前面已经对 RNN (递归神经网络) 的变体 (主要为解决 梯度消失和梯度爆炸) 接触了两个比较流行的 LSTM 和 GRU, 其核心思想呢, 是通过其所谓 **"gate" **向量存储 (store) RNN 更早期状态的 RNN, 通常就可以先用 LSTM 来试试看, 然后等结构稍微稳定写, 就可用 GRU 来训练参数 (gate 只有2 个) .
普遍来看, 神经网络都会有梯度消失 和梯度爆炸的问题, 其根源在于现在的神经网络在训练的时候, 大多都是 基于 BP 算法, 这种误差向后传递的方式, 之前咱也推导过数学公式, 多元函数求偏导, 注意链式法则, 会产生 vanishing. 而 RNN 产生梯度消失的根源是 权值矩阵复用.
反正是个难点哦, 不扯了, 这里主要是想在补充两种 RNN 的变体, 双向和多层RNN.
Bidirectional RNN
双向的 RNN , 典型的栗子是, 情感分析这块. (假设是通过一个评价, 来判断情感是 positive 还是 negative.)
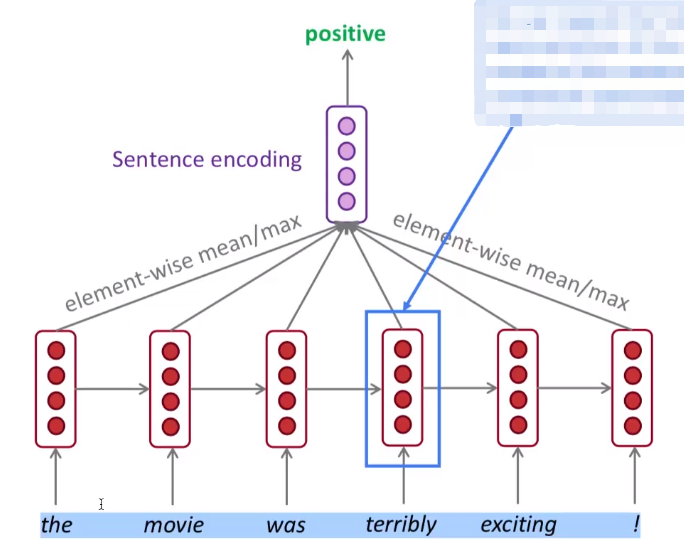
然后看这个评价: the movie was terribly exciting. 我们人可以轻松来判断, 结合整句话, 就是觉得电影很棒呀. 然而, 机器可就不一定了哦, 因为这里有个词 terribly 意味非常糟糕. 当咱从左往右看的时候, 如果不看最后一个单词, 直接到 "The movie was terribly" 就是消极的评价呀. 因而可以发现, 在这个栗子中, 最后一个词 exciting 相当于把前面的句子给 "反转" 了.
为了解决这个问题, 就引入了所谓 反转 RNN 跟双向链表似的, 正面来一遍输入, 反向也来一遍输入.
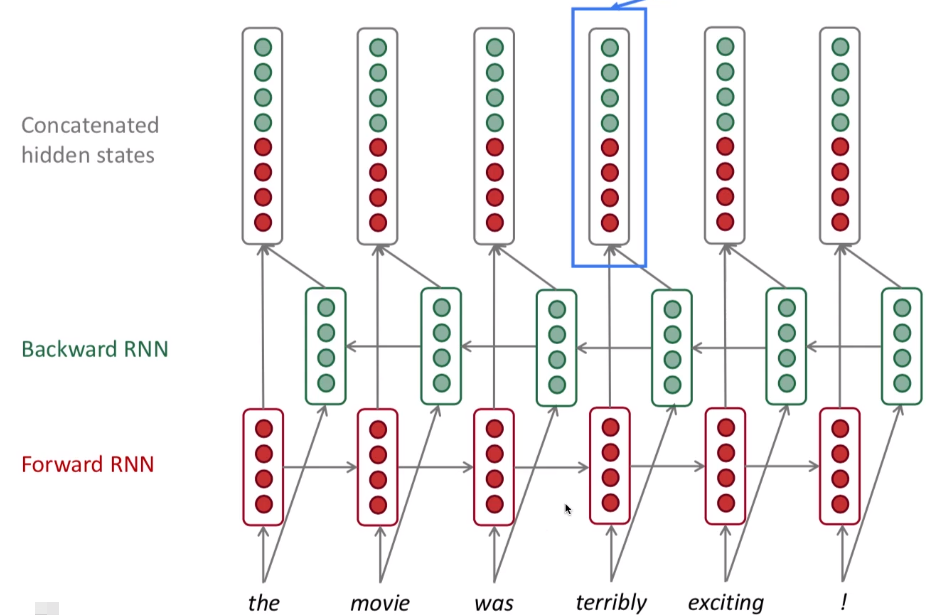
这样分别从 左边和右边 都来作一个输入, 就能够将 每个词, 作用于 上下文了呀 (context)
用符号化的方式来描述, 是这样的:
(Forward RNN ightarrow h^{(t)} = RNN_{FW} (h^{ ightarrow (t-1)}, x ^{(t)}))
这种从左往右的, This is general notation to mean "compute one forward step of the RNN", - it could be a vanilla, LSTM or GRu computation.
然后就是这种从右到左的.
(Backward RNN leftarrow h^{(t)} = RNN_{FW} (h^{leftarrow (t-1)}, x ^{(t)}))
Generally, these two RNNs have separate weights, 就是从左到右, 从右到左, 各有一个权值矩阵 W
连接的隐含状态: (h^{(t)} = [h^{ ightarrow (t)}; h^{leftarrow(t)}]) We regard this as "the hidden state" of a bidirectional RNN (双向RNN)
This is what we pass on to the next parts of the network.
应用场景
Note: bidirectional RNNs are only applicable (适用于) if you have access to the entire input sequence 应用在已经知道全部句子的前提下.
They are not applicable to Language Modeling, because in LM you only have left context available. 用来做情感分析是可以的, 都知道嘛, 但语言模型就不行了, 它不是用来做预测下一个单词的.
If you do have entire input sequence, 那单向, 或者双向, 你开心就好的呀.
For example, BERT (Bidirectional Encoder Representations Transformers) 这个bert 还不知咱翻译, 上次在B站看到大佬在讲bert 感觉非常厉害的样子. is a powerful pretrained contextual (处理上下文) representation system built on bidrectionality.
Multi - layer RNNs
RNNs are already "deep" on one dimension (they unroll over many timesteps) 在时间轴上, 让网络深度增加.
We can also make them "deep" in another dimension by applying multiple RNNs - this is a multi-layer RNN. 就是, (隐含层) 上层的特征, 又作为下一层的输入, 这样的, 感觉好像也不太好理解哦.
This allows the network to compute more complex representations.
The lower RNNs should compute lower-lever features and the higher RNNs should compute highter-lever features.
Multi-layer RNN are also called stacked RNNs.

The hidden states from RNN layer i are the inputs to RNN layer i+1.
特点
High-performing RNNs are often multi-layer 通常预测效果很好的 RNN 都是多层的结构. 但这个深度呢, 也不会像普通的全连接层网络 (feed-forward network), 和 卷积神经网络 (convolutional) 那样深哦.
在 2017年, 有些老铁做实验, 说在机器翻译这块, 2-4层 is best for the encoder RNN, and 4 layers is best for the decoder RNN. 这也是 我一直不是很关注神经网络这块的原因, 很多都是经验性, 试验性的东西. 总是会少了一点 理论的美感, 比如回看一下 SVM, XGboost ... 这些理论就特别完美.
还有说像 Transformer - based network 比如 BERT, can be up to 24 layer. 当然这种在训练的时候, 需要大量地使用 skipping-like connectiions.
小结
主要是熟悉下一些常见的 RNN 变体和其中心思想和应用场景
- LSTM 应用非常广泛, GRU 会更快一些, "gate" 比 LSTM 要少呀,至少
- 梯度消失, 梯度爆炸的常用解决办法, 比如梯度爆炸, 可以用 clip 的方式来缓解
- 双向 (Bidirectional ) 的RNN, 可用在情感分析这块, 因为是知道上下文的嘛.
- 多层 (Multi-layer) RNN 效果很好,但可能会常用到 skip connections 的方式哦.
RNN 就到这了, 后面我在去学下 tensorflow 或 pytorch 这类的框架, 来调参搞些案例玩一玩.