关于正则表达式的更多用法,可参考链接:https://blog.csdn.net/weixin_40040404/article/details/81027081
一、正则表达式:
1.常用正则匹配:
URL:^https?://[a-zA-Z0-9.?=&]*$ (re.S模式,匹配 https://www.baidu.com 类似URL )
常用Email地址:[0-9a-zA-Z_-]+@[0-9a-zA-Z_-]+.[0-9a-zA-Z_-]+ 或者 [w-]+@[w-]+.[w-]+
中文字符匹配:[u4e00-u9fa5]+ 或者 [^x00-xff]+
QQ号:[1-9][0-9]{4,} ({4,}表示[0-9]的数字个数不低于4个)
ID:^[1-9]d{5}(18|19|([23]d))d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)d{3}[0-9Xx]$
2.特殊组合:
([sS]*?) == ([. ]*?) == re.findall(‘.*?‘, re.S)
万能正则表达式 (加‘?’表示懒惰模式,尽可能最小长度匹配; 不加‘?’表示贪婪模式,尽可能最大长度匹配)
sS : 空白字符+非空白字符,即表示所有字符 all, == ’ .
‘(.表示除换行符之外的任意字符,
表示换行符)
re.S: 即DOTAALL 点匹配任意模式,改变.的行为,可以匹配换行符
二、例子
获取博客园的其中一篇文章的内容,保存至文档中。(具体解析在代码注释中可见)
1.源代码
1 import requests 2 import re 3 import json 4 5 def request_blog(url): 6 # 异常处理代码块 7 try: 8 #同步请求 9 response = requests.get(url) 10 if response.status_code == 200: 11 return response.text 12 except requests.RequestException: 13 return None 14 15 def parse_result(html): 16 # re正则表达式,re.compile是对匹配符的封装,直接用re.match(匹配符,要匹配的原文本)可以达到相同的效果, 17 # 当然,这里没有用re.match来执行匹配,而是用了re.findall,这是因为后者可以适用于多行文本的匹配。 18 # 另外,re.compile后面的第2个参数,re.S是用来应对换行的,.匹配的单个字符不包括 和 ,当遇到换行时,我们需要用到re.S 19 20 # 获取网页中的<p>标签中的内容,遇到换行符时,自动跳出循环 21 # 格式:标签加.*?,.*?表示取标签中的所有数据 22 pattern = re.compile('<p>.*?</p>',re.S) 23 items = re.findall(pattern, html) 24 return items 25 26 def write_item_to_file(item): 27 print('写入数据:' + str(item)) 28 # 保存的文件名blog.txt,写入文件的格式a追加,写入文件的中文格式化UTF-8 29 with open('blog.txt', 'a', encoding='UTF-8') as f: 30 # 遇到换行符时,自动换行 31 f.write(json.dumps(item, ensure_ascii=False) + ' ') 32 33 def main(page): 34 # 网址 35 url = 'https://www.cnblogs.com/chenting123456789/p/11840740.html' + str(page) 36 # 调用获取网页数据的函数 37 html = request_blog(url) 38 # 调用解析已获取的网页数据的函数 39 items = parse_result(html) 40 # 循环写入文件 41 for item in items: 42 write_item_to_file(item) 43 44 if __name__ == "__main__": 45 for i in range(1,5): 46 main(i)
2.运行结果

3.原文文章截图

4.写入文件内容
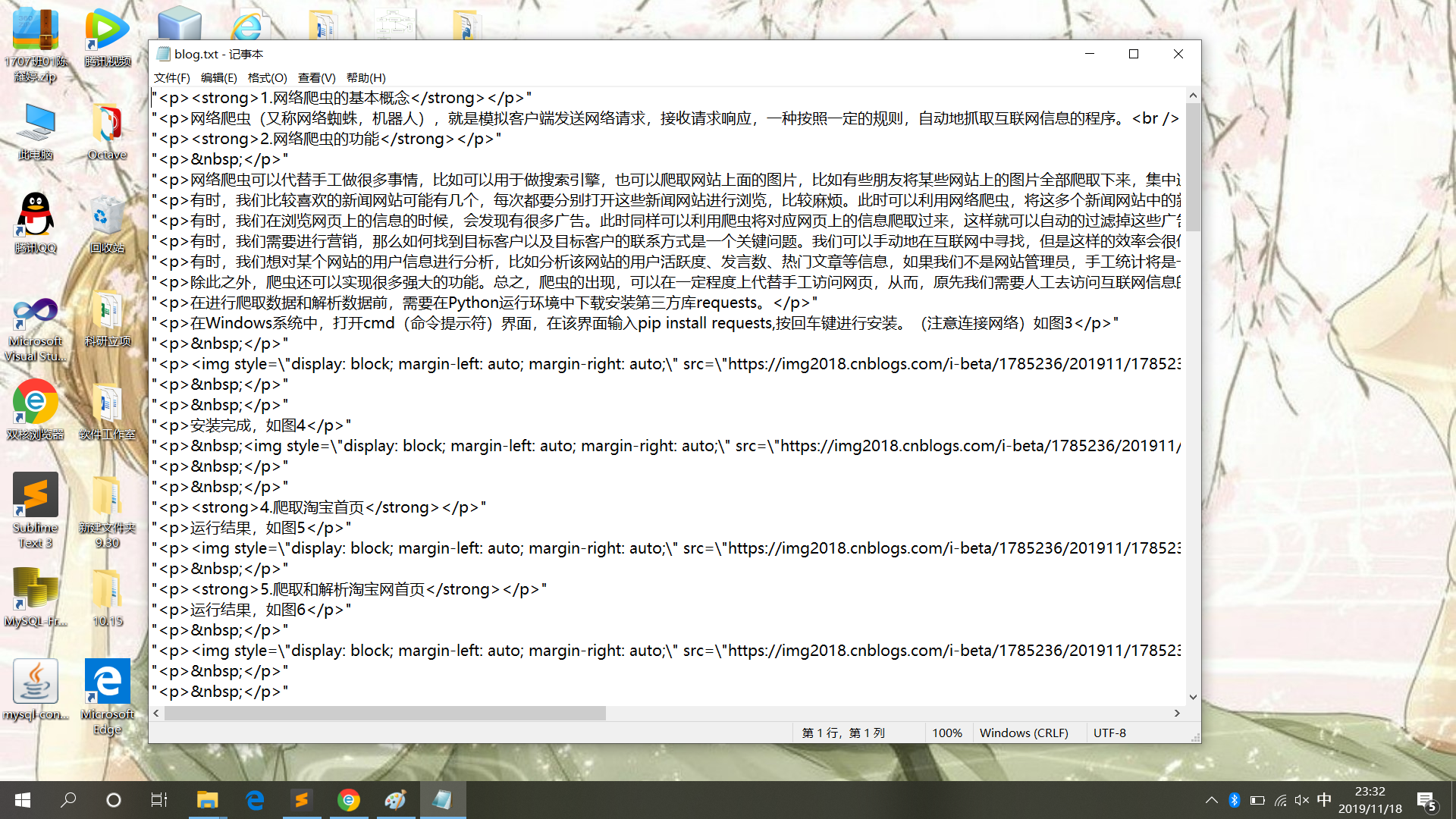
三、小结
强化爬虫爬取网页信息的技术,以及解析数据时的逻辑顺序。