迅雷下载和excel都能实现了,合并代码
index.py
import openpyxl import urllib.request import time import os import re filePath = "F:/download/" #换成自己的下载目录地址 wb = openpyxl.load_workbook('file/allhref.xlsx') #换成自己的exal目录 sheets = wb.sheetnames # print(sheets, type(sheets)) import dowloadXunlei def getHref(ws): # print(ws['A']) A一竖列 #循环B数列 i = 0 for href in ws['B']: name = (ws['A'][i].value) i = i + 1 if href.value != 'href': getFileType(href.value, name) def getFileType(url, name): if(re.search("jpg",url)): dowloadPic(url, name) elif(re.search("rmvb",url)): dowloadXunlei.download(url, name) elif(re.search("mkv",url)): dowloadXunlei.download(url, name) elif(re.search("mp4",url)): dowloadXunlei.download(url, name) def dowloadPic(url, fileName): response = urllib.request.urlopen(url) data = response.read() t = int(time.time() * 1000) os.mkdir("download/"+fileName) name = filePath +fileName+"/"+ '%d'%t+".jpg" print(name) with open(name, 'wb') as code: code.write(data) print('finish') for sheet in sheets: # 循环表 if(sheet == 'Sheet1'): getHref(wb[sheet]) # wb[sheet]
引入迅雷下载的py
dowloadXunlei.py
import os import time save_path = "C:/迅雷下载的目录" def download(url,name): downloadFile(url) def get_filename(url): return os.path.split(url)[1] def check_start(filename): cache_file = filename+".xltd" return os.path.exists(os.path.join(save_path,cache_file)) def check_end(fiename): return os.path.exists(os.path.join(save_path,fiename)) def downloadFile(downUrl): fileNames = get_filename(downUrl) isFinish = not check_end(fileNames) isExist = not check_start(fileNames) if(isExist): #如果这个任务不存在 print('开始') #迅雷exe的目录地址 os.system(""D:Program\Thunder.exe" -StartType:DesktopIcon %s"%downUrl) else: if(isFinish): print('继续')
python index.py就能实现文本的下载了
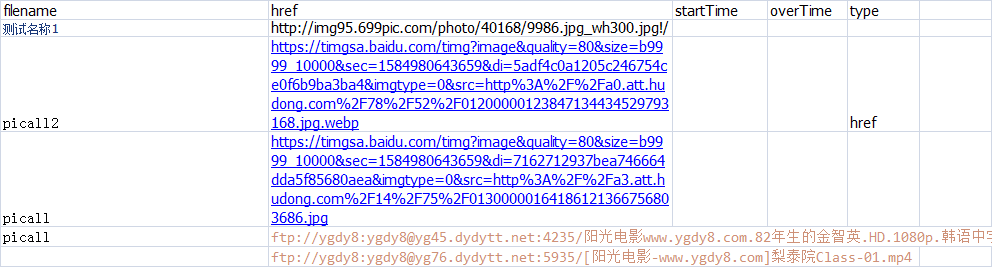
excel目录
还要实现
1.自动获取电影和电视剧的名称,保存到fileName栏,
2.和对text,pdf的下载支持实现
3.获取开始下载时间并且保存到startTime
4.下载结束,监听文件的状态,下载完成记录overTime的时间