请输入正确序号!!!")
夕阳斜照将酒馆招牌影子拖长,
矮胖的老板在柜台后面算着酒账,
客人们喝着麦酒看着舞台之上,
抱着琴的诗人正在懒懒吟唱:
“……当所有传奇写下第一个篇章
原来所谓英雄也和我们一样。