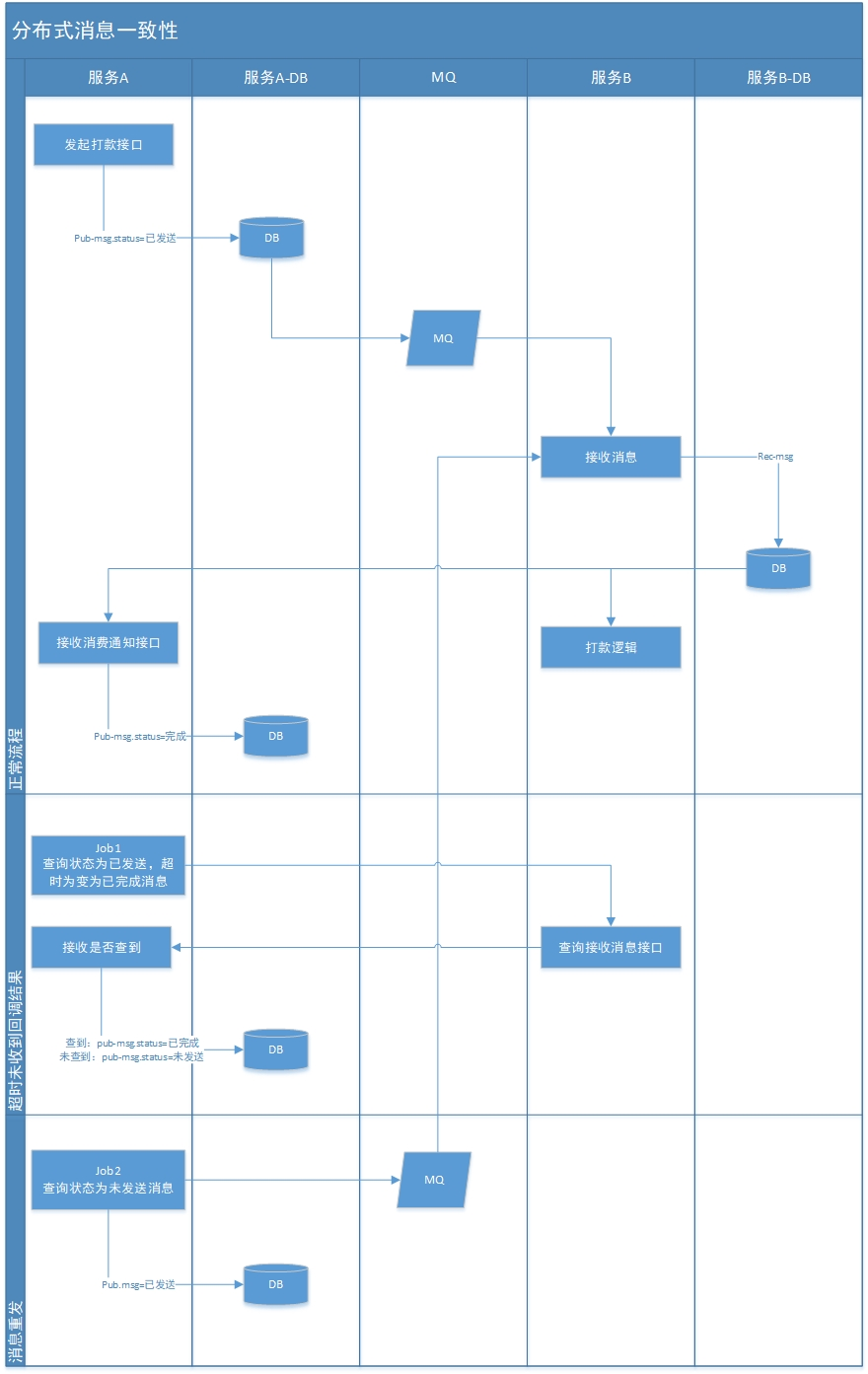
分布式部署服务的情况下,由于网络状况不可预期,消息有可能发送成功,但是消费端消费失败;也有可能消息根本没有发出去,如何保证消息是否发送成功是经常遇到的问题。最近有时间研究了一下,具体方法如下图:
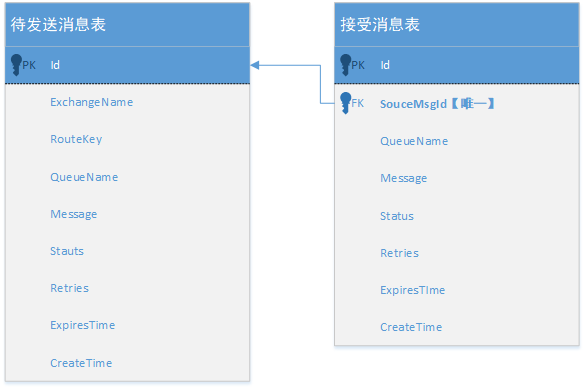
表结构设计如下:
具体思路:
正常流程(网络都正常)
1.消息生产方,将消息信息与业务数据在同一个事务中存入数据库。
2.消息发送发,发送消息,消息发送表‘状态’为‘已发送’
3.消息消费方,接收消息,存入消息接收表,并调用生产方接口,更新生产方消息发送表‘状态’为‘已完成’。
正常流程结束。
异常流程
1.消息生产方,将消息信息与业务数据在同一个事务中存入数据库。
2.消息发送发,发送消息,消息发送表‘状态’为‘已发送’
3.消息消费方未收到消息;或,接收到消息,存入消息接收表,但调用生产方接口失败。
4.消息生产方job1,查询消息发送表‘状态’为‘已发送’,并当前时间超过回调截止时间(或过期时间)的记录,然后调用消息消费方查询状态接口
5.消息生产方job1若查到结果,则更新消息发送表‘状态’为‘已完成’,流程结束;若为查到结果,则更新消息发送表‘状态’为‘未发送’
6.消息生产方job2,查询消息发送表‘状态’为‘未发送’的记录,重新生产消息,并更新状态为“已发送”。之后会自动跳转到流程3,直到状态变更为“已完成”。
注意,消息接收表的sourcemsg_id字段需唯一,保证幂等性。
针对这个设计,完成了net core3.1 的demo,用了rabbitmq作为消息队列,mysql作为数据库,ef core orm,redis分布式锁。