2018年是改革开放四十周年,也是互联网发展的重要一年。经历了区块链,人工智能潮的互联网行业逐渐迎来了冬天。这一年里有无数的事件发生着,正好学了python数据处理相关,那么就用python对18年的互联网事件进行一个简单的记录与分析。这里主要用了wordcloud和jieba。
首先来看一个数据表,这份excel表单几乎就是2018全年互联网圈发生的所有事件了。
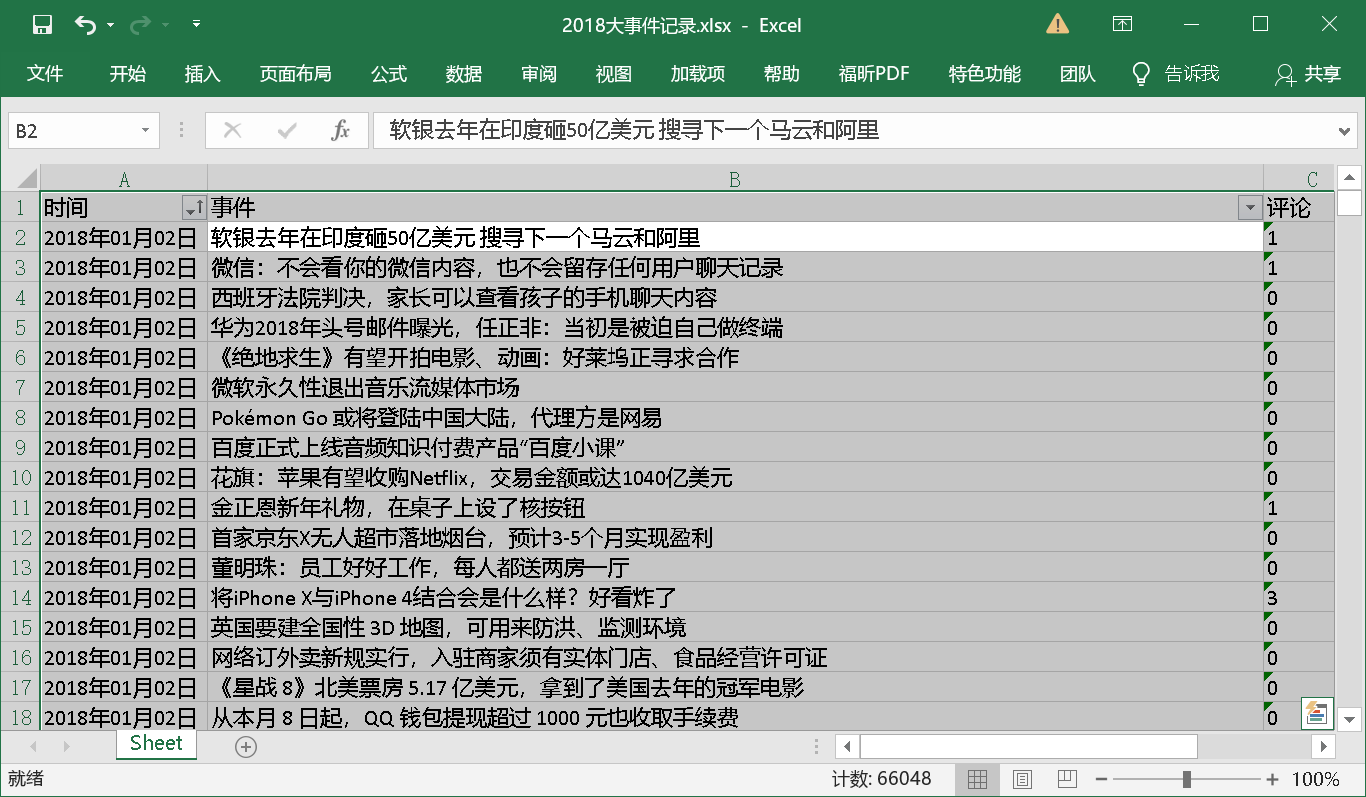
那么现在想要分析着数万条数据,可以用什么方法呢,我们首先会想到用可视化来呈现,图表展示也许会更清晰,但是这里我们选择用python中简单易用的词云来展示。
废话就不多说了,直接贴代码。
1 #copyright by pricechen 2 #几个常用库 3 import xlrd 4 import jieba 5 from wordcloud import WordCloud,ImageColorGenerator 6 import codecs 7 import imageio 8 9 #先把文件地址写好,对文件保存地址有需求的同学可以自行设置一下输入input 10 Savepath = 'E:\pricechen\data\' 11 filename = '2018大事件记录.xlsx' 12 month = ['01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12'] 13 14 #对内容进行封装 15 def fileHandle(Savepath,filename,month): 16 #打开excel文件 17 book = xlrd.open_workbook(Savepath+filename) 18 sheet = book.sheet_by_name('Sheet') 19 20 #处理新闻数据 21 for i in range(0,sheet.nrows): 22 #每一行内容 23 textLine = sheet.row_values(i) 24 # print(textLine) 25 #遍历月份 26 for data in month: 27 if textLine[0][5:7]==data: 28 #这里进行异常处理 29 try: 30 #写入以月份命名的文件夹 31 with open(Savepath+ data + '.txt', 'a+') as f: 32 f.write(textLine[1]+' ') 33 except FileNotFoundError:#文件不存在异常 34 continue 35 except UnicodeEncodeError:#编码异常 36 continue 37 38 def WCHandle(Savepath,month): 39 #处理词云图片 40 for i in range(0,12): 41 imagePath = Savepath + 'background\' + month[i] + '.jpg' 42 textPath = Savepath + month[i] +'.txt' 43 with codecs.open(textPath) as f: 44 text = f.read() 45 # cut_text = ' '.join(jieba.cut(text))#使用jieba分词得到词语字符串
#这里原本使用的是jieba分词,但是后面觉得分词之后展现的数据反而没有那么直观 46 cut_text = ' '.join(text.split(',')) #改用了将每一句话展现到词云里面 47 try: #背景图片选择,这里最后因为序号错误需要加一个异常处理,选择第00张图片 48 background = imageio.imread(imagePath) 49 except FileNotFoundError: 50 background = imageio.imread('E:\pricechen\data\background\00.jpg') 51 #设置词云参数 52 cloud = WordCloud(font_path = 53 Savepath+'WenYue-FangTangTi-NC-2.otf', 54 background_color = 'white',mask = background, 55 max_words=2000,max_font_size = 40, 56 scale=10, #清晰度,这里考虑电脑配置,只选择15 57 ) 58 word_cloud = cloud.generate(cut_text) 59 #保存,使用原图保存方式 60 word_cloud.to_file(Savepath+'2018\Chinese'+month[i]+'.jpg') 61
#这边就是自动化处理了 62 if __name__=='__main__': 63 fileHandle(Savepath,filename,month) 64 WCHandle(Savepath,month)
以上就是所有代码了,一共六十行左右代码,就能处理近六万条数据。
十二个月的数据,每个月都处理为一张词云图,每张词云图都用了一个省的地图作为模板。
来看看处理后的结果,我就直接上图了,因为图片比较大(保存的清晰度较高),这里就只放两张图。


需要2018年互联网大事件数据的可以私信我,代码有错误的话欢迎指正哦。