一、redis运行
redis运行时单线程模式运行
原因:
(1)内存处理速度极快,纳秒级别
(2)非阻塞IO,IO多路复用基于事件完成读写
(3)避免线程切换与资源竞争
所以:
一次执行运行一条命令
谨慎使用慢命令:
--keys/flushall/flushdb/exec/save/bgsave/...
二、数据持久化
为防止由于系统宕机导致内存数据丢失,需要定时进行数据持久化,写入到硬盘中。
两种方式:
快照(RDB),保存当前状态
写日志(AOF),操作流水账,需要恢复时将所有操作执行一遍
(1)RDB
原理:创建二进制rdb文件,第二次会进行覆盖,只有一个文件;在启动redis的时候会加载rdb文件
触发RDB的两种方式:
手动保存、自动保存
①手动保存
建议在系统不忙的时候进行
save(会阻塞,一个亿的数据会执行三分钟,因为redis是单线程模式)
bgsave (非阻塞,在后台执行,在后台开启子进程进行保存,还是三分钟)
很明显bgsave方式比较适合线上的维护操作
②配置文件定时自动保存redis.conf

(2) AOF日志追加(AppendOnly File)
原理:保存操作的流水账,在宕机重启时,将AOF日志重新加载执行,对数据盘压力小
① 追加策略

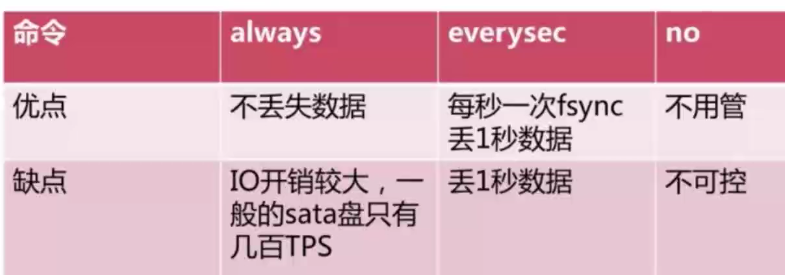
② 重写压缩
就是将对相同key进行设置的日志,只保存最后的结果操作
③AOF实现方式
手动执行AOF保存:
>bgrewriteaof
自动执行AOF保存:
配置redis.conf文件,配置开启AOF,记录日志的策略,重写日志策略

(3)两种持久化方式的选择
