1. 前言
无论是学生还是工作,都会和ppt打交道,每次制作ppt都需要去找模板,有时候ppt模板还是收费的,这......,有点恶心,哈哈哈!!
今天教大家如何使用python爬虫爬取1万份『ppt模板』,以后制作ppt再也不怕了没有模板了!!!
2. 相关介绍
1.模板来源
https://sc.chinaz.com/ppt/free_1.html

每页20条,一共500页,共10000份ppt模板!
2.爬虫思路
-
先遍历每一页,获取每一个ppt模板的url。
-
根据ppt模板的url获取下载地址。
-
最后根据下载地址将文件下载到本地。
3. 爬取数据
1.遍历每一页

通过xpath可以定位到标签class=bot-div,里面包含了ppt模板的url和名称。
import requests
from lxml import etree
###遍历每一页
def getlist():
for k in range(1,501):
url = "https://sc.chinaz.com/ppt/free_"+str(k)+".html"
res = requests.get(url)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
list = selector.xpath('//*[@class="bot-div"]')
for i in list:
title = i.xpath('.//a/text()')[0].replace("
", '').replace(" ", '')
href = i.xpath('.//a/@href')[0].replace("
", '').replace(" ", '')
print(title)
print(href)
print("----------------")
遍历时需要获取每一个ppt模板url(title)和名称(href)(方便下载时作为保存文件的命名)

2.获取下载地址
以下面url为例
https://sc.chinaz.com/ppt/210305465710.htm

解析下载链接
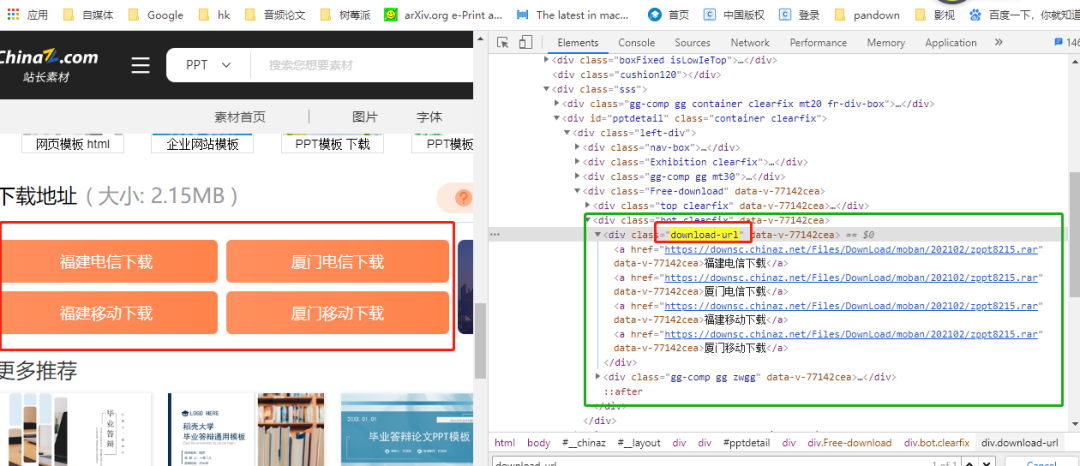
通过xpath可以定位到标签class=download-url,里面包含了四个下载地址,其实四个都一样,选择其中一个就可以了。
res = requests.get(url)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
href = selector.xpath('//*[@class="download-url"]/a/@href')[0]
print(href)

3.下载保存
根据拿到的下载地址下载文件保存到本地。
r = requests.get(href)
with open(str(title)+".rar", "wb") as code:
code.write(r.content)


ok,这样就将ppt模板下载到本地了。
下面我们开始批量下载!
4.批量下载
##下载文件
def download(url,title):
res = requests.get(url)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
href = selector.xpath('//*[@class="download-url"]/a/@href')[0]
r = requests.get(href)
with open(str(title)+".rar", "wb") as code:
code.write(r.content)
print(str(title)+":下载完成!")
###遍历每一页
def getlist():
for k in range(1,501):
url = "https://sc.chinaz.com/ppt/free_"+str(k)+".html"
res = requests.get(url)
res.encoding = 'utf-8'
text = res.text
selector = etree.HTML(text)
list = selector.xpath('//*[@class="bot-div"]')
for i in list:
title = i.xpath('.//a/text()')[0].replace("
", '').replace(" ", '')
href = i.xpath('.//a/@href')[0].replace("
", '').replace(" ", '')
download("https://sc.chinaz.com/"+str(href), str(title))

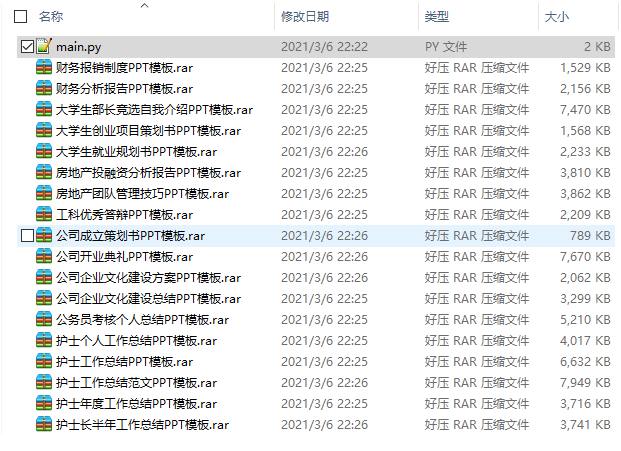
这样就可以将10000份ppt模板下载完毕!
4. 总结
通过python编程实现爬取10000份ppt模板素材,以后再也不用担心制作ppt没有模板了!