作业要求:
比对软件很多,首先大家去收集一下,因为我们是带大家入门,请统一用hisat2,并且搞懂它的用法。
直接去hisat2的主页下载index文件即可,然后把fastq格式的reads比对上去得到sam文件。
接着用samtools把它转为bam文件,并且排序(注意N和P两种排序区别)索引好,载入IGV,再截图几个基因看看!
顺便对bam文件进行简单QC,参考直播我的基因组系列。
【1】选择比对工具
Hisat2 或 STAR(本次选择Hisat2)
【2】下载hisat2的index文件(就是参考基因组)
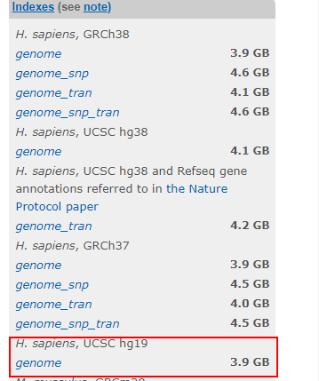
1、进入hisat2官网,主页面右侧中间位置,
右击“H.sapiens,UCSC hg19”下面的genome,“复制链接地址”
2、Ubuntu终端命令行下载
1 # 切换到下载目录 2 $ cd ~/src 3 $ wget ftp://ftp.ccb.jhu.edu/pub/infphilo/hisat2/data/hg19.tar.gz 4 5 # 解压下载后的文件 6 $ tar -zxvf hg19.tar.gz
补充:
(1)可以在Windows系统中用迅雷下载,这样下载比较快
(2)若没有现成的index,可以通过HISAT2的方法创建
1 # 其实hisat2-buld在运行的时候也会自己寻找exons和splice_sites,但是先做的目的是为了提高运行效率 2 $ extract_exons.py gencode.v26lift37.annotation.sorted.gtf > hg19.exons.gtf &extract_splice_sites.py gencode.v26lift37.annotation.gtf > hg19.splice_sites.gtf & 3 # 建立index, 必须选项是基因组所在文件路径和输出的前缀 4 $ hisat2-build --ss hg19.splice_sites.gtf --exon hg19.exons.gtf genome/hg19/hg19.fa hg19
【3】正式比对
# 编写批量比对的脚本 hisat2_align.sh for i in `seq 56 58` do hisat2 -t -x reference/index/hg19/genome -1 RNA-Seq/SRR35899${i}_1.fastq.gz -2 RNA-Seq/SRR35899${i}_2.fastq.gz -S RNA-Seq/aligned/SRR35899${i}.sam & done # 运行脚本 hisat2_align.sh $ bash hisat2_align.sh
# hisat2用法
$ hisat2 [options]* -x <hisat2-idx> {-1 <m1> -2 <m2> | -U <r> | --sra-acc <SRA accession number>} [-S <hit>]
# -x index : 参考基因组
# 双端测序:hisat2 -x hisat2_index -1 m1 -2 m2 -S name.sam
# 单端测序:hisat2 -x hisat2_index -U r1 -S name.sam
比对结果解释:
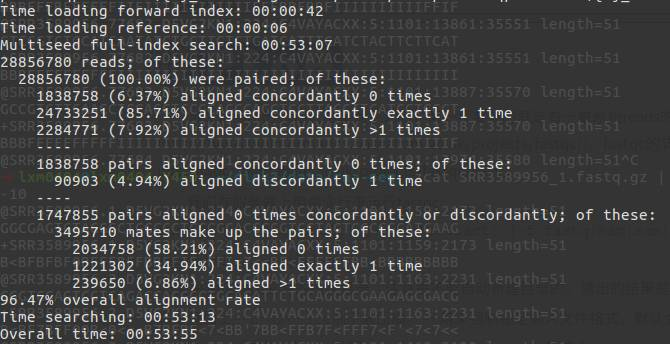
1、全部数据都是100%的,6.37%的数据一次都没有比对,85.71%的数据是唯一比对,7.92%是多个比对。
2、然后6.37%的一次都没有比对的数据,如果不按照顺序来,有4.94%的比对。
3、之后把剩下的部分用单端数据进行比对的话,58.21%数据没比对上,34.94%的数据比对一次,6.86%比对超过一次。
4、零零总总的加起来是96.47%的比对!!
【4】sam格式转换成bam格式
1 # 编写脚本 2 for i in `seq 56 58` 3 do 4 samtools view -S SRR35899${i}.sam -b > SRR35899${i}.bam #转换成bam文件 5 samtools sort SRR35899${i}.bam -o SRR35899${i}_sorted.bam #采用默认方式排序 6 samtools index SRR35899${i}_sorted.bam #生成索引 7 done
【5】比对结果QC
QC软件有很多,这里我们使用RSeQC
-
RSeQC——http://rseqc.sourceforge.net/
-
Qualimap——http://qualimap.bioinfo.cipf.es/
-
Picard——http://broadinstitute.github.io/picard/
使用RSeQC进行比对结果QC
1、安装RSeQC
1 # RSeQC的安装,需要先安装gcc;numpy;R;Python2.7,这里比较难装的就是numpy——可以直接利用anaconda安装(http://www.jianshu.com/p/14fd4de54402) 2 # 我的环境已经配置好了,所以直接可以用pip命令安装 3 $ conda install RSeQC 4 5 # 进入存放bam文件的目录 6 $ cd 7 # 对bam文件进行质控,其余都同样的进行 8 $ bam_stat.py -i SRR3589956_sorted.bam
2、分析并查看结果
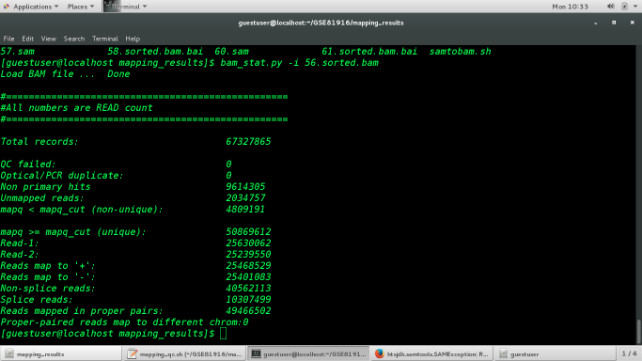
总read数是67327865,其中能够比对上的有49466502,所以mapped的比率是73.5%,符合人类的70%~90%的结果
3、比对到基因组各种原件上的情况: (基因组覆盖率的QC)
bed文件的下载:
hg19:https://sourceforge.net/projects/rseqc/files/BED/Human_Homo_sapiens/
mm10:https://sourceforge.net/projects/rseqc/files/BED/Mouse_Mus_musculus/
两个都选择RefSeq
bed文件还可以用gtf文件转换,网上也有很多写好的脚本可以用。
开始分析:
$ read_distribution.py -i RNA-Seq/aligned/SRR3589956_sorted.bam -r reference/hg19_RefSeq.bed
分析结果:
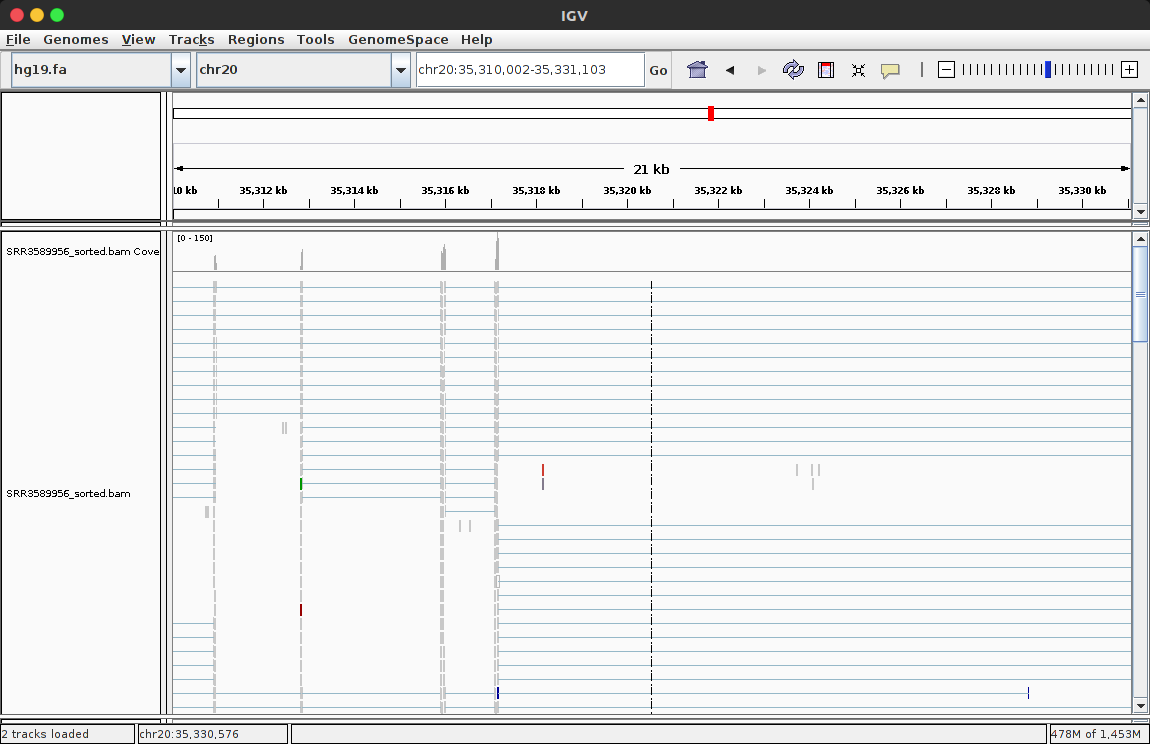
【6】IGV查看比对结果
载入参考基因组,基因组注释文件,很bam文件,看一些基因。
理论知识
RNA-Seq数据分析分为很多种:说找差异表达基因、寻找新的可变剪切……
【】找差异表达基因:单纯只需要确定不同的read计数就行的话,
可用工具:bowtie, bwa这类比对工具,或者是salmon这类align-free工具,并且后者的速度更快。
【】找到新的isoform,或者RNA的可变剪切,看看外显子使用差异的话
可用工具:TopHat, HISAT2或者是STAR这类工具用于找到剪切位点。
因为RNA-Seq不同于DNA-Seq,DNA在转录成mRNA的时候会把内含子部分去掉。所以mRNA反转的cDNA如果比对不到参考序列,会被分开,重新比对一次,判断中间是否有内含子。
文章:Gaining comprehensive biological insight into the transcriptome by performing a broad-spectrum RNA-seq analysis总结:
】二类错误(纳伪):hisat2最少
】一类错误(弃真):hisat2较高
】唯一比对:STAR最佳
】稳定性:STAR最佳
】速度:hisat2最快(HISAT2比STAR和TopHat2平均快上2.5~100倍)
序列比对实质:把reads和index进行比较
SAM(sequence alignment/mapping)数据格式
是一种序列比对格式标准, 由Sanger制定,是以TAB为分割符的文本格式。主要应用于测序序列mapping到基因组上的结果表示,当然也可以表示任意的多重比对结果
是目前高通量测序中存放比对数据的标准格式,当然他可以用于存放未比对的数据。
sam文件由:头文件和map结果组成
】头文件:由一行行以@起始的注释构成
】map结果:
每个read只占一行,只是它被tab分成了很多列,一共有12列,分别记录了:
1.read名称
2.SAM标记
3.chromosome号
4.5′端起始位置
5.MAPQ(mapping quality,描述比对的质量,数字越大,特异性越高)
6.CIGAR字串,记录插入,删除,错配以及splice junctions(后剪切拼接的接头)
7.mate名称,记录mate pair信息
8.mate的位置
9.模板的长度
10.read序列
11.read质量
12.程序用标记
处理SAM格式的工具主要是:SAMTools,SAMTools的主要功能如下:
view: BAM-SAM/SAM-BAM 转换和提取部分比对
sort: 比对排序
merge: 聚合多个排序比对
index: 索引排序比对
faidx: 建立FASTA索引,提取部分序列
tview: 文本格式查看序列
pileup: 产生基于位置的结果和 consensus/indel calling
最常用功能:格式转换、排序、索引
# 格式转换
$ samtools view -b test.sam > test.bam
# 排序
$ samtools sort test.bam -o test_sorted.bam # 采用默认方式排序
$ samtools sort -n test.bam -o test_sorted_n.bam # 根据reads名排序
# 索引
$ samtools index test_sorted.bam
常用的比对质控软件有:
1.Picard https://broadinstitute.github.io/picard/
2.RSeQC http://rseqc.sourceforge.net/
3.Qualimap http://qualimap.bioinfo.cipf.es/
RNA-Seq数据分析分为很多种
找差异表达基因或寻找新的可变剪切……