执行应用程序和函数都是在执行功能
rb
f=open('aaa','rb',encoding='utf-8') #b的方式不能指定编码
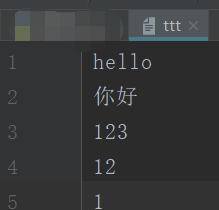
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 f=open('ttt','rb') 4 data=f.read() 5 print(data)
输出
b'hello xe4xbdxa0xe5xa5xbd 123 12 1' #Windows中回车是 这个整体;Linux或Unix平台是
字符串---encode--->bytes
bytes---decode--->字符串
wb
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 f=open('ttt_new','wb') 4 f.write(bytes('111 ',encoding='utf-8')) #字符串要转化为二进制,中间必须经过字符编码
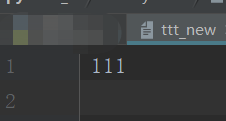
另一种编码方式,
>>>'杨建'.encode('utf-8')
>>>b'xe6x9dxa8xe5xbbxba'
ab
不代表在最后一行追加,而是从最后的位置追加。
二进制这种方式代表处理数据的方式,不代表最后的内容,用二进制的好处:文件中不仅是文本,还包括视频、图片
文件操作的其他方法
closed判断是否关闭
encoding文件编码格式
flush内存中的数据刷到硬盘中
tell光标当前所在位置 read(3)代表读取3个字符,其余的文件内光标移动都是以字节位单位,如seek/tell/read/truncate
f=open('aaa','r',encoding='utf-8',newline='') #读取文件中真正的换行符号Windows系统中是
f=open('aaa','r',encoding='utf-8') #读取文件中python变换后换行符号
seek用来控制光标的移动 f.seek(3,0) 0即从文件开头数三个字节,不写0也行,是默认 f.seek(3,1) 1即相对于上一次光标停留位值,使用相对位置的时候文件操作方式必须带b f.seek(-10,2) 2即从文件末尾倒10个字节
truncate文件截取,从文件的首行首字符开始截断,截断文件为n个字符;无n表示从当前位置起截断;截断之后n后面的所有字符被删除。
循环文件的推荐方式
for i in f: #一条一条读,不符合的从内存中清除,不用一下都读出来,对文件句柄遍历循环
print(i)
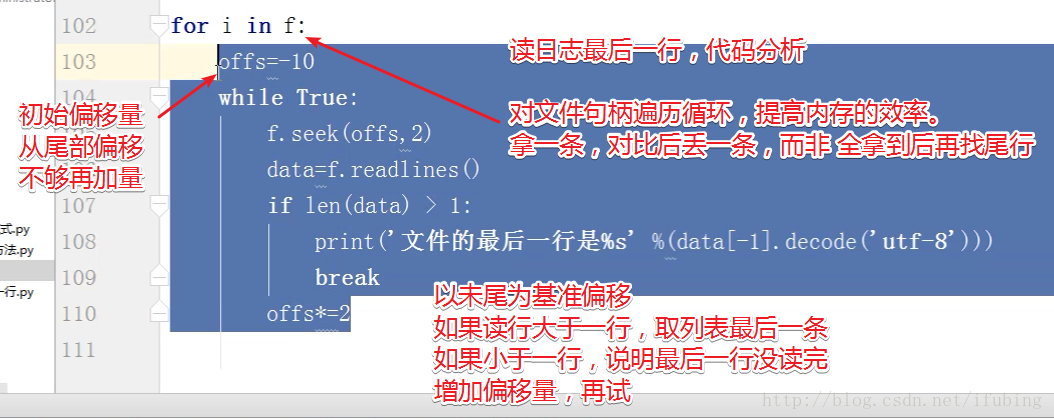
高效率获取文件最后一行的方式
迭代器和生成器
递归:自己调用自己 ; 迭代:每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。
迭代器
迭代器协议:对象必须提供一个next方法,执行该方法要么返回迭代中的下一项,要么引起一个StopIteration异常,以终止迭代(只能往后走不能往前退)
可迭代对象:实现了迭代器协议的对象
协议是一种约定,可迭代对象实现了迭代器协议,python的内部工具(如for循环,sum,min,max函数)使用迭代器协议访问对象
python中强大的for循环机制(跟索引无关,就是基于迭代器协议工作的)字符串、列表、元组、字典、集合、文件对象,这些都不是可迭代对象,只不过在for循环时,调用了它们内部的__iter__方法,把它们变成了可迭代对象。然后for循环调用可迭代对象的__next__方法去取值,而且for循环会捕捉StopIteration异常,以终止迭代。所以对象都可以通过for循环来遍历,while可以通过下标访问对象,但无序对象就无法访问了。
l=[1,2,3]
for i in l: #1. 调用__iter__方法生成可迭代对象i_l=l.__iter__()或者iter(l);2. i_1.__next()__ next()就是在iter_l.__next__()
print(i)
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 l=[1,2,3] 4 iter_l=l.__iter__() 5 print(iter_l.__next__()) 6 print(iter_l.__next__()) 7 print(iter_l.__next__())
输出
1
2
3
简单的赋值方式:
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 t=('123',8) 4 a,b=t print(a,b)
5 #想赋值,必须参数个数对应上否则会报错
6 #如果第3行变成t=('123',8,9)其余不变,会报too many values to unpack
7 #如果第4行变成a,b,c=t其余不变,会报not enough values to unpack
输出
123 8
生成器
可以理解为一种数据类型,它自动实现了迭代器协议,本身就是可迭代对象。
函数中有yield(相当于return,但可以执行多次),执行就得到了个生成器。
两种创建方式1.() ; 2.yield
三元运算
列表生成式
写法比较简单,但占内存太多,列表解析需要生成列表,列表元素过多会卡死。
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 l=['鸡蛋%s'%i for i in range(10)] #列表是内存对象,鸡蛋都放到内存里了。 4 l1=['鸡蛋%s'%i for i in range(10) if i>5] 5 #l1=['鸡蛋%s'%i for i in range(10) if i>5 else i] #没有四元表达式 6 l2=['鸡蛋%s'%i for i in range(10) if i<5] 7 print(l) 8 print(l1) 9 print(l2)
输出
['鸡蛋0', '鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4', '鸡蛋5', '鸡蛋6', '鸡蛋7', '鸡蛋8', '鸡蛋9']
['鸡蛋6', '鸡蛋7', '鸡蛋8', '鸡蛋9']
['鸡蛋0', '鸡蛋1', '鸡蛋2', '鸡蛋3', '鸡蛋4']
生成器表达式
函数只要有yield就是生成器函数。
把列表解析[]换成()得到的就是生成器表达式,它们都是便利的编程方式,只不过,生成器表达式更节省内存,因为生成器表达式是基于迭代器协议的next方法一个个取值的
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 laomuji=('鸡蛋%s'%i for i in range(10)) #生成器 4 print(laomuji) 5 print(laomuji.__next__()) 6 print(next(laomuji)) 7 print(next(laomuji)) 8 print(next(laomuji))
输出
鸡蛋0
鸡蛋1
鸡蛋2
鸡蛋3
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 def foo(): 4 print('ok') 5 yield 1 6 print('ok2') 7 yield 2 8 #其实这里有一个return None 9 g=foo() #生成了一个生成器对象 10 # print(g) #打印generator object at …… 11 # next(g) #打印ok,执行yield 1,然后执行下个next(g) 12 # next(g) #回到yield 1往下执行,打印ok2,执行yield 2,执行return None. 13 for i in g: 14 print(i) #这里的i即yield的值
输出
ok
1
ok2
2
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #斐波那契数列 0 1 1 2 3 5 8 13 21... 4 def fib(max): 5 n,before,after=0,0,1 6 while n<max: 7 print(before) 8 before,after=after,before+after #依据之前的状态做运算 9 #上面这句相当于下面第10行-第12行代码的效果 10 #tmp=before 11 #before=after 12 #after=tmp+after 13 n=n+1
14 fib(5)
输出
0
1
1
2
3
生成器实现斐波那契数列
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 #斐波那契数列 0 1 1 2 3 5 8 13 21... 4 def fib(max): 5 n,before,after=0,0,1 6 while n<max: 7 yield before 8 before,after=after,before+after #依据之前的状态做运算 9 n=n+1 10 a=fib(8) 11 print(next(a)) 12 print(next(a)) 13 print(next(a)) 14 print(next(a)) 15 print(next(a))
输出
0
1
1
2
3
send方法
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 def bar(): 4 print('ok1') 5 count=yield 1 6 print(count) 7 yield 2 8 b=bar() 9 s=b.send(None) #next(b) 第一次send前如果没有next,只能传一个空数据 10 # print(s) # 如果把此行加进去会输出1 11 s1=b.send('eeee') #把'eee'给了yield前面的count,得到yield 2的值 12 print(s1)
输出
ok1
eeee
2
1 #!/usr/bin/env python 2 # -*- coding:utf-8 -*- 3 def bar(): 4 print('ok1') 5 yield 1 6 #print(count) 7 yield 2 8 b=bar() 9 s=b.send(None) #next(b) 第一次send前如果没有next,只能传一个空数据 10 print(s) 11 s1=b.send('eeee') #想把'eee'给了yield前面的参数,可参数没定义,但是没报错 12 print(s1)
输出
ok1
1
2
生成器
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 def run():
4 print('run a while')
5 yield 1
6 print('run a while')
7 yield 2
8 print('run a while')
9 yield 3
10
11 r=run()
12 next(r) #执行next就运行一次,直到遇上yield停住
13 next(r)
输出
run a while
run a while
生成器的好处是延迟计时,一次返回一个结果,不会一次性生成所有结果,对大数据量处理非常有用。另外,生成器还可以有效提高代码可读性。
1 #!/usr/bin/env python
2 # -*- coding:utf-8 -*-
3 def test():
4 for i in range(4):
5 yield i
6 t=test()
7 t1=(i for i in t)
8 t2=(i for i in t1)
9 print(list(t1)) #此时t1生成器的东西都遍历光了,list/sum...都能遍历生成器
10 print(list(t2))
输出
[0, 1, 2, 3]
[]
迭代器运行的三种方式:
next(t)
t.__next__()
t.send('123')