前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者:OSinooO
本人属于python新手,刚学习的 python爬虫基础迫不及待地想试一试,看了论坛里大佬们写的在线翻译爬虫程序,想着自己把它写出来,以下是我爬微软翻译的过程,作为笔记记录下来:
1.获取信息
要实现在线翻译过程,首先要获得目标网站的信息,我们先打开微软必应翻译的官网(https://cn.bing.com/translator):
我们需要获得它的翻译请求和响应信息,操作如下:
(1)右键“检查”(用的Google Chrome浏览器),进入这个界面:
也可以通过右上角》更多工具》开发者工具进入。
(2)选择“Network”
(3)输入我们想翻译的内容,先输入“hello”,选择简体中文:
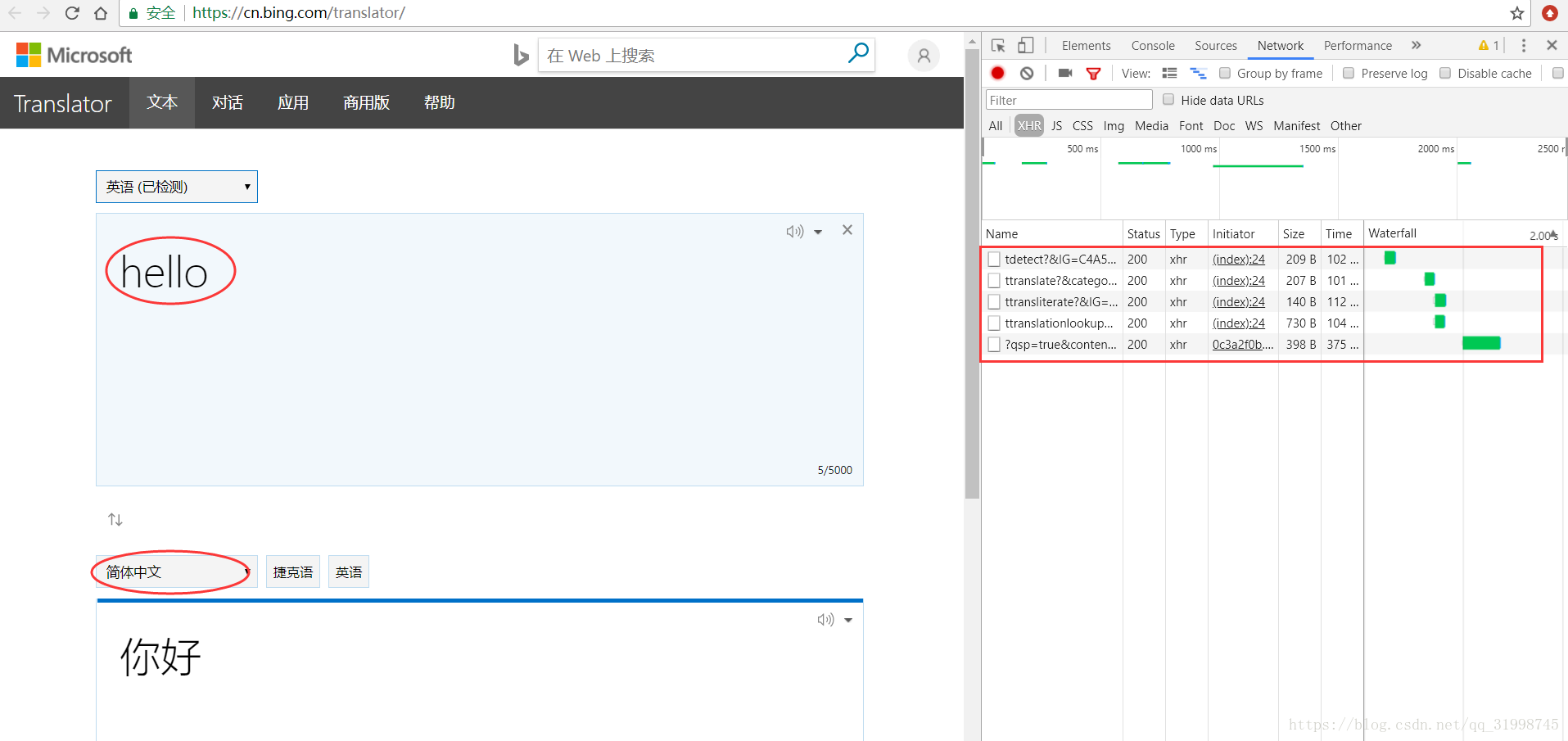
可以看到右边出了很多抓到的包,点开看一下。
(4)找到response(响应)里面出现了翻译结果的包
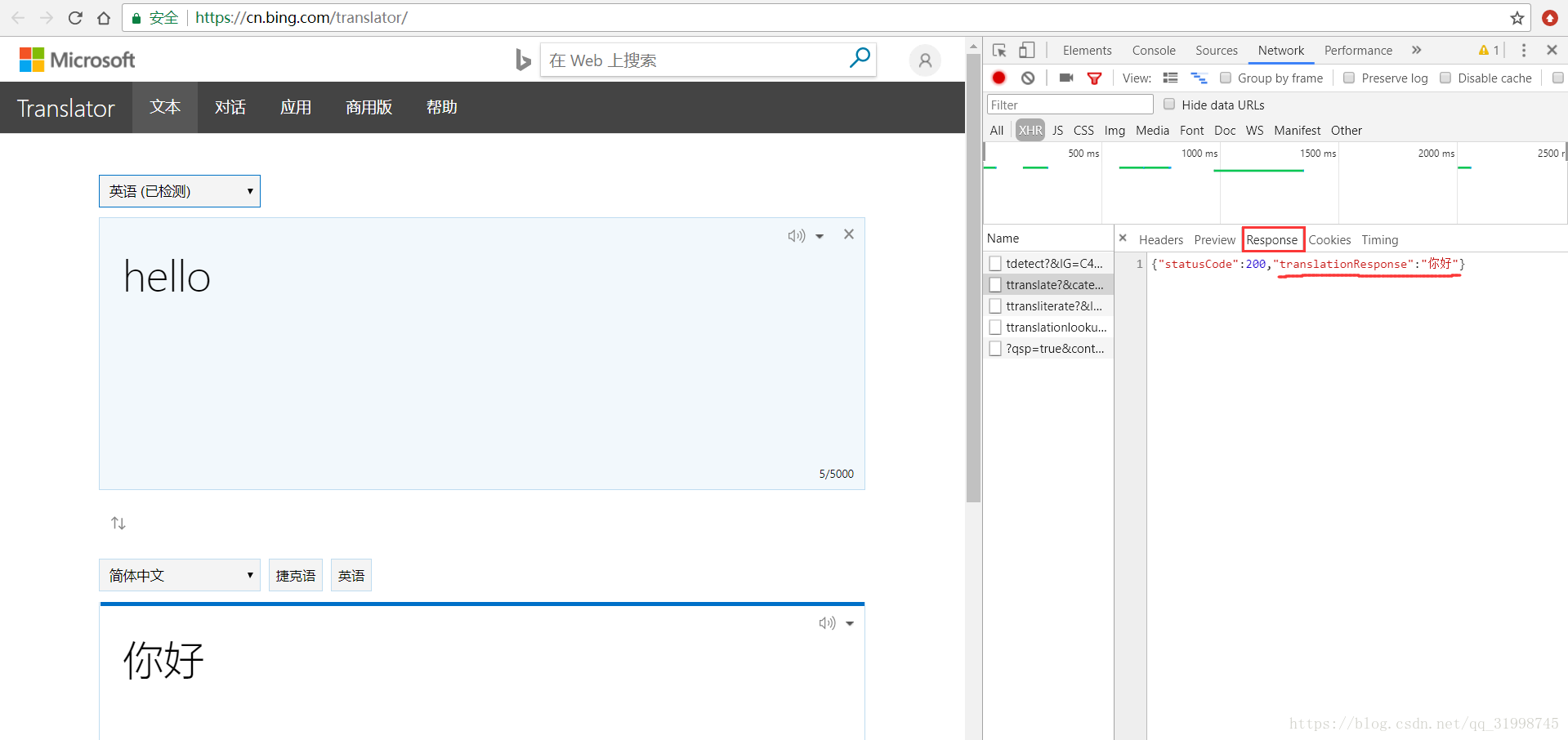
(5)接下来就是获取URL和data信息了,在“Headers”部分就可以看到。这里的URL是处理我们请求翻译的网页地址,当网页请求方式为POST时,请求参数存放在data(类型为字典)里。
URL:https://cn.bing.com/ttranslate?&category=&IG=C4A52C35D175427988E6510779DEFB5F&IID=translator.5036.8
这里我要说明一下,我在第一次找URL的时候找到的是这个:
https://cn.bing.com/ttranslate?&category=&IG=7E72C4A882064F48BAD8D7C06B7F22A9&IID=translator.5036.1
用这个URL也可以翻译,但是只能翻译单个单词和词语,在后面的代码中如果翻译了长句子就会报错。所以提取参数的时候可以把翻译内容多写一点,找到能长句翻译的URL。
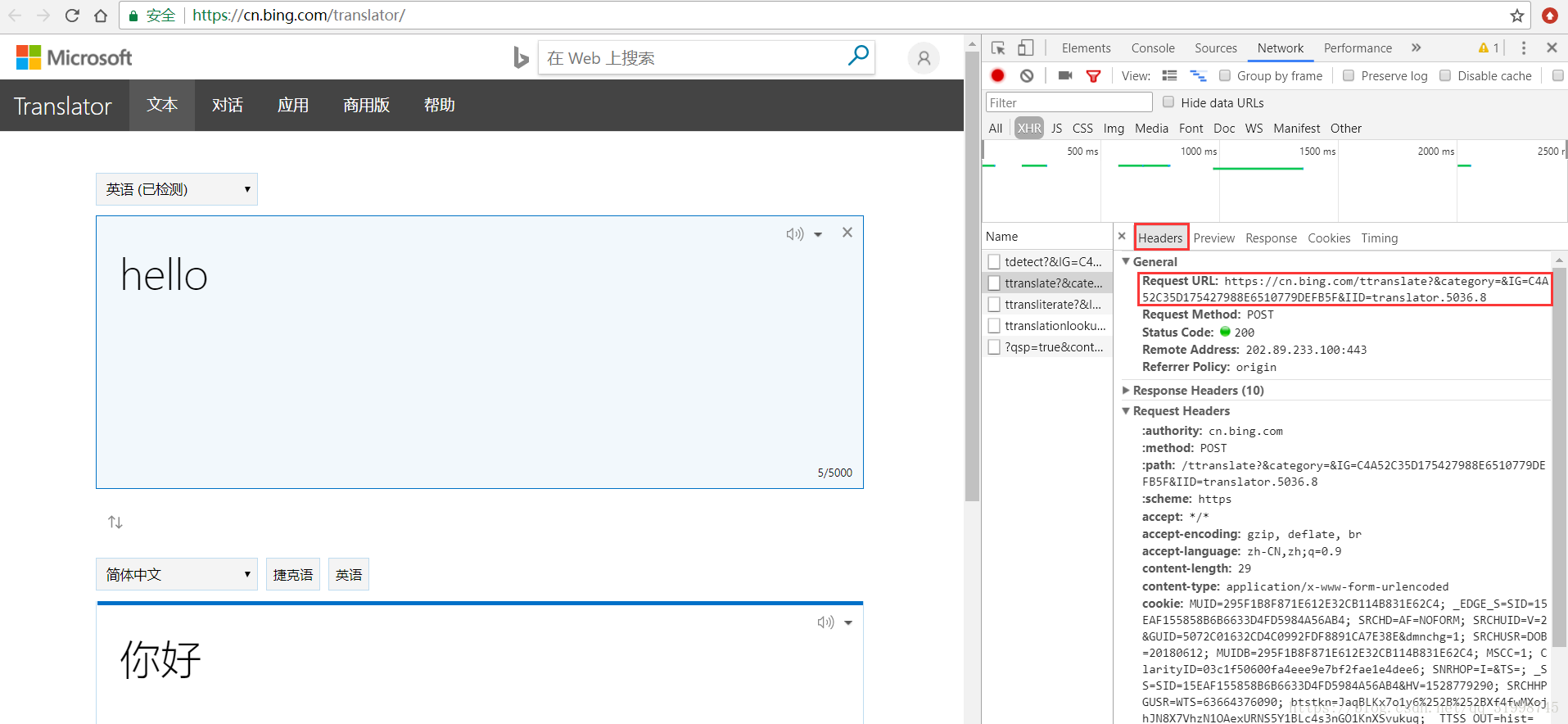
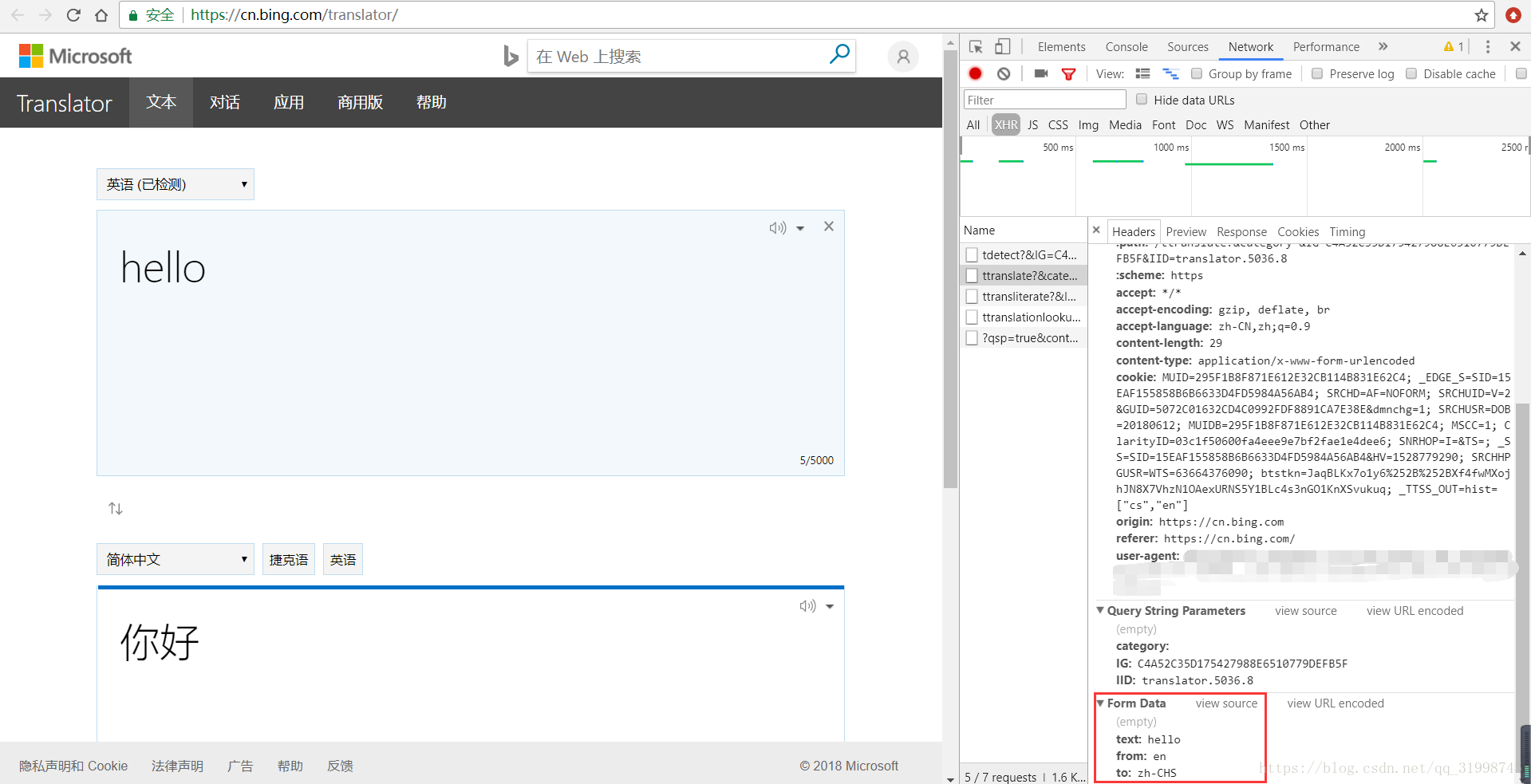
data:{‘text’:'hello', 'from':'en', 'to':'zh-CHS'}这里用字典形式写出来,简单解读就是'text'是翻译的内容,'from'是翻译内容的语言,这里的'en'就代表英语,'to'是翻译结果的语言,'zh-CHS'代表简体中文。这些之后要用到。
2.代码构建
得到信息之后就可以开始写代码了,具体可以参考文章开头的两篇参考博文,这里直接给出代码:如果你看不懂的话,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,多跟里面的人交流,进步更快哦!
import requests
url = 'https://cn.bing.com/ttranslate?&category=&IG=C4A52C35D175427988E6510779DEFB5F&IID=translator.5036.8'
def translate_weiruan(info,fr='zh-CHS',to="en"):
print('翻译结果:'+requests.post(url,data={'text':info,'from':fr,'to':to,'doctype':'json'}).json()['translationResponse'])
def is_Chinese(str): #判断输入的内容是否是中文
for ch in str:
if 'u4e00' <= ch <= 'u9fff':
return True
else:
return False
def start_translate():
trans = input('翻译内容:')
if is_Chinese(trans): #实现自动判断,中英互译
translate_weiruan(trans)
else:
translate_weiruan(trans,fr='en',to='zh-CHS')
if __name__ == '__main__':
print(' 翻译结果由微软翻译提供!(请确保网络已连接)')
while True:
start_translate()
print('
')
这里用的requests模块,可以用一句话实现我们的功能,具体参考文章开头的第二篇博文。
再简单解释一下:
def translate_weiruan(info,fr='zh-CHS',to="en"):
print('翻译结果:'+requests.post(url,data={'text':info,'from':fr,'to':to,'doctype':'json'}).json()['translationResponse'])
这段代码的功能就是用POST方式连接翻译网站(url)并给它传参数(data),返回一个 json 类型的信息,再用 json()方法对信息进行处理。返回的信息如下:
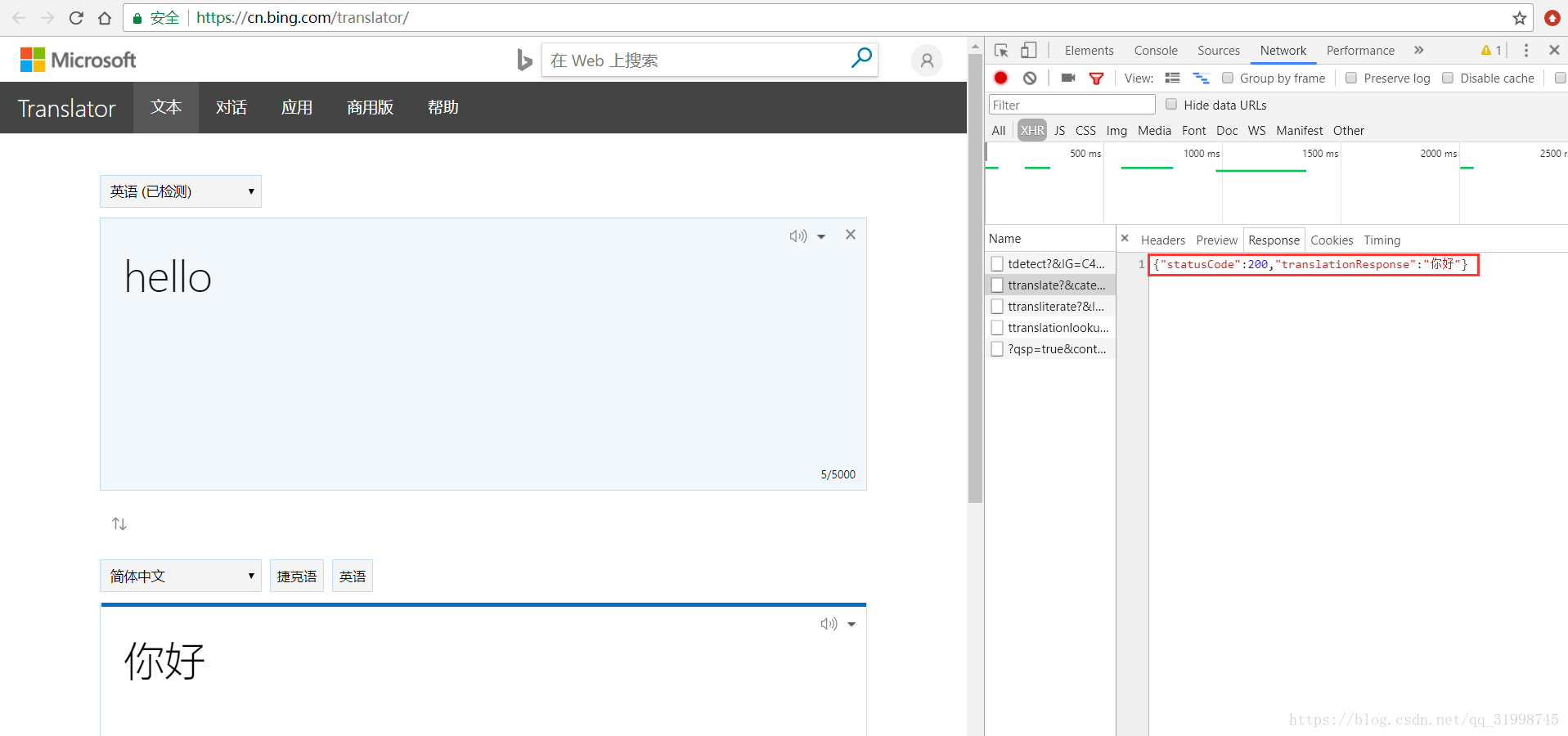
很简单的字典类型:{"statusCode":200,"translationResponse":"你好"}
再用关键字"translationResponse"提取翻译结果。
3.实战结果
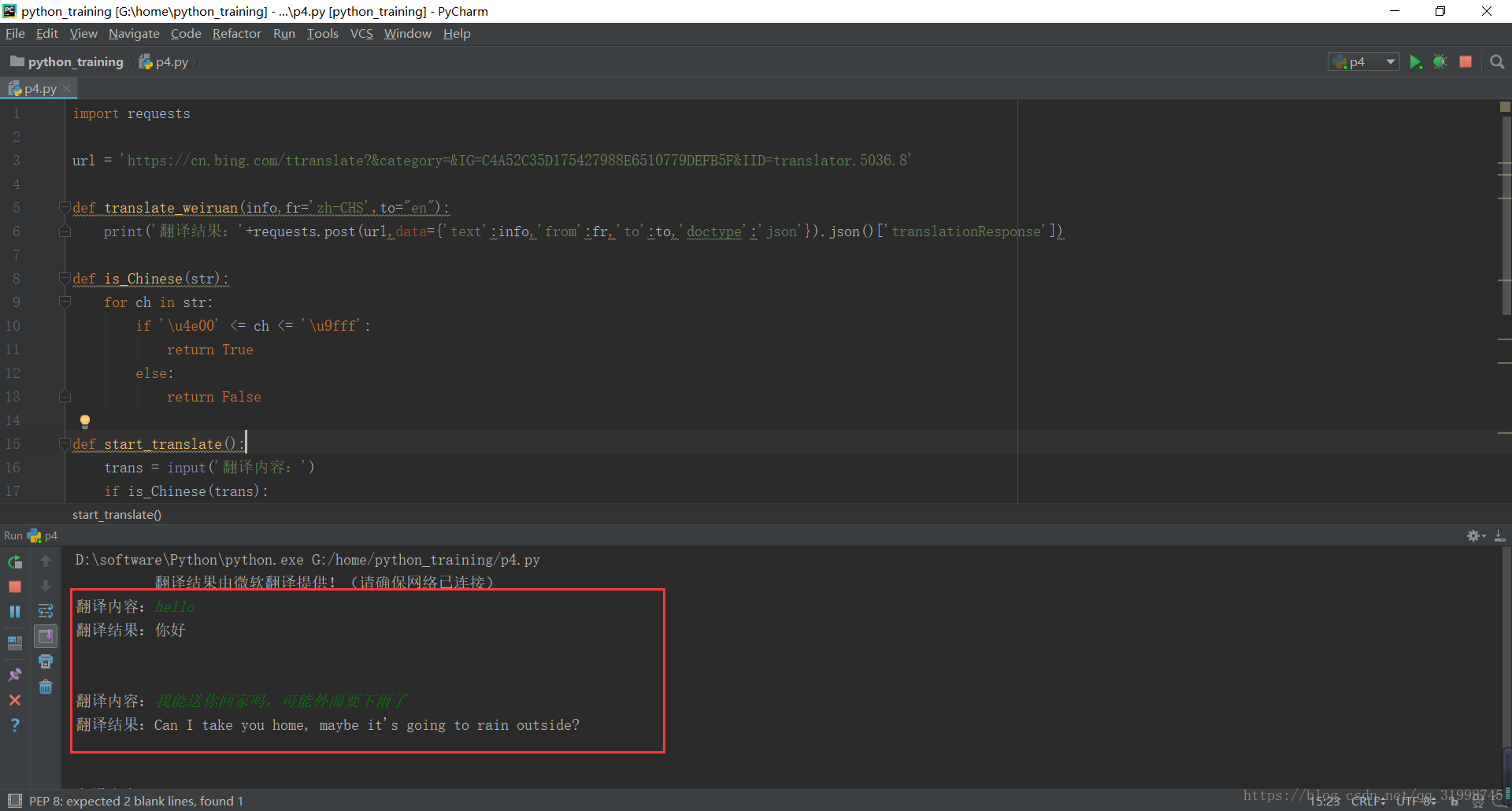
OK,也算是初步完成功能啦!当然里面也还是有很多不足,还请各位大牛指点。如果你也正在学习,可以去如果你看不懂的话,建议先去小编的Python交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,多跟里面的人交流,进步更快哦!