SQL:Structured Query Language:结构化查询语言(通称: 针对所有的关系型数据库)
SQL分为三个部分
- DDL: Data Definition Language,数据定义语言: 定义结构(数据库,数据表,视图,函数等: create/drop/alter)
- DML: Data Manipulation Language,数据操作语言: 数据操作(增删改查: insert/delete/update/select): 在DML中因为使用的最多的查询: DQL(Data Query language:数据查询语言: select)
- DCL: data Control Language,数据控制语言: 权限控制(用户管理, 权限分配: grant/revoke)
SQL是针对关系型数据库,而不是针对某个具体的数据库产品: SQL本身有很多规定, 但是没有一种是明确规定必须怎么设计的(如W3C)
SQL也是一种非强制的规范: 在不同的数据库产品里, 对应的SQL指令会有一些小小的区别(但是整体是一样).
基本操作分为三种:
- 库操作
- 表操作(字段)
- 数据操作
基本操作都是对对象的增删改查:CRUD
- C: create,新增
- R: retrive/read,查询(读取)
- U: update,更新(修改)
- D: delete,删除
SQL操作基本语法:SQL是一条一条的指令,每条指令以语句结束符结束:";" , "g" , "G"
";"与"g"本质效果是一样; "G"将结果纵向显示
SQL中也有不少注释:
- -- : 两个中划线 + 空格 + 注释内容(单行注释)
- # : 单行注释
- /**/ : 块注释
一、库操作
对数据库进行增删改查
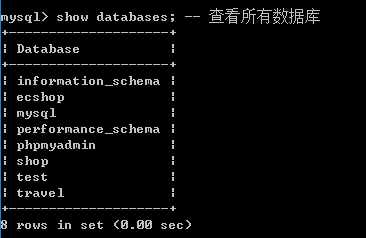
1. 查看数据库
基本语法1:
show databases; -- 查看所有的数据库
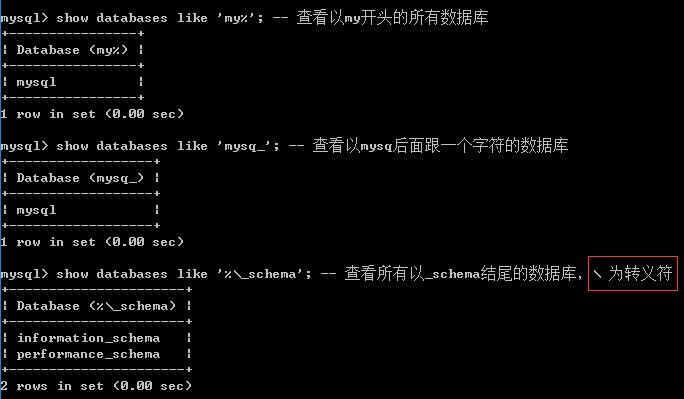
查看语法2:
show databases like 'pattern'; -- 模糊匹配
单字符匹配: _, 匹配指定位置的一个字符
多字符匹配:%, 匹配指定位置的多个字符
查看语法3:
show create database 数据库名字; -- 查看数据库的创建语句

2. 新增数据库
创建数据库基本语法
create database 数据库名字 [库选项];
库选项: 数据库的其他特性: 主要是两种
- charset 字符集: 设定数据库内部的数据存储的字符集
- collate 校对集: 设定数据库内部的数据的比较方式

这条语句的执行会发生什么呢?
1、会在数据库空间中产生一个叫做mydb的数据库

2、凡是创建的实体数据库都会在mysql的数据文件夹产生一个对应名字的数据库文件夹
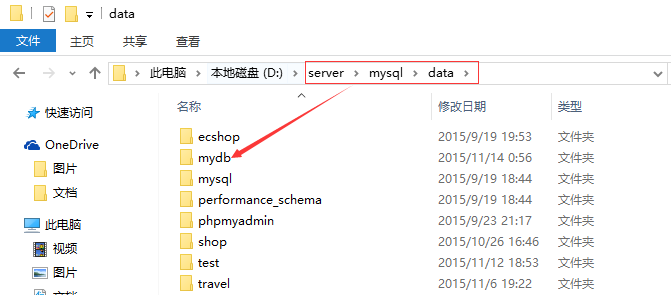
3、在对应的数据库里面(文件夹内部)还会产生一个db.opt文件,保存了库选项: 校对集是依赖字符集存在

数据库的命名规范:
1、字母,下划线和数字构成, 不能以数字开头
2、若要使用关键字(系统已经使用)或者保留字(系统将要使用), 必须对关键字名字加上反引号(ESC键下的~对应的英文状态下的输出: `)

3、理论上,数据库名字支持中文: 但是需要设定字符集

4、中文数据库建立的文件夹会是额外编码(utf8-->GBK)

3. 修改数据库
数据库是不能修改名字的: 只能修改数据库的库选项(字符集和校对集)
alter database 数据库名字 新的字符集 新的校对集;

4. 删除数据库
删除数据库是一种结构操作: drop
drop database 数据库名字; -- 一次只能删除一个数据库


数据库删除到底发生了什么?
1、在库结构空间中会自动删除mydatabase数据库
2、在数据库存储数据的文件夹下(data)将数据库对应的文件夹整体删掉: 内部的所有内容全部都被删除
注意: 数据库不要轻易使用drop、一旦删除了,数据就永远找不回来了
二、表操作
1. 新增数据表
基本语法
create table 表名 ( -- 所有的字段必须要有字段类型: 限制数据的格式 字段名 字段类型(数据类型), 字段名 字段类型 -- 最后一个不需要逗号分隔 ) [表选项];
表选项:增加表的限制
- 字符集: charset 具体字符集
- 校对集: collate 具体的校对集
- 存储引擎: engine 具体的存储引擎(innodb默认的和myisam)
表是属于数据库的:创建表的时候必须指定表所属数据库.
方案1: 显示的指定数据库: 在表名之前增加要指定的数据库名字.表名

方案2: 隐式的指定数据库: 首先进入到数据库环境: use 数据库名字;
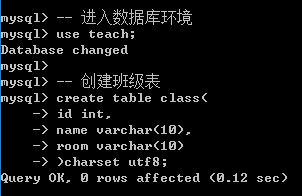
方案3: 从已有表可以直接创建表: 可以省去字段的麻烦(获取结构: 不会获取数据)
create table 表名 like 数据库.表名; -- 创建一张表象指定数据库里面的某张表

备份或者进行数据库迁移的时候有可能用到.
创建数据表的语句执行之后会发生什么呢?
1、会在数据库环境下增加对应的数据表

2、会在对应的数据库文件夹下创建对应的数据表结构文件,frm是存储表结构的文件

2. 查看数据表
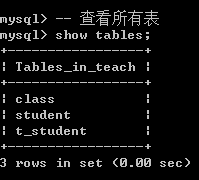
方案1: 查看所有表
show tables;
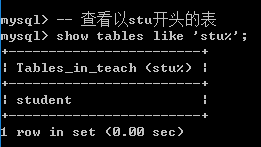
方案2: 模糊匹配
show tables like 'pattern';
方案3: 查看数据表的创建语句
show create table 表名;

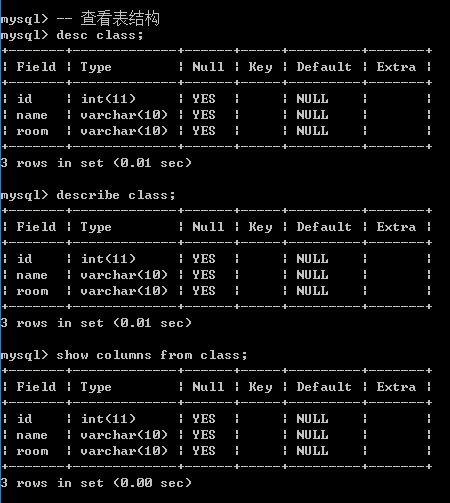
方案4: 查看表结构
desc/describe/show columns from 表名;
3. 修改数据表
表有自己的内容: 表名和表选项; 表还有额外的内容(字段)
维护表自身: 表名和表选项
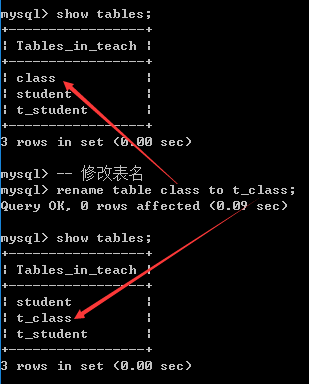
修改表名: 可以修改
rename table 旧表名 to 新表名;
修改表选项: 字符集,校对集或者存储引擎
alter table 表名 [charset 字符集] [collate 校对集] [engine = 存储引擎];

维护字段: 字段的增删改
字段的细节操作很多
alter table 表名 add/drop/change/modify 字段 字段类型 [位置];
位置分为两种: first和after 字段名
增加字段

修改字段: 修改字段本身(名字),修改字段的数据类型
修改字段名
change 旧名字 新名字 字段类型 [位置];

修改字段的数据类型
modify 字段名 字段类型 [位置];

删除字段: 不要字段
alter table 表名 drop 字段名;

4. 删除数据表
基本语法
drop table 表名1[,表名2...];

删除语句执行后到底发生了什么?
1、数据库空间会删除对应的表;
2、数据库文件夹对应的表结构文件(如果是myisam表会删除三个文件)
注: 正是因为数据表的删除会一次性的将表结构, 数据以及对应的索引全部删除: 如果是误删, 找不回来. 需要特别谨慎操作: 先备份后操作.
三、数据操作
1. 新增数据
如果没有指定字段列表,那么值列表里面的数据的顺序必须完全按照字段的定义顺序存放
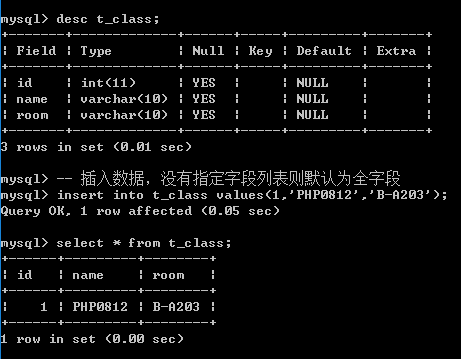
如果有指定字段列表: 字段列表里面的字段顺序与定义表的时候的顺序无关: 但是要求值的顺序也要跟指定的字段的顺序一致

2. 查看数据
基本语法
select 字段列表/* from 表名 where 条件判断;
条件判断: 是针对记录数
字段列表: 是针对字段数

指定字段列表: 顺序与定义的字段顺序无关

限制数据: where条件判断(where对每一条记录都进行条件匹配,匹配成功保留,失败就不获取)

3. 修改数据
修改指定记录中的某个字段的数据
Update 表名 set 字段名=新的值[,字段名=新的值] [where条件];
如果不使用where条件限定: 修改所有数据.
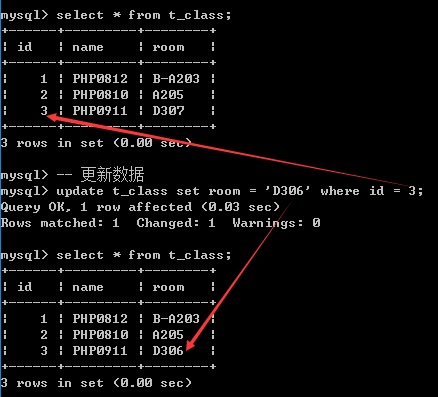
注: 修改数据是一种不可逆的操作, 更新需谨慎(一定要带where条件限定)
4. 删除数据
删除基本语法
delete from 表名 [where条件]; -- 如果没有指定条件: 全表删除
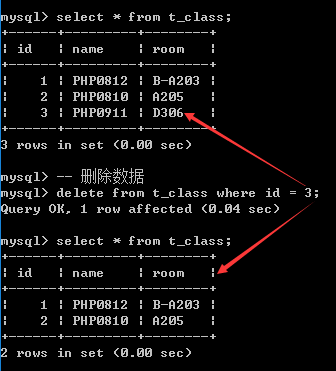
注: 删除数据是不可逆的, 需要谨慎操作.(备份)