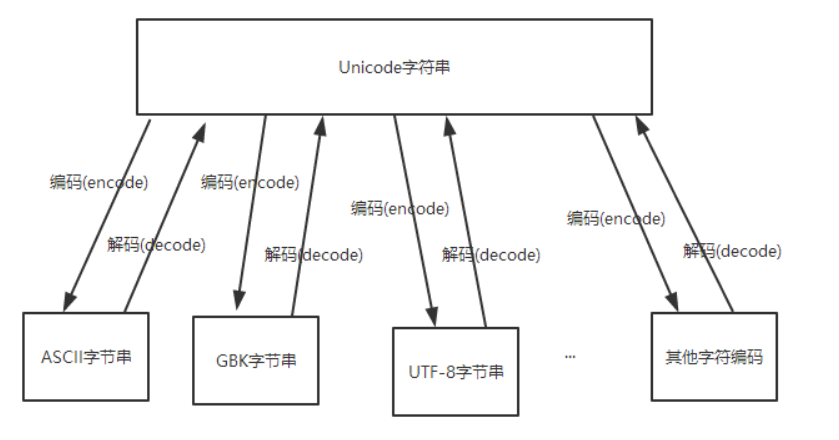
一、摆个图
 DJ DJ DJ Decode、 J 解码
DJ DJ DJ Decode、 J 解码
首先得知道字符串有哪些编码格式,至于为什么会有这么多的编码格式,以后再了解更新。
1、ASCII 占1个字节,只支持英文
2、GB2312 占2个字节,支持6700+汉字
3、GBK GB2312的升级版,支持21000+汉字,中文2个字节。
4、Unicode 2-4字节 已经收录136690个字符
5、UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。
英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个。中文3个字节。
6、UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
在 python2 和 python3 默认的编码格式是不一样的。Python2默认是ASCII编码,python3 是unicode编码。所以在用python2 时候会 绕一下。
一般在用 python2 时候会先在开头加上
#coding=utf-8
Python2中默认是ASCII码,一般会加入以utf-8编程。那么这个时候所有用到的 字符串 都是 utf-8 的编码格式,中文也不例外。
#coding=utf-8 #Python2中默认是ASCII码,一般会加入以utf-8编程 a = '编码' # a是utf-8类型 b = a.decode('utf-8') # b是Unicode类型 c = b.encode('gbk') #c是gbk类型 d = c.decode('gbk').encode('utf-8') #先将c转换成Unicode,再转成utf-8 print a ,b,c,d print type(a),type(b),type(c),type(d)

python3 默认是Unicode 编码格式
a = '编码' # a是unicode类型 b = a.encode('utf-8') # b是utf-8类型 c = a.encode('gbk') #c是gbk类型 print (a ,b,c) print (type(a),type(b),type(c)) #python3默认是unicode类型

encode 出来的 永远是 字节串。
二、encode、decode
字符串的编码解码第一次接触是在 socket编程,socket 套接字传输的必须是字节串,其实Bytes才是计算机里真正的数据类型,也是网络数据传输中唯一的数据格式,什么Json,Xml这些格式的字符串最后想传输也都得转成Bytes的数据类型才能通过socket进行传输,而Bytes的数据与字符串类型数据的转换就是编码与解码的转换,utf-8是编解码时指定的格式。所以在 发送数据时候做了一步 字符串编码 str.encode('utf-8') ,编码格式选的 utf-8,这样就把字符串变成了字节串。【在python3 时候的操作】
在 接收端,接收到的数据需要转码,rev.decode('utf-8') ,编解码的格式可以自己选择。
这里存在一个数据传输隐患。当传输的数据超过一次性最大接收量,或者多次传输,那数据流被分割为多个部分,那么我们就不知道某个字符是否由于位于分割边界而从中间被分开。此时对部分接受的信息进行解码是很危险的。比如中文,在编码后是多字节的形式。编码方式主要分为两大类,单字节编码和多字节编码,前者即每个字符与字节的值唯一对应,后者中每个字符可能会用多个字节来表示。由于在一些多字节编码方式中,用于表示不同字符的字节数是不同的,因此操作起来要多加小心。
三、序列化、反序列化 json
不同的编程语言有一个共同的数据类型---字符串类型。
所以要实现不同的编程语言之间对象的传递,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
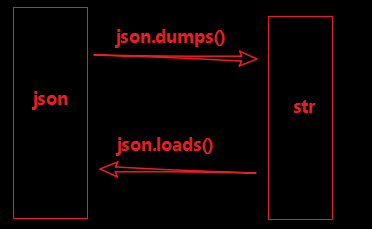
在python中,序列化可以理解为:把python的对象编码转换为json格式的字符串,反序列化可以理解为:把json格式字符串解码为python数据对象。在python的标准库中,专门提供了json库与pickle库来处理这部分。
json的dumps方法和loads方法,可实现数据的序列化和反序列化。具体来说,dumps方法,可将json格式数据序列为Python的相关的数据类型;loads方法则是相反,把python数据类型转换为json相应的数据类型格式要求。在序列化时,中文汉字总是被转换为unicode码,在dumps函数中添加参数ensure_ascii=False即可解决。
import json print (json.__all__) #查看json库的所有方法 ['dump', 'dumps', 'load', 'loads', 'JSONDecoder', 'JSONEncoder']
=========================================== dumps 序列化
未在dumps函数中添加参数ensure_ascii=False,结果如下: #coding: utf-8 import json dict = {'name':'zhangsan', 'age':33, 'address':'红星路'} print('未序列化前的数据类型为:', type(dict)) print('为序列化前的数据:', dict) #对dict进行序列化的处理 dict_xu = json.dumps(dict) #直接进行序列化 print('序列化后的数据类型为:', type(dict_xu)) print('序列化后的数据为:', dict_xu)
结果: 未序列化前的数据类型为: <class 'dict'> 为序列化前的数据: {'name': 'zhangsan', 'address': '红星路', 'age': 33} 序列化后的数据类型为: <class 'str'> 序列化后的数据为: {"name": "zhangsan", "address": "u7ea2u661fu8def", "age": 33} 在dumps函数中添加参数ensure_ascii=False,结果如下: #coding: utf-8 import json dict = {'name':'zhangsan', 'age':33, 'address':'红星路'} print('未序列化前的数据类型为:', type(dict)) print('为序列化前的数据:', dict) #对dict进行序列化的处理 dict_xu = json.dumps(dict,ensure_ascii=False) #添加ensure_ascii=False进行序列化 print('序列化后的数据类型为:', type(dict_xu)) print('序列化后的数据为:', dict_xu)
结果: 未序列化前的数据类型为: <class 'dict'> 为序列化前的数据: {'address': '红星路', 'age': 33, 'name': 'zhangsan'} 序列化后的数据类型为: <class 'str'> 序列化后的数据为: {"address": "红星路", "age": 33, "name": "zhangsan"} ==================================================== loads 反序列化 #coding: utf-8 import json dict = {'name':'zhangsan', 'age':33, 'address':'红星路'} print('未序列化前的数据类型为:', type(dict)) print('为序列化前的数据:', dict) #对dict进行序列化的处理 dict_xu = json.dumps(dict,ensure_ascii=False) #添加ensure_ascii=False进行序列化 print('序列化后的数据类型为:', type(dict_xu)) print('序列化后的数据为:', dict_xu) #对dict_xu进行反序列化处理 dict_fan = json.loads(dict_xu) print('反序列化后的数据类型为:', type(dict_fan)) print('反序列化后的数据为: ', dict_fan)
结果: 未序列化前的数据类型为: <class 'dict'> 为序列化前的数据: {'name': 'zhangsan', 'age': 33, 'address': '红星路'} 序列化后的数据类型为: <class 'str'> 序列化后的数据为: {"name": "zhangsan", "age": 33, "address": "红星路"} 反序列化后的数据类型为: <class 'dict'> 反序列化后的数据为: {'name': 'zhangsan', 'age': 33, 'address': '红星路'}
在 实际运用中,序列化或者反序列化的可能是一个文件的形式,不可能像如上写的那样简单的,下来就来实现这部分,把文件内容进行序列化和反序列化,
序列化, 两步操作:1、先序列化 列表对象 ;2、步把序列化成的字符串写入文件: 反序列化,两步操作:1、先读取文件的字符串对象;2、然后反序列化成列表对象: #coding: utf-8 import json list = ['Apple','Huawei','selenium','java','python'] #把list先序列化,写入到一个文件中 # 两步操作 1步先序列化 列表对象 2步把序列化成的字符串写入文件 json.dump(list, open('e:/test.txt','w')) r1=open('e:/test.txt','r') print(r1.read()) #------------------------------------------------------------ #两步操作:1、先读取文件的字符串对象;2、然后反序列化成列表对象 res=json.load(open('e:/test.txt','r')) print (res) print('数据类型:',type(res)) 结果: ["Apple", "Huawei", "selenium", "java", "python"] ['Apple', 'Huawei', 'selenium', 'java', 'python'] 数据类型: <class 'list'>
四、https://www.cnblogs.com/xyn123/p/8869754.html 参考