对象引用、可变性和垃圾回收
变量不是盒子
人们经常使用“变量是盒子”这样的比喻,但是这有碍于理解面向对象语言中的引用式变量。Python 变量类似于 Java 中的引用式变量,因此最好把它们理解为附加在对象上的标注。
在示例 8-1 所示的交互式控制台中,无法使用“变量是盒子”做解释。图8-1 说明了在 Python 中为什么不能使用盒子比喻,而便利贴则指出了变量的正确工作方式。
示例 8-1 变量 a 和 b 引用同一个列表,而不是那个列表的副本
>>> a = [1, 2, 3] >>> b = a >>> a.append(4) >>> b [1, 2, 3, 4]
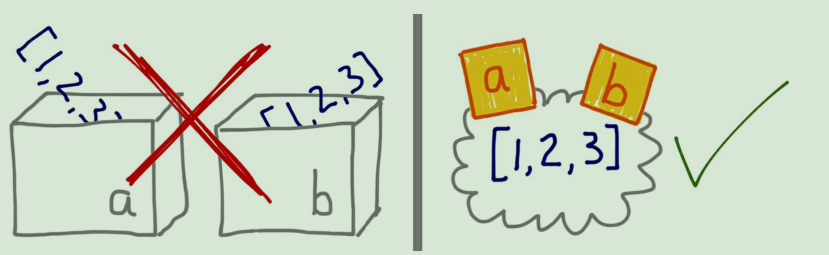
示例 8-2 创建对象之后才会把变量分配给对象
>>> class Gizmo: ... def __init__(self): ... print('Gizmo id: %d' % id(self)) ... >>> x = Gizmo() Gizmo id: 4301489152 ➊ >>> y = Gizmo() * 10 ➋ Gizmo id: 4301489432 ➌ Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unsupported operand type(s) for *: 'Gizmo' and 'int' >>> >>> dir() ➍ ['Gizmo', '__builtins__', '__doc__', '__loader__', '__name__', '__package__', '__spec__', 'x']
❶ 输出的 Gizmo id: ... 是创建 Gizmo 实例的副作用。
❷ 在乘法运算中使用 Gizmo 实例会抛出异常。
❸ 这里表明,在尝试求积之前其实会创建一个新的 Gizmo 实例。
❹ 但是,肯定不会创建变量 y,因为在对赋值语句的右边进行求值时抛出了异常。
为了理解 Python 中的赋值语句,应该始终先读右边。对象在右边创建或获取,在此之后左边的变量才会绑定到对象上,这就像为对象贴上标注。忘掉盒子吧!
标识、相等性和别名
示例 8-3 charles 和 lewis 指代同一个对象
>>> charles = {'name': 'Charles L. Dodgson', 'born': 1832}
>>> lewis = charles ➊
>>> lewis is charles
True
>>> id(charles), id(lewis) ➋
(4300473992, 4300473992)
>>> lewis['balance'] = 950 ➌
>>> charles
{'name': 'Charles L. Dodgson', 'balance': 950, 'born': 1832}
❶ lewis 是 charles 的别名。
❷ is 运算符和 id 函数确认了这一点。
❸ 向 lewis 中添加一个元素相当于向 charles 中添加一个元素。
然而,假如有冒充者(姑且叫他 Alex博士)生于 1832年,声称他是 Charles L. Dodgson。这个冒充者的证件可能一样,但是Pedachenko 博士不是 Dodgson 教授。这种情况如图 8-2 所示。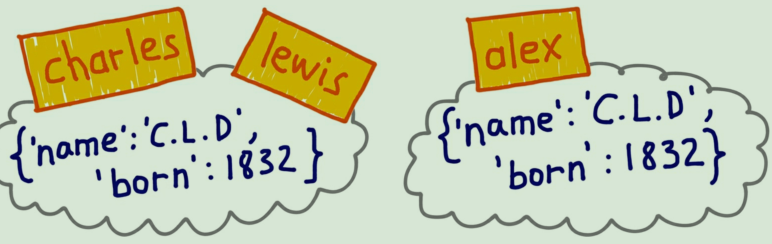
图 8-2:charles 和 lewis 绑定同一个对象,alex 绑定另一个具有相同内容的对象
示例 8-4 alex 与 charles 比较的结果是相等,但 alex 不是charles
>>> alex = {'name': 'Charles L. Dodgson', 'born': 1832, 'balance': 950} ➊
>>> alex == charles ➋
True
>>> alex is not charles ➌
True
❶ alex 指代的对象与赋值给 charles 的对象内容一样。
❷ 比较两个对象,结果相等,这是因为 dict 类的 __eq__ 方法就是这样实现的。
❸ 但它们是不同的对象。这是 Python 说明标识不同的方式:a is notb。
示例 8-3 体现了别名。在那段代码中,lewis 和 charles 是别名,即两个变量绑定同一个对象。而 alex 不是 charles 的别名,因为二者绑定的是不同的对象。alex 和 charles 绑定的对象具有相同的值(== 比
较的就是值),但是它们的标识不同。
在==和is之间选择
== 运算符比较两个对象的值(对象中保存的数据),而 is 比较对象的标识。
通常,我们关注的是值,而不是标识,因此 Python 代码中 == 出现的频率比 is 高。然而,在变量和单例值之间比较时,应该使用 is。目前,最常使用 is检查变量绑定的值是不是 None。下面是推荐的写法:
x is None
否定的正确写法是
x is not None
特殊方法,而是直接比较两个整数 ID。而 a == b 是语法糖,等同于a.__eq__(b)。继承自 object 的 __eq__ 方法比较两个对象的 ID,结果与 is 一样。但是多数内置类型使用更有意义的方式覆盖了 __eq__
方法,会考虑对象属性的值。相等性测试可能涉及大量处理工作,例如,比较大型集合或嵌套层级深的结构时。在结束对标识和相等性的讨论之前,我们来看看著名的不可变类型tuple(元组),它没有你想象的那么一成不变。
元组的相对不可变性
元组与多数 Python 集合(列表、字典、集,等等)一样,保存的是对象的引用。 如果引用的元素是可变的,即便元组本身不可变,元素依然可变。也就是说,元组的不可变性其实是指 tuple 数据结构的物理内容(即保存的引用)不可变,与引用的对象无关。
示例 8-5 一开始,t1 和 t2 相等,但是修改 t1 中的一个可变元素后,二者不相等了
>>> t1 = (1, 2, [30, 40]) ➊ >>> t2 = (1, 2, [30, 40]) ➋ >>> t1 == t2 ➌ True >>> id(t1[-1]) ➍ 4302515784 >>> t1[-1].append(99) ➎ >>> t1 (1, 2, [30, 40, 99]) >>> id(t1[-1]) ➏ 4302515784 >>> t1 == t2 ➐ False
❶ t1 不可变,但是 t1[-1] 可变。
❷ 构建元组 t2,它的元素与 t1 一样。
❸ 虽然 t1 和 t2 是不同的对象,但是二者相等——与预期相符。
❹ 查看 t1[-1] 列表的标识。
❺ 就地修改 t1[-1] 列表。
❻ t1[-1] 的标识没变,只是值变了。
❼ 现在,t1 和 t2 不相等
不要使用可变类型作为参数的默认值
可选参数可以有默认值,这是 Python 函数定义的一个很棒的特性,这样我们的 API 在进化的同时能保证向后兼容。然而,我们应该避免使用可变的对象作为参数的默认值。
class HauntedBus: """备受幽灵乘客折磨的校车""" def __init__(self, passengers=[]): ➊ self.passengers = passengers ➋ def pick(self, name): self.passengers.append(name) ➌ def drop(self, name): self.passengers.remove(name)
❶ 如果没传入 passengers 参数,使用默认绑定的列表对象,一开始是空列表。
❷ 这个赋值语句把 self.passengers 变成 passengers 的别名,而没有传入 passengers 参数时,后者又是默认列表的别名。
❸ 在 self.passengers 上调用 .remove() 和 .append() 方法时,修改的其实是默认列表,它是函数对象的一个属性。HauntedBus 的诡异行为如示例 8-13 所示。
>>> bus1 = HauntedBus(['Alice', 'Bill']) >>> bus1.passengers ['Alice', 'Bill'] >>> bus1.pick('Charlie') >>> bus1.drop('Alice') >>> bus1.passengers ➊ ['Bill', 'Charlie'] >>> bus2 = HauntedBus() ➋ >>> bus2.pick('Carrie') >>> bus2.passengers ['Carrie'] >>> bus3 = HauntedBus() ➌ >>> bus3.passengers ➍ ['Carrie'] >>> bus3.pick('Dave') >>> bus2.passengers ➎ ['Carrie', 'Dave'] >>> bus2.passengers is bus3.passengers ➏ True >>> bus1.passengers ➐ ['Bill', 'Charlie']
❶ 目前没什么问题,bus1 没有出现异常。
❷ 一开始,bus2 是空的,因此把默认的空列表赋值给self.passengers。
❸ bus3 一开始也是空的,因此还是赋值默认的列表。
❹ 但是默认列表不为空!
❺ 登上 bus3 的 Dave 出现在 bus2 中。
❻ 问题是,bus2.passengers 和 bus3.passengers 指代同一个列表。
❼ 但 bus1.passengers 是不同的列表。
问题在于,没有指定初始乘客的 HauntedBus 实例会共享同一个乘客列
表。
这种问题很难发现。如示例 8-13 所示,实例化 HauntedBus 时,如果传入乘客,会按预期运作。但是不为 HauntedBus 指定乘客的话,奇怪的事就发生了,这是因为 self.passengers 变成了 passengers 参数
默认值的别名。出现这个问题的根源是,默认值在定义函数时计算(通常在加载模块时),因此默认值变成了函数对象的属性。因此,如果默认值是可变对象,而且修改了它的值,那么后续的函数调用都会受到影响。
如果定义的函数接收可变参数,应该谨慎考虑调用方是否期望修改传入的参数。例如,如果函数接收一个字典,而且在处理的过程中要修改它,那么这个副作用要不要体现到函数外部?具体情况具体分析。这其实需要函数的编写者和调用方达成共识。
示例 8-14 从 TwilightBus 下车后,乘客消失了
>>> basketball_team = ['Sue', 'Tina', 'Maya', 'Diana', 'Pat'] ➊ >>> bus = TwilightBus(basketball_team) ➋ >>> bus.drop('Tina') ➌ >>> bus.drop('Pat') >>> basketball_team ➍ ['Sue', 'Maya', 'Diana']
❶ basketball_team 中有 5 个学生的名字。
❷ 使用这队学生实例化 TwilightBus。
❸ 一个学生从 bus 下车了,接着又有一个学生下车了。
❹ 下车的学生从篮球队中消失了!
TwilightBus 违反了设计接口的最佳实践,即“最少惊讶原则”。学生从校车中下车后,她的名字就从篮球队的名单中消失了,这确实让人惊讶。
示例 8-15 一个简单的类,说明接受可变参数的风险
class TwilightBus: """让乘客销声匿迹的校车""" def __init__(self, passengers=None): if passengers is None: self.passengers = [] ➊ else: self.passengers = passengers ➋ def pick(self, name): self.passengers.append(name) def drop(self, name): self.passengers.remove(name) ➌
❶ 这里谨慎处理,当 passengers 为 None 时,创建一个新的空列表。
❷ 然而,这个赋值语句把 self.passengers 变成 passengers 的别名,而后者是传给 __init__ 方法的实参(即示例 8-14 中的basketball_team)的别名。
❸ 在 self.passengers 上调用 .remove() 和 .append() 方法其实会修改传给构造方法的那个列表。
这里的问题是,校车为传给构造方法的列表创建了别名。正确的做法是,校车自己维护乘客列表。修正的方法很简单:在 __init__ 中,传入 passengers 参数时,应该把参数值的副本赋值给
self.passengers,像示例 8-8 中那样做(8.3 节)。
def __init__(self, passengers=None): if passengers is None: self.passengers = [] else: self.passengers = list(passengers) ➊
➊ 创建 passengers 列表的副本;如果不是列表,就把它转换成列表。
在内部像这样处理乘客列表,就不会影响初始化校车时传入的参数了。此外,这种处理方式还更灵活:现在,传给 passengers 参数的值可以是元组或任何其他可迭代对象,例如 set 对象,甚至数据库查询结果,因为 list 构造方法接受任何可迭代对象。自己创建并管理列表可以确保支持所需的 .remove() 和 .append() 操作,这样 .pick() 和.drop() 方法才能正常运作。
del和垃圾回收
对象绝不会自行销毁;然而,无法得到对象时,可能会被当作垃圾回收。
del 语句删除名称,而不是对象。del 命令可能会导致对象被当作垃圾回收,但是仅当删除的变量保存的是对象的最后一个引用,或者无法得到对象时。 重新绑定也可能会导致对象的引用数量归零,导致对象被销毁。
有个 __del__ 特殊方法,但是它不会销毁实例,不应该在代码中调用。即将销毁实例时,Python 解释器会调用 __del__ 方法,给实例最后的机会,释放外部资源。
在 CPython 中,垃圾回收使用的主要算法是引用计数。实际上,每个对象都会统计有多少引用指向自己。当引用计数归零时,对象立即就被销毁:CPython 会在对象上调用 __del__ 方法(如果定义了),然后释放分配给对象的内存。
CPython 2.0 增加了分代垃圾回收算法,用于检测引用循环中涉及的对象组——如果一组对象之间全是相互引用,即使再出色的引用方式也会导致组中的对象不可获取。Python 的其他实现有更
复杂的垃圾回收程序,而且不依赖引用计数,这意味着,对象的引用数量为零时可能不会立即调用 __del__ 方法。
为了演示对象生命结束时的情形,示例 8-16 使用 weakref.finalize注册一个回调函数,在销毁对象时调用。
示例 8-16 没有指向对象的引用时,监视对象生命结束时的情形
>>> import weakref >>> s1 = {1, 2, 3} >>> s2 = s1 ➊ >>> def bye(): ➋ ... print('Gone with the wind...') ... >>> ender = weakref.finalize(s1, bye) ➌ >>> ender.alive ➍ True >>> del s1 >>> ender.alive ➎ True >>> s2 = 'spam' ➏ Gone with the wind... >>> ender.alive False
❶ s1 和 s2 是别名,指向同一个集合,{1, 2, 3}。
❷ 这个函数一定不能是要销毁的对象的绑定方法,否则会有一个指向对象的引用。
❸ 在 s1 引用的对象上注册 bye 回调。
❹ 调用 finalize 对象之前,.alive 属性的值为 True。
❺ 如前所述,del 不删除对象,而是删除对象的引用。
❻ 重新绑定最后一个引用 s2,让 {1, 2, 3} 无法获取。对象被销毁了,调用了 bye 回调,ender.alive 的值变成了 False。
示例 8-16 的目的是明确指出 del 不会删除对象,但是执行 del 操作后可能会导致对象不可获取,从而被删除。
弱引用
正是因为有引用,对象才会在内存中存在。当对象的引用数量归零后,垃圾回收程序会把对象销毁。但是,有时需要引用对象,而不让对象存
在的时间超过所需时间。这经常用在缓存中。弱引用不会增加对象的引用数量。引用的目标对象称为所指对象(referent)。因此我们说,弱引用不会妨碍所指对象被当作垃圾回收。
弱引用在缓存应用中很有用,因为我们不想仅因为被缓存引用着而始终保存缓存对象
示例 8-17 是一个控制台会话,Python 控制台会自动把 _ 变量绑定到结果不为 None 的表达式结果上。这对我想演示的行为有影响,不过却凸显了一个实际问题:微观管理内存时,往往会得到意
外的结果,因为不明显的隐式赋值会为对象创建新引用。控制台中的 _ 变量是一例。调用跟踪对象也常导致意料之外的引用。
示例 8-17 弱引用是可调用的对象,返回的是被引用的对象;如果所指对象不存在了,返回 None
>>> import weakref >>> a_set = {0, 1} >>> wref = weakref.ref(a_set) ➊ >>> wref <weakref at 0x100637598; to 'set' at 0x100636748> >>> wref() ➋ {0, 1} >>> a_set = {2, 3, 4} ➌ >>> wref() ➍ {0, 1} >>> wref() is None ➎ False >>> wref() is None ➏ True
❶ 创建弱引用对象 wref,下一行审查它。
❷ 调用 wref() 返回的是被引用的对象,{0, 1}。因为这是控制台会
话,所以 {0, 1} 会绑定给 _ 变量。
❸ a_set 不再指代 {0, 1} 集合,因此集合的引用数量减少了。但是 _
变量仍然指代它。
❹ 调用 wref() 依旧返回 {0, 1}。
❺ 计算这个表达式时,{0, 1} 存在,因此 wref() 不是 None。但是,
随后 _ 绑定到结果值 False。现在 {0, 1} 没有强引用了。
❻ 因为 {0, 1} 对象不存在了,所以 wref() 返回 None。
weakref 模块的文档(http://docs.python.org/3/library/weakref.html)指出,weakref.ref 类其实是低层接口,供高级用途使用,多数程序最好使用 weakref 集合和 finalize。也就是说,应该使用
WeakKeyDictionary、WeakValueDictionary、WeakSet 和finalize(在内部使用弱引用),不要自己动手创建并处理weakref.ref 实例。我们在示例 8-17 中那么做是希望借助实际使用
weakref.ref 来褪去它的神秘色彩。但是实际上,多数时候 Python 程序都使用 weakref 集合.
摘自流畅的python