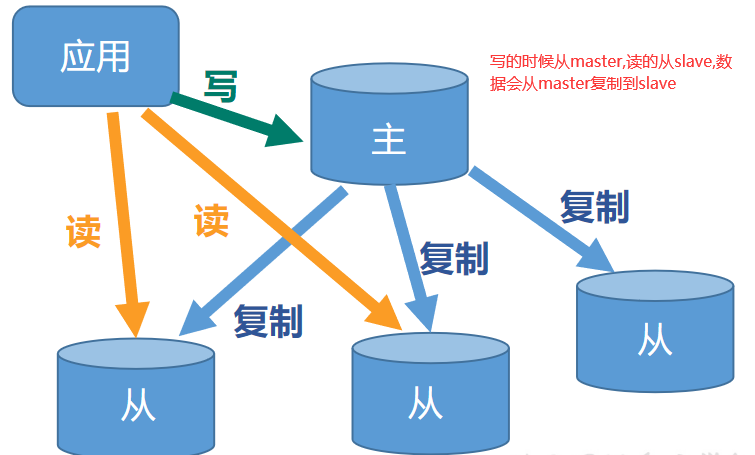
主从复制
就是主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
用处
读写分离,性能扩展
容灾快速恢复
示意图:
配置Redis
1、拷贝多个redis.conf文件include,因为redis.conf可以配置共有的配置。如果有不同,include后,可以自行配置,会覆盖redis.conf中的配置。
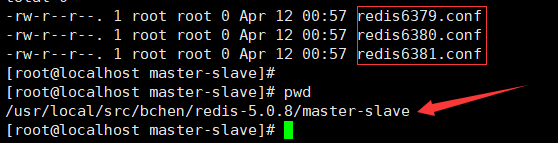
首先在主目录下,新建master-slave文件夹(其实就是随便建个目录放文件),里面添加不同端口的配置文件,起3个服务,形成三个redis节点。
同时include共有的配置:
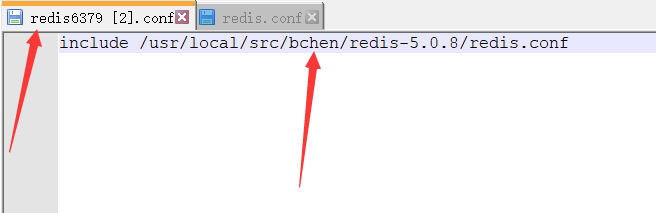
然后,共有的配置到redis.conf中修改,不同的配置在单独的配置文件中修改。
2、开启daemonize yes
使用的是一台机器启动多个服务的方法,所以需要配置后台启动。
在redis.conf中:
# By default Redis does not run as a daemon. Use 'yes' if you need it. # Note that Redis will write a pid file in /var/run/redis.pid when daemonized. daemonize yes
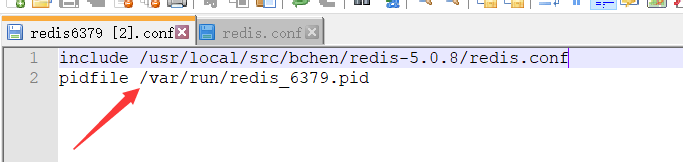
3、Pid文件名字pidfile
这个在redis.conf中找到,各自配置下,如果是单独的机器,这个不用配置:
pidfile /var/run/redis_6379.pid
4、指定端口
port 6379

5、Log文件名字
logfile /usr/local/src/bchen/redis-5.0.8/master-slave/file_6379.log
6、Dump.rdb名字dbfilename,涉及到一个文件名称和一个路径名称
dbfilename dump_6379.rdb
dir /usr/local/src/bchen/redis-5.0.8/master-slave
7、Appendonly 关掉或者换名字
这个是aof持久化相关的,我们可以不用配置,直接关了就好,有开rdb就可以了。直接在共有的redis.conf中配置。
appendonly no
其实默认就是no。
8、其他实例也配置下,最终配置文件长这样:
6379:
include /usr/local/src/bchen/redis-5.0.8/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
logfile /usr/local/src/bchen/redis-5.0.8/master-slave/file_6379.log
dbfilename dump_6379.rdb
dir /usr/local/src/bchen/redis-5.0.8/master-slave
6380:
include /usr/local/src/bchen/redis-5.0.8/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
logfile /usr/local/src/bchen/redis-5.0.8/master-slave/file_6379.log
dbfilename dump_6380.rdb
dir /usr/local/src/bchen/redis-5.0.8/master-slave
6381:
include /usr/local/src/bchen/redis-5.0.8/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
logfile /usr/local/src/bchen/redis-5.0.8/master-slave/file_6379.log
dbfilename dump_6381.rdb
dir /usr/local/src/bchen/redis-5.0.8/master-slave
启动
启动命令

查看进程:

三个pid文件:
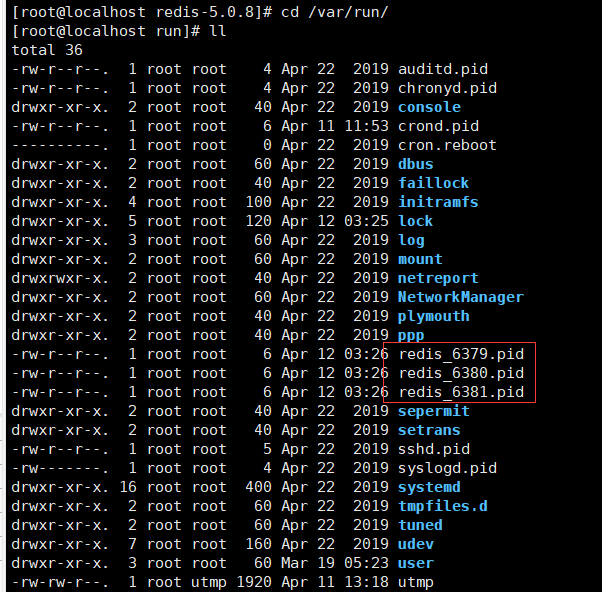
日志文件:
搭建简单的一主二仆模式
这三个实例其实现在是互不关联的,需要额外的操作使之互相起作用。
先熟悉两个重要的命令:
info replication:打印主从复制的相关信息
slaveof <ip> <port> : 成为某个实例的从服务器,相当于现在的小弟找大哥。
先三台机器各自执行下,info replication命令:


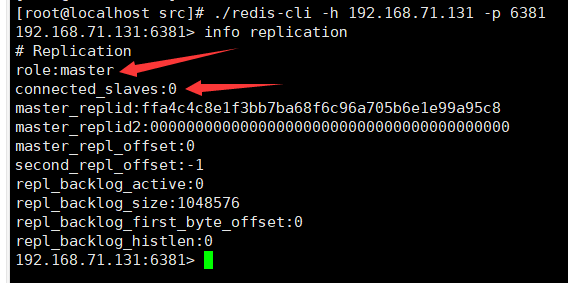
可以看到初始角色全部都是master。
接下来把6380和6381配置slave。
192.168.71.131:6381> slaveof 192.168.71.131 6379
OK
192.168.71.131:6380> slaveof 192.168.71.131 6379
OK
查看下主从关系:
192.168.71.131:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.71.131,port=6381,state=online,offset=392,lag=0 slave1:ip=192.168.71.131,port=6380,state=online,offset=392,lag=0 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:392 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:392
192.168.71.131:6380> info replication # Replication role:slave master_host:192.168.71.131 master_port:6379 master_link_status:up master_last_io_seconds_ago:4 master_sync_in_progress:0 slave_repl_offset:378 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:378 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:323 repl_backlog_histlen:56
192.168.71.131:6381> info replication # Replication role:slave master_host:192.168.71.131 master_port:6379 master_link_status:up master_last_io_seconds_ago:9 master_sync_in_progress:0 slave_repl_offset:392 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:392 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:392
可以看到6379已经变成了master, 6380和6381为slave。
测试主从复制
尝试从slave(6380)写入:
192.168.71.131:6380> select 0 OK 192.168.71.131:6380> keys * (empty list or set) 192.168.71.131:6380> set k1 v1 (error) READONLY You can't write against a read only replica.
报错!
尝试从master写入:
192.168.71.131:6379> 192.168.71.131:6379> SELECT 0 OK 192.168.71.131:6379> keys * (empty list or set) 192.168.71.131:6379> set k1 v1 OK 192.168.71.131:6379> get k1 "v1"
可以看到master可以写入也可以读取。
再从slave中读取数据:
192.168.71.131:6380> get k1
"v1"
6380中可以读取到,同样的6381中也可以读取到。
问题刨析
1、从机是否可以写?set可否?
以上已经测试过了,可以看出从机不能写,只能读。
2、切入点问题。slave第一次加入进来,是从头开始复制还是从切入点开始复制。
先把6380(或者6381)关闭掉,然后启动,删除所有数据,然后重新接入到6379成为slave,看下6380能否有之前的数据。

可以看到没有6380这个进程,然后看下6379的主从关系。
[root@localhost src]# ./redis-cli -h 192.168.71.131 -p 6379 192.168.71.131:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.71.131,port=6381,state=online,offset=12652,lag=1 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:12652 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:12652
这时候没有了6380这个slave。
启动6380
[root@localhost src]# ./redis-server ../master-slave/redis6380.conf [root@localhost src]# ps -ef | grep redis root 86740 1 0 03:26 ? 00:00:12 ./redis-server 192.168.71.131:6379 root 86750 1 0 03:26 ? 00:00:11 ./redis-server 192.168.71.131:6381 root 86941 86919 0 07:33 pts/0 00:00:00 ./redis-cli -h 192.168.71.131 -p 6379 root 86967 1 0 07:36 ? 00:00:00 ./redis-server 192.168.71.131:6380 root 86972 86946 0 07:36 pts/2 00:00:00 grep --color=auto redis
再次查看6379:
192.168.71.131:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.71.131,port=6381,state=online,offset=13002,lag=1 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:13002 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:13002
可以看出,slave不会保存上次的记忆,不会自动成为79的从机。
这时候,我们把6380的数据全部清空。
[root@localhost src]# ./redis-cli -h 192.168.71.131 -p 6380 192.168.71.131:6380> keys * 1) "k1" 192.168.71.131:6380> FLUSHALL OK 192.168.71.131:6380> keys * (empty list or set)
然后再让它成为6379的从机:
192.168.71.131:6380> slaveof 192.168.71.131 6379
OK
192.168.71.131:6380> keys *
1) "k1"
发现6380已经把全部数据同步过来了。并从新成为6379的slave。
当一个全新的节点成为某个master的slave的时候,他会从master那边同步一份最全的数据过来,而并不是从切入点开始复制。
3、其中一台从机运行了一段时间,然后down后情况如何?再次接入后,是怎么样的?
shutdown 8081
192.168.71.131:6381> shutdown
not connected>
查看6379(要稍微等一会)
192.168.71.131:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.71.131,port=6380,state=online,offset=25070,lag=1 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:25070 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:25070 192.168.71.131:6379> info replication # Replication role:master connected_slaves:1 slave0:ip=192.168.71.131,port=6380,state=online,offset=25140,lag=0 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:25140 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:25140
然后对6379写入新的键值对:
192.168.71.131:6379> set k2 v2 OK 192.168.71.131:6379> set k3 v3 OK
192.168.71.131:6379> keys * 1) "k3" 2) "k1" 3) "k2"
192.168.71.131:6380> keys * 1) "k3" 2) "k2" 3) "k1"
在6379和6380中都可以看到值的变化。
这时候启动8081,并执行slaveof命令,成为6379的slave。
[root@localhost src]# ./redis-server ../master-slave/redis6381.conf [root@localhost src]# ps -aux | grep redis root 86740 0.0 0.0 145188 2300 ? Ssl 03:26 0:20 ./redis-server 192.168.71.131:6379 root 86967 0.0 0.0 145188 2316 ? Ssl 07:36 0:07 ./redis-server 192.168.71.131:6380 root 87119 0.0 0.0 14080 1208 pts/0 S+ 09:56 0:00 ./redis-cli -h 192.168.71.131 -p 6379 root 87120 0.0 0.0 14080 1200 pts/1 S+ 09:56 0:00 ./redis-cli -h 192.168.71.131 -p 6380 root 87145 0.0 0.0 144024 2040 ? Ssl 10:06 0:00 ./redis-server 192.168.71.131:6381 root 87150 0.0 0.0 112720 952 pts/2 S+ 10:06 0:00 grep --color=auto redis [root@localhost src]# ./redis-cli -h 192.168.71.131 -p 6381 192.168.71.131:6381> keys * 1) "k1" 192.168.71.131:6381> SLAVEOF 192.168.71.131 6379 OK 192.168.71.131:6381> keys * 1) "k2" 2) "k3" 3) "k1"
可以看到重新成为slave的时候,可以重新拿数据,从而跟上大部队。
4、主机shutdown后情况如何?从机是上位成为master还是原地待命
192.168.71.131:6379> SHUTDOWN
not connected> exit
关闭6379后。
稍微等会,再查看6380和6381的情况
192.168.71.131:6380> info replication # Replication role:slave master_host:192.168.71.131 master_port:6379 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:25949 master_link_down_since_seconds:113 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:25949 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:13311 repl_backlog_histlen:12639
192.168.71.131:6381> info replication # Replication role:slave master_host:192.168.71.131 master_port:6379 master_link_status:down master_last_io_seconds_ago:-1 master_sync_in_progress:0 slave_repl_offset:25949 master_link_down_since_seconds:148 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:119b5221a7a59fa0bae8b405aa9bc09074ee0c11 master_replid2:0000000000000000000000000000000000000000 master_repl_offset:25949 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:25698 repl_backlog_histlen:252
可以看到如果slave没有人为的额外的操作,仍然只是一个slave的角色。 不会上位成为master。
5、主机又回来了后,主机新增记录,从机还能否顺利复制?
现在我们启动6379
[root@localhost src]# ./redis-server ../master-slave/redis6379.conf [root@localhost src]# ps -aux | grep redis root 86967 0.0 0.0 145184 2308 ? Ssl 07:36 0:07 ./redis-server 192.168.71.131:6380 root 87120 0.0 0.0 14080 1204 pts/1 S+ 09:56 0:00 ./redis-cli -h 192.168.71.131 -p 6380 root 87145 0.0 0.0 145168 2280 ? Ssl 10:06 0:00 ./redis-server 192.168.71.131:6381 root 87151 0.0 0.0 14080 1212 pts/2 S+ 10:07 0:00 ./redis-cli -h 192.168.71.131 -p 6381 root 87155 0.0 0.0 145172 2232 ? Ssl 10:17 0:00 ./redis-server 192.168.71.131:6379 root 87162 0.0 0.0 112720 956 pts/0 S+ 10:17 0:00 grep --color=auto redis
查看下信息:
192.168.71.131:6379> info replication # Replication role:master connected_slaves:2 slave0:ip=192.168.71.131,port=6380,state=online,offset=210,lag=0 slave1:ip=192.168.71.131,port=6381,state=online,offset=196,lag=1 master_replid:33bfcec0a2af6009b3e21df66a6bac7aeabcf64d master_replid2:0000000000000000000000000000000000000000 master_repl_offset:210 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:210
测试能否正常工作:
192.168.71.131:6379> set k4 v4
OK
192.168.71.131:6380> get k4
"v4"
192.168.71.131:6381> get k4
"v4"
可以正常工作。
当down掉的master重新回来的时候,是不用额外的操作,redis自动会维持原有的主从关系,并可以正常工作。
复制原理
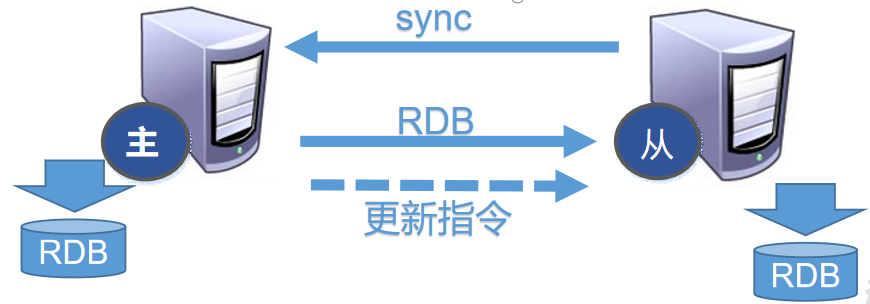
1、每次从机联通后,都会给主机发送sync指令
2、主机立刻进行存盘操作,发送RDB文件,给从机
3、从机收到RDB文件后,进行全盘加载
4、之后每次主机的写操作,都会立刻发送给从机,从机执行相同的命令
搭建树形的主从关系
上面的关系,主要存在的问题是: master如果下面有多个slave那么master的同步操作开销很大,因为从机数量太多。
我们由此想到:上一个slave可以是下一个slave的Master,slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
缺点: 风险是一旦某个slave宕机,后面的slave都没法备份。因为这是一种类似于树形的主从关系。如果有一个slave节点的挂了,那么对应的所有子树将全部没办法写了。
我们可以测试搭建6379->6380->6381的这种主从关系。
[root@VM_0_8_centos src]# ./redis-cli -h localhost -p 6380 localhost:6380> slaveof localhost 6379 OK localhost:6380>
127.0.0.1:6381> slaveof 127.0.0.1 6380
OK
我们查看6380,可以看出这个时候,角色是slave, 但是有对于6379来讲是从机,对于6381来讲是主机:

虽然对于6381来讲是主机,但是也是不允许写入的。我们可以测试如下:
127.0.0.1:6380> set k2 v2
(error) READONLY You can't write against a read only replica.
哨兵机制
我门想到一个问题:如果以上的主从关系中:6379->6380->6381,当6379挂掉了以后:如何让6380上位?
即执行:用 slaveof no one 将从机变为主机。(必须手动执行)。
哨兵机制其实就是反客为主的自动版。
我首先建个sentinel.conf的文件,然后填写:
sentinel monitor mymaster 127.0.0.1 6379 1
其中mymaster为监控对象起的服务器名称, 1 为 至少有多少个哨兵同意迁移的数量。
启动哨兵, 通过src目录下的redis-sentinel:


这边哨兵也可以自动获取到主从关系。
现在手动shutdown 6379看下,会怎么样:

从哨兵的日志可以看到,其实现在已经是6380做master了。可以验证下:
127.0.0.1:6380> info replication # Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6381,state=online,offset=15719,lag=0 master_replid:9fdc923e373621d1830cf52024edd2f1fc32096b master_replid2:5cdcc9b49def111a61014d745996f93bc9be07a4 master_repl_offset:15719 second_repl_offset:5099 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:15719 127.0.0.1:6380>
那如果现在重新启动6379,情况会怎么样?其实从哨兵的日志可以看出来,6379已经编程6380的slave了。我们再启动6379,然后验证:

总结:
当主机挂了后,哨兵会选择一个从机作为slave, 选择条件依次为: 1、选择优先级靠前的 2、选择偏移量最大的 3、选择runid最小的从服务
详解:什么是优先级靠前的?这个就要看主配置文件:slave-priority, (注:本人测试版本5.0.8,这个版本配置已经改成replica-priority),数字越小表示优先级越大,0表示永远不会被选为master。
那什么是偏移量最大的?因为master需要向slave写数据,当master 挂了以后,那个时刻可能各个slave同步到的数据有细微差异,会优先选择同步数据更多的。
那runid指每个redis实例启动后都会随机生成一个40位的runid。