<properties> <solr.version>3.6.0</solr.version> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <!-- SLF4J --> <dependency> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-jdk14</artifactId> <version>1.6.1</version> </dependency> <dependency> <groupId>org.apache.geronimo.specs</groupId> <artifactId>geronimo-stax-api_1.0_spec</artifactId> <version>1.0.1</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-core</artifactId> <version>${solr.version}</version> </dependency> <dependency> <groupId>com.***.search</groupId> <artifactId>IKAnalyzer</artifactId> <version>2012-u6</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-dataimporthandler</artifactId> <version>${solr.version}</version> </dependency> <dependency> <groupId>org.apache.solr</groupId> <artifactId>solr-dataimporthandler-extras</artifactId> <version>${solr.version}</version> </dependency> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc14</artifactId> <version>10.2.0.4.0</version> </dependency> </dependencies>
上面的IKAnalyzer为IK分词器,需要我们手动添加到maven的本地仓库中
然后我们需要解压我们上面下载的${solr-3.6.0}/dist/solr-3.6.0.war文件,将解压的文件复制到我们的web project的WebRoot目录里面
将${solr-3.6.0}/example/resources目录中的log4j.properties文件复制到我们的web project的src目录下
同时IK分词器需要复制相关配置文件到web project的src目录
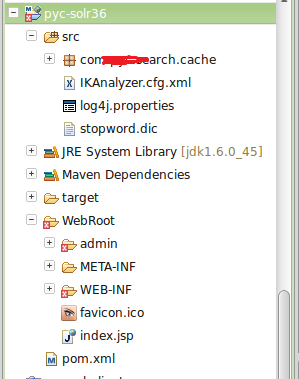
最后得到的项目结构如下:
下面配置solr.home目录,将${solr-3.6.0}/example/multicore文件夹复制到我们指定的目录,假设为/home/chenying/solr-home
然后修改web project的web.xml文件,指定solr的solr.home
<env-entry> <env-entry-name>solr/home</env-entry-name> <env-entry-value>/home/chenying/solr-home</env-entry-value> <env-entry-type>java.lang.String</env-entry-type> </env-entry>
为了使solr支持IK中文分词,我们还需要修改${sole.home}目录中相关core的conf目录中的schemal.xml添加支持IK的fieldType和field
<fieldType name="text_ik" class="solr.TextField" > <analyzer type="index"> <tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart ="false"/> </analyzer> <analyzer type="query"> <tokenizer class="org.wltea.analyzer.solr.IKTokenizerFactory" useSmart ="false"/> </analyzer> </fieldType>
<field name="ik_field" type="text_ik" indexed="true" stored="true" multiValued="false"/>
关于solrconfig.xml文件和schemal.xml文件的详细配置,待后文分解
至此配置完毕,可以在servlet容器(如tomcat)中运行该项目
---------------------------------------------------------------------------
本系列solr&lucene3.6.0源码解析系本人原创
转载请注明出处 博客园 刺猬的温驯
本人邮箱: chenying998179#163.com (#改为@)
本文链接http://www.cnblogs.com/chenying99/p/3440758.html