输入输出是指应用程序与外部设备及其他计算机进行数据交流的操作,如读写硬盘数据、向显示器输出数据、通过网络读取其他节点的数据等。任何一种编程语言必须拥有输入输出的处理方式,Java语言也不例外。Java语言的输入输出数据是以流的形式出现的,并且Java提供了大量的类来对流进行操作,从而实现了输入输出功能。
所谓流是指同一台计算机或网络中不同计算机之间有序运动着的数据序列,Java把这些不同来源和目标的数据都统一抽象为数据流。数据流可分为输入流和输出流,输入流代表从其他设备流入计算机的数据序列,输出流代表从计算机流向外部设备的数据序列。流序列中的数据可以是没有进行加工的原始数据(二进制字节数据),也可以是经过编码的符合某种格式规定的数据,Java中提供了不同的流类对它们进行处理。流式输入输出的特点是数据的获取和发送沿数据序列的顺序进行,即每一个数据都必须等待排在它前面的数据,等前面的数据读入或送出之后才能被读写。所以流和队列一样,只能以“先进先出”的方式对其中的数据进行读写,而不能随意选择读写的位置。
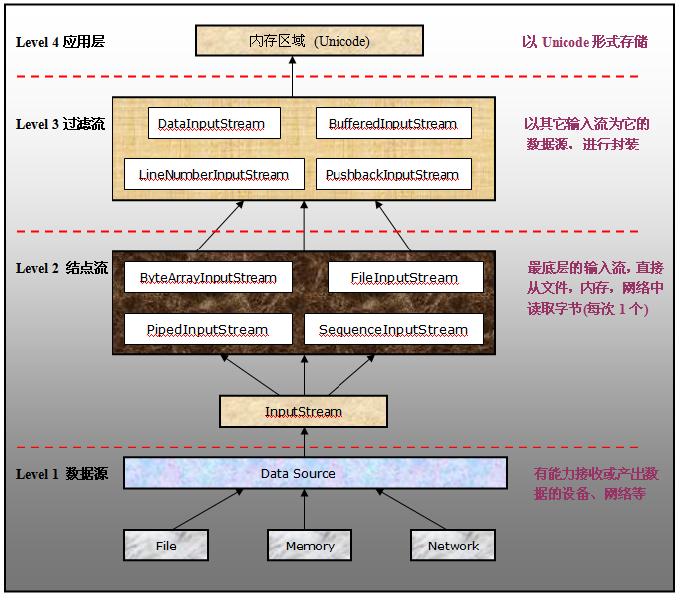
值得注意的地方有:
①Level 2的输入流,大多数都会指明数据源的形式:例如ByteArray,File,Piped
②Level 3的输入流,则不会出现具体的数据源名字,而是以功能取代:例如Buffered,LineNumber
所以说Level 3的输入流是对Level 2输入流的“封装和过滤”。实际上Level 2的输入流,都继承于FilterInputStream的输入流。
下面是对各个input stream的简介:
①ByteArrayInputStream
从内存中每次读取一个字节的数据,然后保存到内置的缓冲区中。维持一个计数器用来记录从数据源中读入的字节数目。
调用该输入流的close()方法不会产生任何实际的作用。因为它“关闭”的对象是---内存。而不是文件。不会抛出任何的IOException。
②FileInputStream
从文件系统中读取原始的字节数据(raw bytes)。每次读取一个字节
③PipedInputStream
管道输入流,通常它的一端会和数据源连接,另一端和管道输出流(PipedOutputStream) 连接。这样从管输入流读入的任何数据将直接地传输到管道输出流。通常会有一个独的线程从管道输入流中读取数据,再交给另外一个线程,由另外的线程向管道输出流中写数据。如果使用单个线程进行读写操作,很容易造成资源的死锁。
④SequenceInputStream
把多个输入流按顺序合并成一个输入流
⑤DataInputStream
从底层的其它字节输入流中读取字节,然后转换成与机器无关的原始类型数据(boolean,byte,char)
⑥BufferedInputStream
为底层的其它字节输入流增加一个“缓冲”的功能,除此之外还可以“标记”,“重置”输入流。当这个输出流的对象被创建时,一个内置的缓冲区也就被创建了。
随着底层的输入流的不断读入,缓冲区中的数据也在不同刷新。一次性地从底层的输入流读入多个字节,方便后续的转码工作
【二】基于字节的输出流
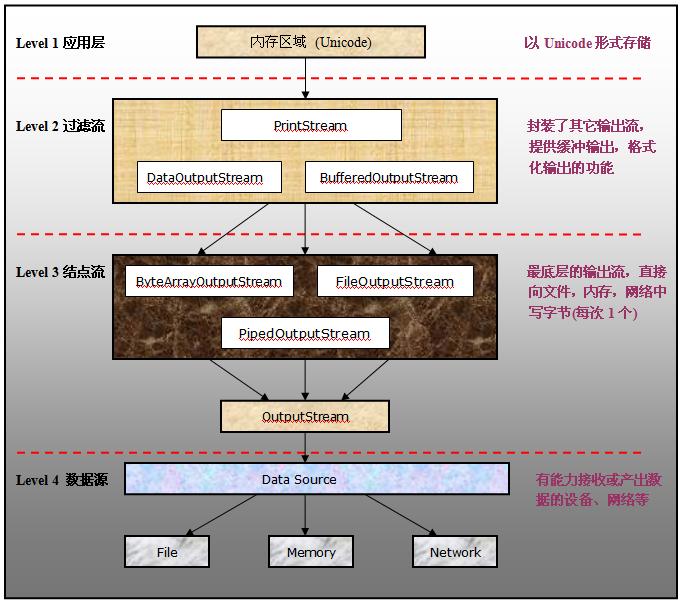
值得注意的是:
①在Level 2的输出流,都是以功能来命名的。例如:Print,DataOutput,Buffered
②在Level 3的输出流,则多数都是以数据源的形式来命名的。例如:ByteArray,File,Piped
所以说Level 2的输出流必须依赖于Level 3的输出流,实际上Level 2的输出流,都继承叫做FilterOutputStream的输出流
下面是对各个output stream的简介:
①PrintStream
为底层的输出流添加额外的功能,令到底层的输出流可以方便地输出各种经过“格式化”的数据。和其它输出流不同,该输出流并不会抛出IOException,但是可以通过checkError方法来检查是否有异常发生。
该输出流具备自动flush功能,但写完一个字节数组,或者碰到一个println方法的调用,或者当要写出的字符是换行符时。会自动清空flush。默认情况下所有要写出的内存字符,都会被该输出流以平台默认编码方式,转换为字节流输出
②DataOutputStream
允许应用程序直接将基本类型数据(boolean, char, byte)直接写出到底层的输出流(内部转换为适当的字节)
③BufferedOutputStream
为底层的输出流提供“缓冲”的功能,所有的写出请求和要写出的数据都会先缓冲到该输出流的缓冲区中,在适当的时机一次性写出。注意该类的write方法被调用时并不一定立即将内存中的数据写出到数据源,而可能先将数据缓存起来。
④ByteArrayOutputStream
该输出流能够将要写入内存的字节,先缓存到自身的缓冲区中。并且该缓冲区的大小可以自动增长。如果要从该输出流中提取字节,可以使用toByteArray,如果要还原为字符串,可以使用toString。关闭该输出流并不会产生任何的IOException,因为它的输出端是---内存而非文件。
⑤FileOutputStream
该输出流以原始字节(raw bytes)的方式向底层文件系统中写数据。在某些系统下,有时候只允许同一个文件
打开一个输出流。所以如果该文件已经被打开了,则再次打开一个输出流会抛出异常。
【三】基于字符的输入流
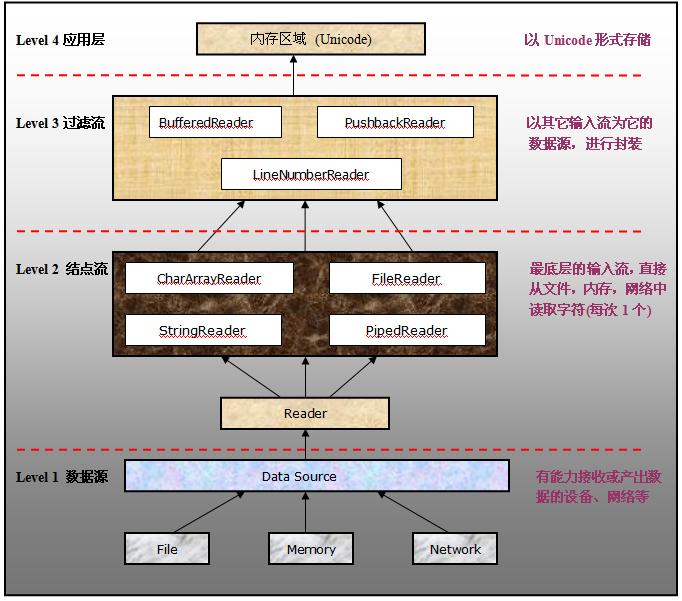
值得注意的地方有:
①Level 2的输入流,大多数都会指明数据源的形式:例如CharArray,String,File
②Level 3的输入流,则不会在出现具体的数据源名字,而是以功能取代:例如Buffered,LineNumber
但是和基于字节的输入流结构不同,FileInputStream是直接继承于InputStream类的。但是FileReader却是继承与InputStreamReader的。而且BufferedReader不是继承于FilterReader。看看下面的结构:
java.io.Reader (implements java.io.Closeable, java.lang.Readable)
java.io.BufferedReader
java.io.LineNumberReader
java.io.CharArrayReader
java.io.FilterReader
java.io.PushbackReader
java.io.InputStreamReader
java.io.FileReader
java.io.PipedReader
java.io.StringReader
这时为什么呢?其实如果我们知道InputStreamReader的作用是什么就知道了:它的作用是充当一座基于字节流和字符流之间转换的桥梁。它将从字节流读取的字节按照编码转换成字符。
实际上任何对文件的IO读写,最终都是以字节的形式进行的。所以读取”字符”只不过是一种逻辑上的说法,那么FileReader为什么继承于InputStreamReader就可以理解了。
下面是对各个Reader的介绍:
①CharArrayReader
直接从内存中以“字符”的形式读取数据。每次读取一个字符,存放到缓存区中。
②FileReader
从文本文件中读取字符的字符输入流,该字符输入流使用系统默认的字符集编码和缓存区大小,不能更改。如果需要重新调整输入流的编码,必须使用InputStreamReader。
③StringReader
从一个字符串中读取内容
④BufferedReader
为其它的基于字符的输入流提供缓冲功能以提高效率。通常情况下,对于底层输入流的任何一次read或者readLine请求都将导致直接的磁盘访问,这将导致效率非常地下。当使用缓存的字符输入流时,读取请求将被缓存,在合适的时候一次性读入批量数据,再进行编码转换。以此显著提高效率。这个缓存输入流的缓冲区大小是可以指定的。
⑤LineNumberReader
可以跟踪读入的“行数据”的字符输入流。该输入流内置一个指示器,用于跟踪读入的数据的行数。默认情况下行号从0开始。用户可以通过setLineNumber和getLineNumber来设置/或者行号。一个行可以由“换行符”,“回车符”,“回车换行符”标识。当遇到其中任意一个符号时,指示器的值将增加1。
注意的是:setLineNumber方法并不会真正地改变数据在文件中的物理位置,而是简单地修改了指示器的数值而已。
【四】基于字符的输出流
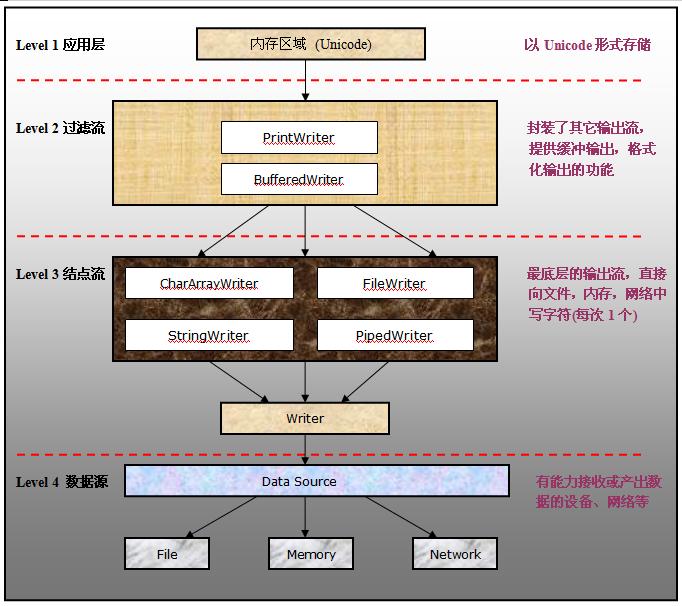
值得注意的是:
①在Level 2的输出流,都是以功能来命名的。例如:Print,Buffered
②在Level 3的输出流,则多数都是以数据源的形式来命名的。例如:CharArray,File,String
所以说Level 2的输出流必须依赖于Level 3的输出流,实际上Level 2的输出流,都继承与一个叫做FilterWriter的输出流
①PrintWriter
将对象数据以恰当的格式输出到文本输出流,和PrintOutputStream类不同,后者当碰到换行符的时候会清空缓冲区。但是PrintWriter不会,它只在print方法被调用时才会清空缓存。所以理论上来说它要比PrintOutputStream更加高效,因为只要缓冲区允许,它可以接纳更多的内容而一次性写入到文件。
这个类使用系统默认的行分割符来代替“换行符"n”,因为不是所有的系统都是通过“"n”来换行的。
②BufferedWriter
为其它字符输出流提供缓冲功能,该输出流的缓冲区大小可以设置,否则将使用默认的缓冲区大小。这个类有一个newLine方法,用于返回一个基于系统的行分割符,而非一定是“"n”。这个类会缓存写请求,当要写出的字符达到一定程度时就一次性地写出到底层的文件输出流。
③CharArrayWriter
类似于ByteArrayOutputStream,向内存中写字符。其中内置一个缓冲区,大小可以动态增长。如果要得到写入的字符可以使用toCharArray方法,如果要构造出字符串则可以使用toString方法。
④FileWriter
以基于字符的方式向文件中写数据。该输出流使用系统平台默认的字符集编码方式和缓存区大小,不能设置改变。如果需要的话可以使用OutputStreamWriter。某些系统只允许同一时刻一个文件被一个输出流打开,所以假如文件已经被另外的输出流打开了,那么新的输出流试图打开同一个文件时将抛出异常。
【五】字节流和字符流之间的转换 ①InputStreamReader:
将字节流--》字符流,默认使用系统编码,可另外指定编码方式。是一个解码过程
new BufferedReader(new InputStreamReader(System.in))
②OutputStreamWriter:
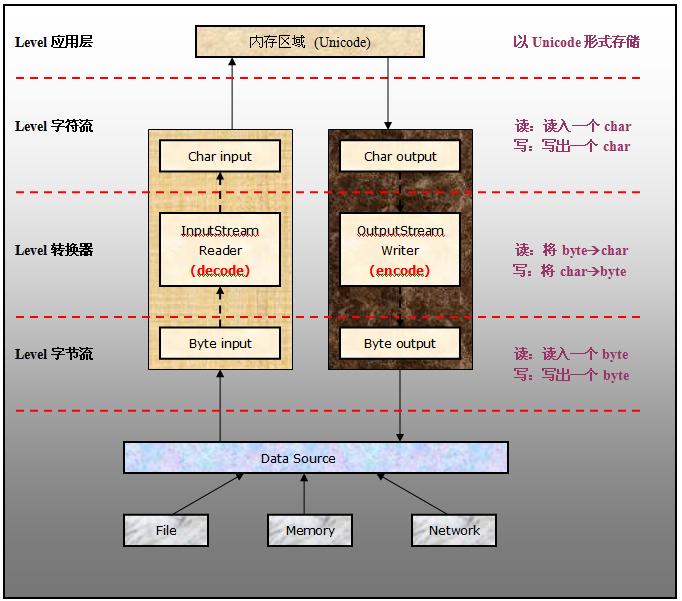
将字符流--》字节流,默认使用系统编码,可另外指定编码方式。是一个编码过程
new PrintWriter(new BufferedWriter(new OutputStreamWriter(System.out));
原文:http://blog.163.com/zhang-_-jie/blog/static/1617843782010510111826484/