结对编程作业
Part1 作业链接及分工
[1.1] 作业链接
博客链接
队友博客链接
Github作业链接
原型设计为陈探宇设计
原型实现为廖善怡实现
Github作业链接统一上传到GitHub作业链接
[1.2] 分工
| 成员 | 原型设计 | 原型实现 | 算法设计实现 | 接口与测试 | Github与博客 |
|---|---|---|---|---|---|
| 廖善怡 | 界面、功能模块设计 | PYQT5实现原型 | A*算法、广搜算法与查表、算法整合 | 接口代码测试与检查算法 | |
| 陈探宇 | 界面设计、UI美观 | 图片转化、图片切割与识别、算法整合 | 接口代码测试与检查算法 | 博客总结 |
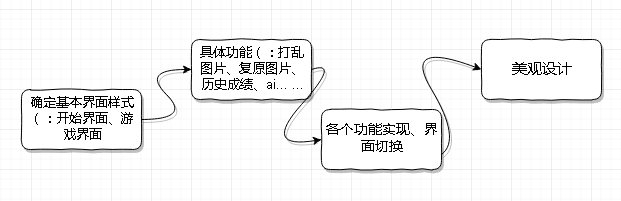
Part2 原型设计
[2.1] 设计说明
设计流程图:
图片华容道主页:
图片华容道开始界面:游戏开始界面有三个功能块,排行榜、进入游戏界面和退出

图片华容道排行榜:
图片华容道排行榜:可以查看历史步数最少的前五名

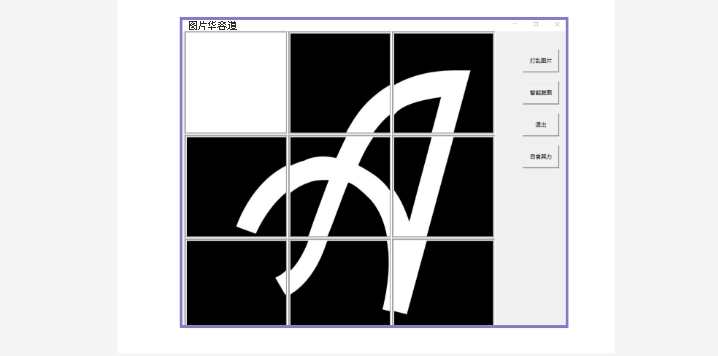
图片华容道功能页:
图片华容道游戏界面:游戏界面有四个功能,打乱图片、自己游戏、ai复原图片与退出;打乱图片可以生成随机乱序图片;ai复原图可以将乱序图片走回正常序列;
自己游戏可以打开可以手动wasd的游戏界面;退出则返回主界面
图片华容道ai复原:

图片华容道自主游戏:

[2.2] 原型模型设计工具
原型模型设计工具:墨刀
[2.3] 结对过程及结对照片
在题目一布置下来的时候,我刚刚好和廖廖哥坐在一起,我们不约而同地想到了八数码问题:这不正是图片华容道的本质问题吗?
我们一拍即合,当天就开始讨论起来要用什么算法来实现ai和解法。


[2.4] 遇到的困难及解决方法
困难描述:在原型设计上遇到的困难一开始是工具的使用,还有功能模块的设计以及实现的可能性、最后是界面的美化设计
解决尝试:在不断查找网站翻阅资料和博客中逐渐掌握原型的设计,并且讨论出确定的功能
是否解决:已解决
有何收获:在浸入式CSDN学习中,收获了原型模型设计工具的用法以及大致掌握如何设计原型
Part3 AI与原型设计实现
[3.1] 代码实现思路

[3.1.1] 网络接口的使用
1、接口部分主要是用python调用post请求外部接口,在data_json里存放队伍的id和token
2、先导入json模块,再用dumps方法转化为json格式,获取赛题信息返回到ret里
3、最后处理ret里信息,再经过图片华容道算法部分,最后上传图片
import json
import requests
def api_post(api_url, data_json):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36','Content-Type': 'application/json'}
ret = requests.post(url, headers=headers, data=data_json)
return ret.text
api_url = 'http://47.102.118.1:8089/api/challenge/start/'+str(uuid) #获取赛题信息的url
uuid = ""# 题目的uuid
data1 = {"teamid":33,"token":"e1b59e3f-5a66-4419-afea-80bfe7953a62"}
data_json = json.dumps(data1)
ret = json.loads(api_post(api_url, data_json)) # 获取赛题信息,ret为post后的返回值转化的字典
data = ret["data"] # 获取该题data
img_base64 = data["img"] # 获取图片64编码
step = data["step"] # 获取调换的步数
swap = data["swap"] # 获取调换的列表值
print(swap)
uuid2 = ret["uuid"] # 获取题目的返回uuid值
img = base64.b64decode(img_base64) # 将64位编码转化为图片并保存在zzzz.jpg
with open("zzzz.jpg", "wb") as fp:
fp.write(img)
fp.close()
print(data)
step = data["step"]
print(step)
chanceleft=ret["chanceleft"]
print('chanceleft:',chanceleft)
post_datas = {"uuid": uuid2,"teamid": 33, "token": "e1b59e3f-5a66-4419-afea-80bfe7953a62", "answer": { "operations": operation,"swap": myswap}}
data_json = json.dumps(post_datas)
ret = json.loads(api_post('http://47.102.118.1:8089/api/challenge/submit', data_json))
[3.1.2] 代码组织与内部实现设计(类图)
[3.1.3] 说明算法的关键与关键实现部分流程图
[3.1.4] 贴出你认为重要的/有价值的代码片段,并解释
[3.1.4.1] 判断图片转化矩阵是否有解
def issloved(srcLayout, destLayout):# src初始状态,dest目的状态
# 进行判断srcLayout和destLayout逆序值是否同是奇数或偶数
# 这是判断起始状态是否能够到达目标状态,同奇同偶时才是可达
src=0;dest=0
for i in range(1,9):
fist=0
for j in range(0,i):
if srcLayout[j]>srcLayout[i] and srcLayout[i]!='0':# 0是false,'0'才是数字
fist=fist+1
src=src+fist
for i in range(1,9):
fist=0
for j in range(0,i):
if destLayout[j]>destLayout[i] and destLayout[i]!='0':
fist=fist+1
dest=dest+fist
if (src%2)!=(dest%2):# 一个奇数一个偶数,不可达
flag = 0
else:
flag = 1
return flag
[3.1.4.2] 交换之后有解状态下获取图片wasd操作序列
def solvePuzzle(srcLayout, destLayout):
# 初始化字典
g_dict_layouts = {}
g_dict_layouts[srcLayout] = -1
stack_layouts = []
stack_layouts.append(srcLayout)# 当前状态存入列表
bFound = False
while len(stack_layouts) > 0:
curLayout = stack_layouts.pop(0)#出栈
if curLayout == destLayout:# 判断当前状态是否为目标状态
break
# 寻找0 的位置。
ind_slide = curLayout.index("0")
lst_shifts = g_dict_shifts[ind_slide]#当前可进行交换的位置集合
for nShift in lst_shifts:
newLayout = swap_chr(curLayout, nShift, ind_slide)
if g_dict_layouts.get(newLayout) == None:#判断交换后的状态是否已经查询过
g_dict_layouts[newLayout] = curLayout
stack_layouts.append(newLayout)#存入集合
lst_steps = []
lst_steps.append(curLayout)
while g_dict_layouts[curLayout] != -1:#存入路径
curLayout = g_dict_layouts[curLayout]
lst_steps.append(curLayout)
lst_steps.reverse()
return lst_steps,len(lst_steps)
[3.1.4.3] 交换之后无解状态下获取图片wasd操作序列
def solvePuzzle_depth(srcLayout):#src初始状态,dest目的状态
#改为获取当前步数下的可达状态
#初始化字典
g_dict_layouts[srcLayout] = -1
stack_layouts = []#所有当前状态可达的状态集合
stack_layouts.append(srcLayout)#当前状态存入列表
bFound = False
curLayout = stack_layouts.pop(0) # 出栈改为出队,cur则是当前获取到的状态
# if curLayout == destLayout:#判断当前状态是否为目标状态
# break
# 寻找0 的位置。
ind_slide = curLayout.index("0") # ind_slide就是0的位置
lst_shifts = g_dict_shifts[ind_slide] # 当前可进行交换的位置集合即0可进行交换的位置集合
for nShift in lst_shifts: # 0和可进行交换的所有步骤进行枚举
newLayout = swap_chr(curLayout, nShift, ind_slide) # 0和旁边可以进行交换的位置交换
if g_dict_layouts.get(newLayout) == None: # 判断交换后的状态是否已经查询过,如果没有,则存入
g_dict_layouts[newLayout] = curLayout
stack_layouts.append(newLayout) # 存入集合,stack就是当前状态可达的状态
return stack_layouts
[3.1.4.4] compare函数比较两图是否一致,一致则返回该图字母
def compare(pic1,pic2):
image1 = Image.open(pic1)
image2 = Image.open(pic2)
histogram1 = image1.histogram()
histogram2 = image2.histogram()
differ = math.sqrt(reduce(operator.add, list(map(lambda a,b: (a-b)**2,histogram1, histogram2)))/len(histogram1))
if differ == 0:
s1 = pic2
# 返回图片出自的字母
return s1[a9]
else:
# 若图片不相同则返回0
return 0
# 若图片相同,则返回小图为原字母图片的序列号
[3.1.4.5] 切割图片并识别成可供算法操作列表
# 将所给图片切割为3*3张小图
im = Image.open(r'zzzz.jpg')
img_size = im.size
m = img_size[0] # 读取图片的宽度
n = img_size[1] # 读取图片的高度
w = 300 # 设置你要裁剪的小图的宽度
h = 300 # 设置你要裁剪的小图的高度
x = 0
y = 0
a = 0
for i in range(3): # 裁剪为3*3张小图
for j in range(3):
region = im.crop((300*i, 300*j, 300*i+w, 300*j+h)) # 裁剪区域
region.save("zzz" + str(a) + ".jpg")
a = a+1
list1 = glob.glob(r'F:华容道*.jpg')
list2 = glob.glob(r'F:华容道zzz*.jpg')
lio = []
# 给出乱序图片的序列
for i in range(9):
for j in range(18):
# 在识别出图片的上下18张中匹配出乱序图片的序列
temp = compare1(list2[i],list1[x4+j])
if temp != 0:
if x2 ==list1[x4+j][a9]:
lio.append(temp)
break
# 若没找到与其匹配图片,则为空缺图片序列号
if j == 17 :
lio.append(temp1)
[3.1.4.6] 步数调换前进行广搜
stepnow = 9# 步数
swap =[2,4]# 强制交换
anflag = temp1# 缺了第几个
print('temp:',temp1)
strlio=""
strlio0=""
lio = [str(x) for x in lio]
strlio = strlio.join(lio) # lio列表转化为字符串
lio0 = [str(x) for x in lio0]
strlio0 = strlio0.join(lio0) # lio0列表转化为字符串
srcLayout = strlio# 这是初始序列##############3
print(srcLayout)
destLayout = strlio0# 这是目的序列########3
lst_stack= solvePuzzle_depth(srcLayout)# 获得当前状态的可达状态
# print('-------------------')
lst = lst_stack# 当前状态的所有可达状态的集合
for index in range(stepnow-1):
lsttemp = lst# 暂时存储当前所有可达状态
lst = []
for i in range(len(lsttemp)):
lsttemp1 = lsttemp[i]#遍历得到当前集合中的一个序列
lsttemp2 = solvePuzzle_depth(lsttemp1)#获得当前序列的可达状态
lst+=lsttemp2
# print(lst)#输出step步数后所有可达状态
changelst = []#经过强制交换之后的可达序列
for index in range(len(lst)):
temp = lst[index]#当前index下lst的一个可达序列
s1 = swap[0]-1
s2 = swap[1]-1
btemp = swap_chr(temp,s1,s2)
changelst.append(btemp)#将交换之后的存入changelst集合
[3.1.4.7] 调换图片位置后打表
if(anflag==9):
f2 = open(r'D:answerans9.json', "r")
elif (anflag == 8):
f2 = open(r'D:answerans8.json', "r")
elif (anflag == 7):
f2 = open(r'D:answerans7.json', "r")
elif (anflag == 6):
f2 = open(r'D:answerans6.json', "r")
elif (anflag == 5):
f2 = open(r'D:answerans5.json', "r")
elif (anflag == 4):
f2 = open(r'D:answerans4.json', "r")
elif (anflag == 3):
f2 = open(r'D:answerans3.json', "r")
elif (anflag == 2):
f2 = open(r'D:answerans2.json', "r")
else:
f2 = open(r'D:answerans1.json', "r")
dict2 = json.load(f2) # 访问表
# print(dict2)
dictpanduan = changelst[0]#获取键,随时更新
if issloved(dictpanduan,destLayout)==1:
after = dict2[dictpanduan] # 返回键值
myswap = []
else:
atemp = swap_chr(changelst[0], 1, 3) # 可解交换
after = dict2[atemp]
myswap=[2,4]
panduan = 0 #用于跟踪是哪一个元素,计算之前的步数
for index in range(len(changelst)):
if issloved(changelst[index], destLayout) == 1:
after1 = dict2[changelst[index]] # 返回键值
myswap1 = []
else:
atemp = swap_chr(changelst[index], 1, 3) # 可解交换
after1 = dict2[atemp]
myswap1 = [2, 4]
# print(after1)
if len(after1)<len(after):
after = after1
panduan = index
myswap = myswap1
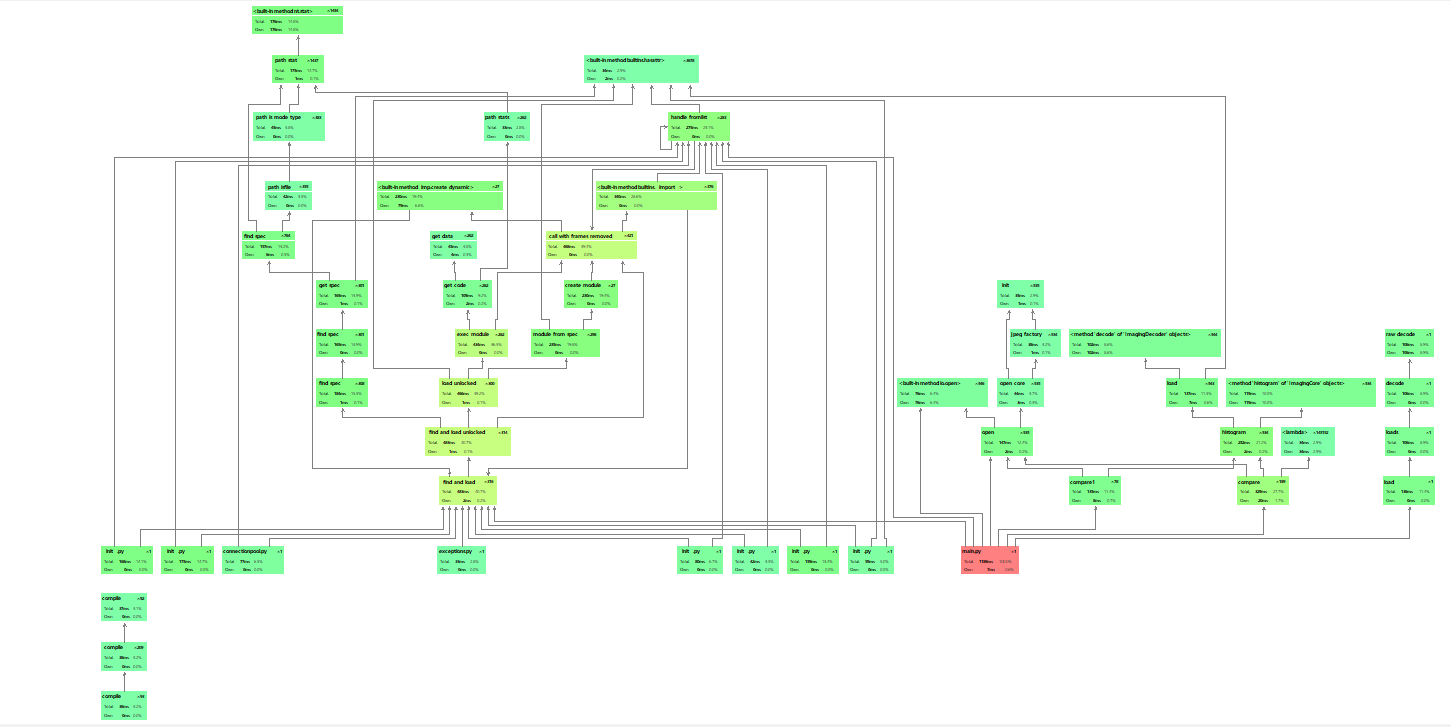
[3.1.5] 性能分析与改进
一开始的A*算法在时间上由于搜索空间少用时少,但是在调换条件下,有可能得到并非最优操作序列解,于是通过广搜和打表得到最优解
[3.1.6] 描述你改进的思路
本来是采用A*算法来解决问题,后来发现在调换步数之前,通过A*算法走的并非最优解
于是在基于时间和搜索空间的考虑上,最后采用了广搜算法搜索调换前的步数,再通过打表的方法直接找到之后的操作序列
[3.1.7] 展示性能分析图和程序中消耗最大的函数


[3.1.8] 展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路
import unittest
import unittest
from main import solvePuzzle_depth
from main import solvePuzzle
from main import issloved
class MyTestCase(unittest.TestCase):
def test_solvePuzzle_depth(self):#solvePuzzle_depth就是对对当前状态的所有可达状态进行测试,如何再返回
zt = '103478259'
solve_test = solvePuzzle_depth(zt)
print('当前状态为:')
print(zt[:3])
print(zt[3:6])
print(zt[6:9])
print('-------------------')
for index in range(len(solve_test)):
solved = solve_test[index]
print('可达状态:',index+1)
print(' ')
print(solved[:3])
print(solved[3:6])
print(solved[6:9])
print('-------------------')
return 0
# def test_solvePuzzle(self):
# sol_test = solvePuzzle()
if __name__ == '__main__':
unittest.main()
单元测试结果:

[3.2] Github的代码签入记录及记录的commit信息
由于写算法和设计UI的过程中都是连续几天肝完的,所以GitHub上的代码签入记录一直断断续续

[3.3] 遇到的代码模块异常或结对困难及解决方法。
问题描述:
在原型的实现上:PYQT5的使用还有各种功能的设计和实现
在算法设计上:搜索算法的选择和搜索算法的算法堆栈溢出,A*算法的启发函数设计,还有调换序列之前的步数如何实现最优解
在图片识别上:如何进行图片识别并输出可用于算法解题的序列以及图片识别中图片的路径怎么输入
在接口处理上:postman的使用以及python中requests的使用
解决尝试:
在原型的实现上:不断在CSDN和Github中找PYQT5的使用方法以及用python中的各种库调用实现功能
在算法设计上:一开始的深搜算法经常堆栈溢出,但是最后换成A*算法之后,性能就好了许多
在图片识别上:九月中旬的时候对识别毫无思路,之后把base64图片编码转化后的大图切割成小图再和所有图片切割成3*3的图片库进行对比
在接口处理上:学会使用了url
是否解决:
在原型的实现上:原型上虽然美观性不足但是问题大致得到解决
在算法设计上:通过不同启发函数,使算法性能得到解决
在图片识别上:通过切割小图识别出图片字母,解决了图片识别问题
在接口处理上:除了循环得到题目并提交未完成,其余已解决
有何收获:
在原型的实现上:收获了PYQT5的使用,以及部分原型模块功能设计
在算法设计上:深入学习启发式算法,学会设计不同的启发函数来减小搜索空间优化搜索性能
在图片识别上:深入了解cv2和image、glob,批量图片识别图片切割以及文件路径处理
在接口处理上:学会使用了url和requests
[3.4]评价你的队友
值得学习的地方:
高度自律,及其努力,常常深夜一两点还在桌前认真地改进算法,不仅包揽了结对作业里的许多任务,还会帮助我完成我的部分
需要改进的地方:
希望他能少做一点,多给队友一点发挥空间
[3.5.1] PSP表格
由于中间开发与测试用了太多时间,只能大概估算出时间
| PSP2 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 180 | 165 |
| Estimate | 估计这个任务需要多少时间 | 30 | 60 |
| Development | 开发 | 3000 | 3200+ |
| Analysis | 需求分析 (包括学习新技术) | 1000 | 1000+ |
| Design Spec | 生成设计文档 | 60 | 121 |
| Design Review | 设计复审 | 60 | 50 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 45 |
| Design | 具体设计 | 120 | 150 |
| Code Review | 代码复审 | 120 | 120 |
| Test | 测试(自我测试,修改代码,提交修改) | 300 | 420+ |
| Reporting | 报告 | 180 | 240 |
| Test Report | 测试报告 | 60 | 60+ |
| Size Measurement | 计算工作量 | 30 | 35 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 50 |
| 合计 | 5200 | 5800+ |
[3.5.2] 学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 5 | 5 | 大致了解原型模型设计,深入学习八数码问题以及搜索算法 |
| 2 | 305 | 305 | 12 | 17 | 熟悉python的cv2、image使用,掌握A*算法 |
| 3 | 221 | 526 | 12 | 29 | 熟悉python的glob用法,学会批量处理图片 |
| 4 | 674 | 1200 | 35+ | 64+ | 对各个模块进行封装组合,并且测试 |
| 5 | 950 | 2150 | 40+ | 100+ | 通过requests和json掌握编写接口代码 |