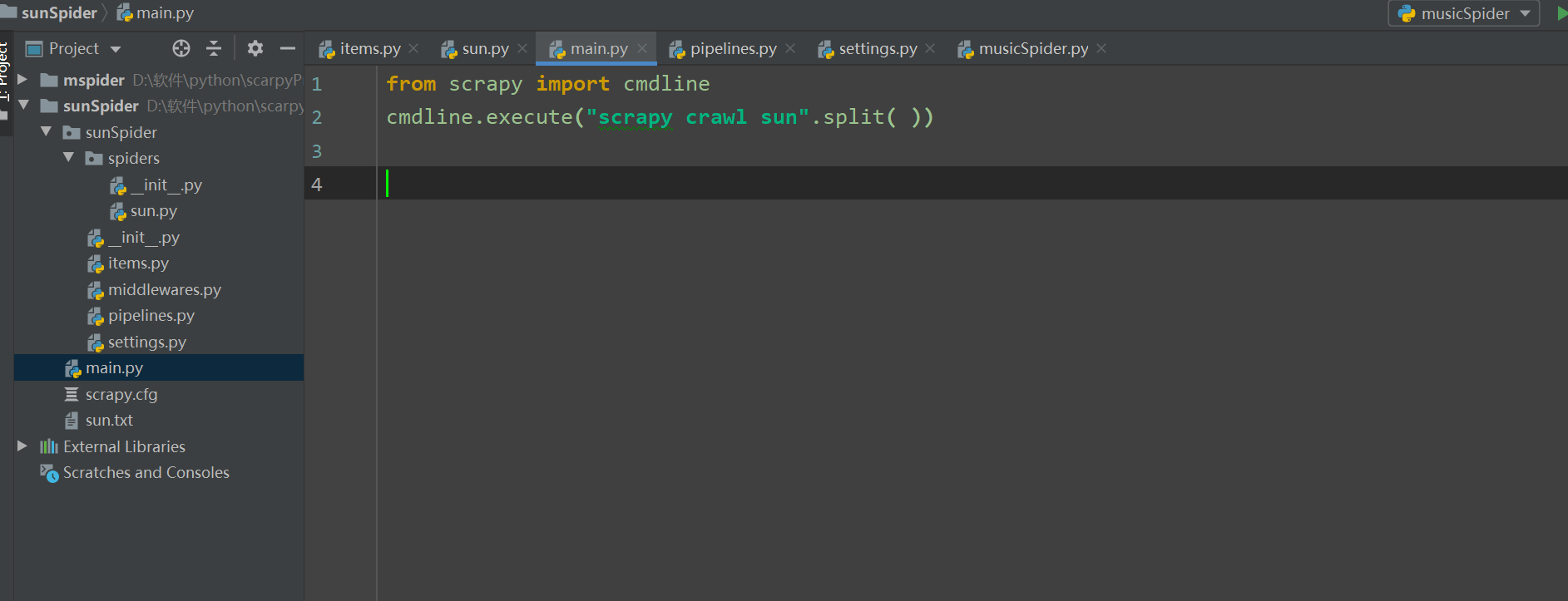
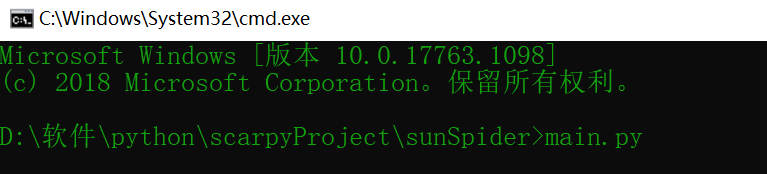
写完之后在main.py所在的路径下执行命令即可:main.py
源代码:
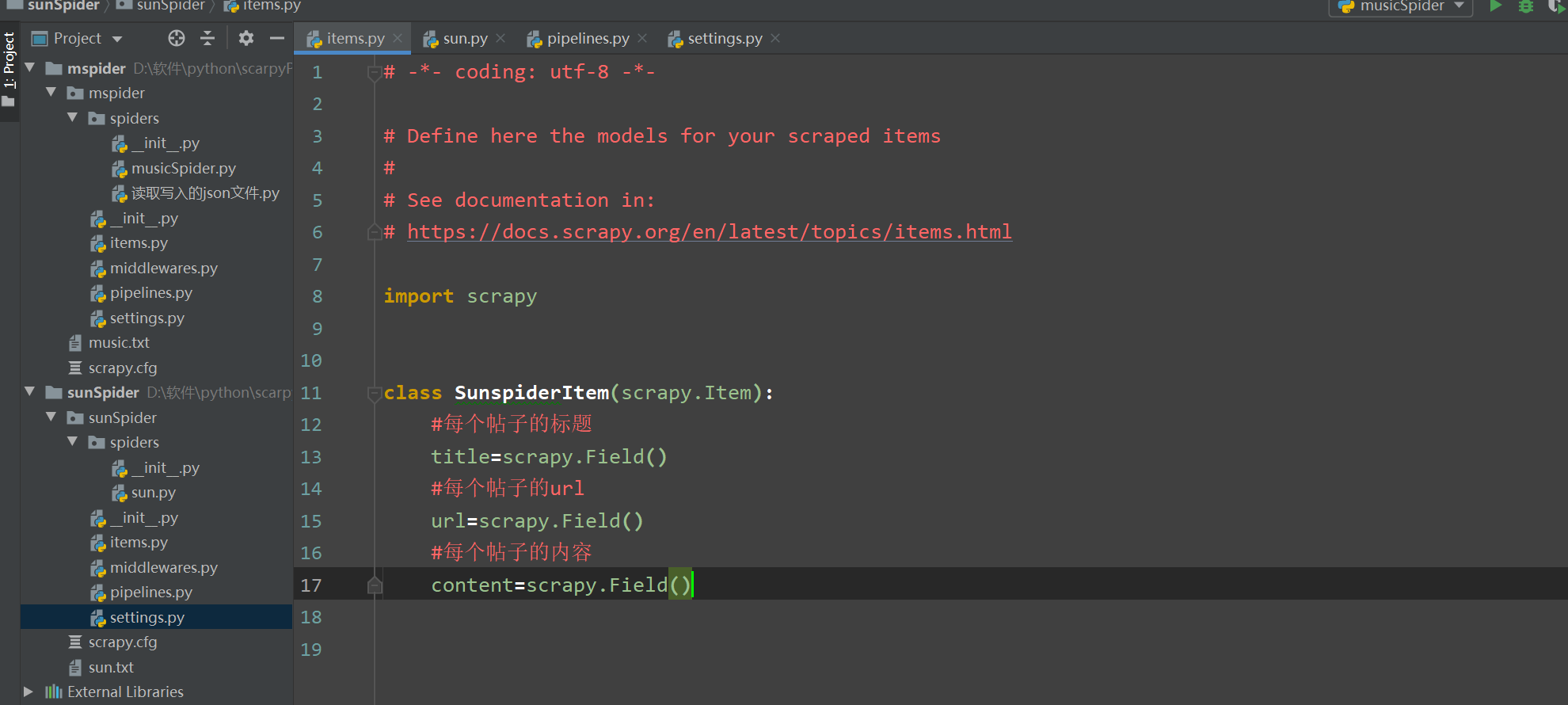
1 items.py 2 3 # -*- coding: utf-8 -*- 4 5 # Define here the models for your scraped items 6 # 7 # See documentation in: 8 # https://docs.scrapy.org/en/latest/topics/items.html 9 10 import scrapy 11 12 13 class SunspiderItem(scrapy.Item): 14 #每个帖子的标题 15 title=scrapy.Field() 16 #每个帖子的url 17 url=scrapy.Field() 18 #每个帖子的内容 19 content=scrapy.Field()
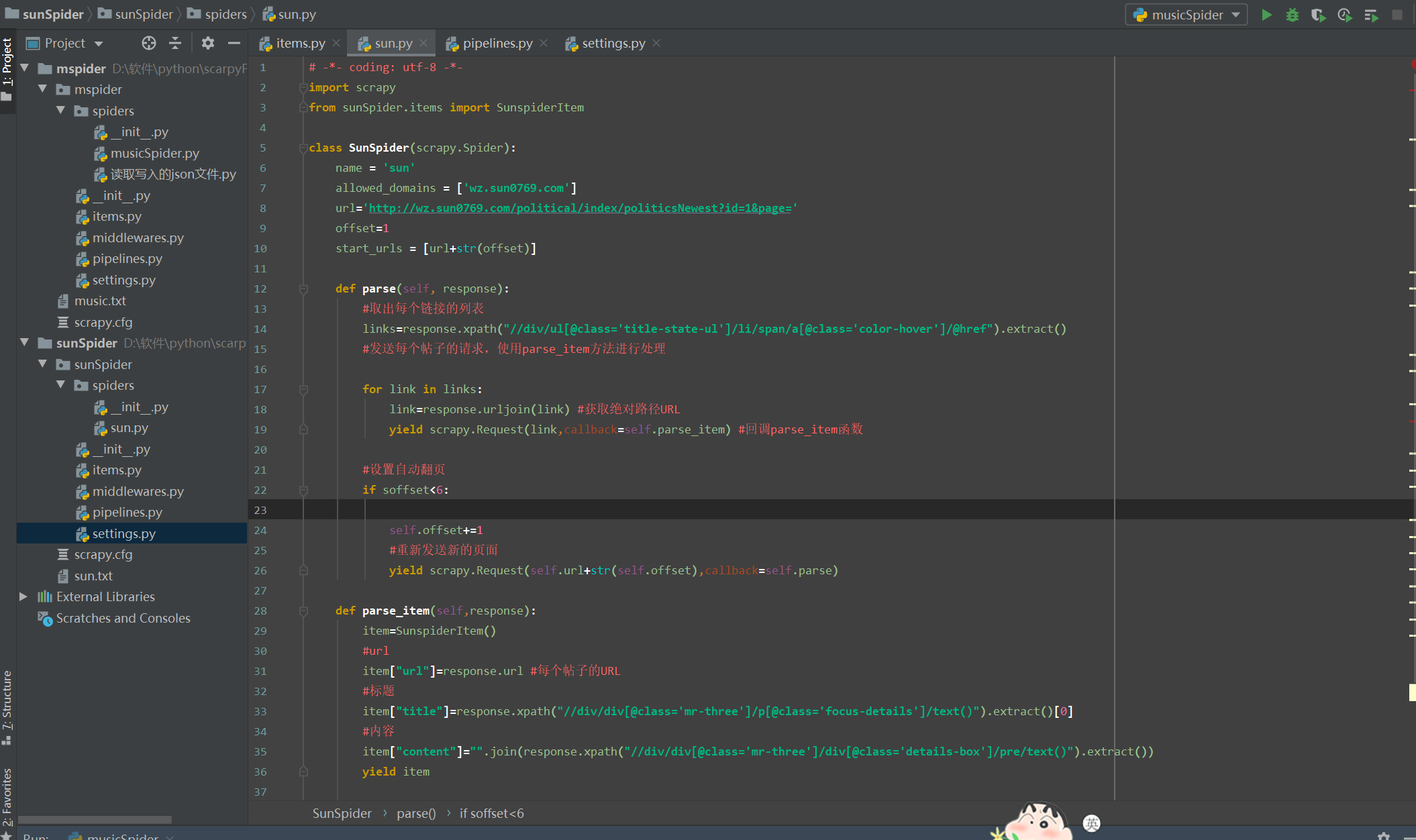
1 sun.py 2 3 # -*- coding: utf-8 -*- 4 import scrapy 5 from sunSpider.items import SunspiderItem 6 7 class SunSpider(scrapy.Spider): 8 name = 'sun' 9 allowed_domains = ['wz.sun0769.com'] 10 url='http://wz.sun0769.com/political/index/politicsNewest?id=1&page=' 11 offset=1 12 start_urls = [url+str(offset)] 13 14 def parse(self, response): 15 #取出每个链接的列表 16 links=response.xpath("//div/ul[@class='title-state-ul']/li/span/a[@class='color-hover']/@href").extract() 17 #发送每个帖子的请求,使用parse_item方法进行处理 18 19 for link in links: 20 link=response.urljoin(link) #获取绝对路径URL 21 yield scrapy.Request(link,callback=self.parse_item) #回调parse_item函数 22 23 #设置自动翻页 24 if soffset<6: 25 26 self.offset+=1 27 #重新发送新的页面 28 yield scrapy.Request(self.url+str(self.offset),callback=self.parse) 29 30 def parse_item(self,response): 31 item=SunspiderItem() 32 #url 33 item["url"]=response.url #每个帖子的URL 34 #标题 35 item["title"]=response.xpath("//div/div[@class='mr-three']/p[@class='focus-details']/text()").extract()[0] 36 #内容 37 item["content"]="".join(response.xpath("//div/div[@class='mr-three']/div[@class='details-box']/pre/text()").extract()) 38 yield item
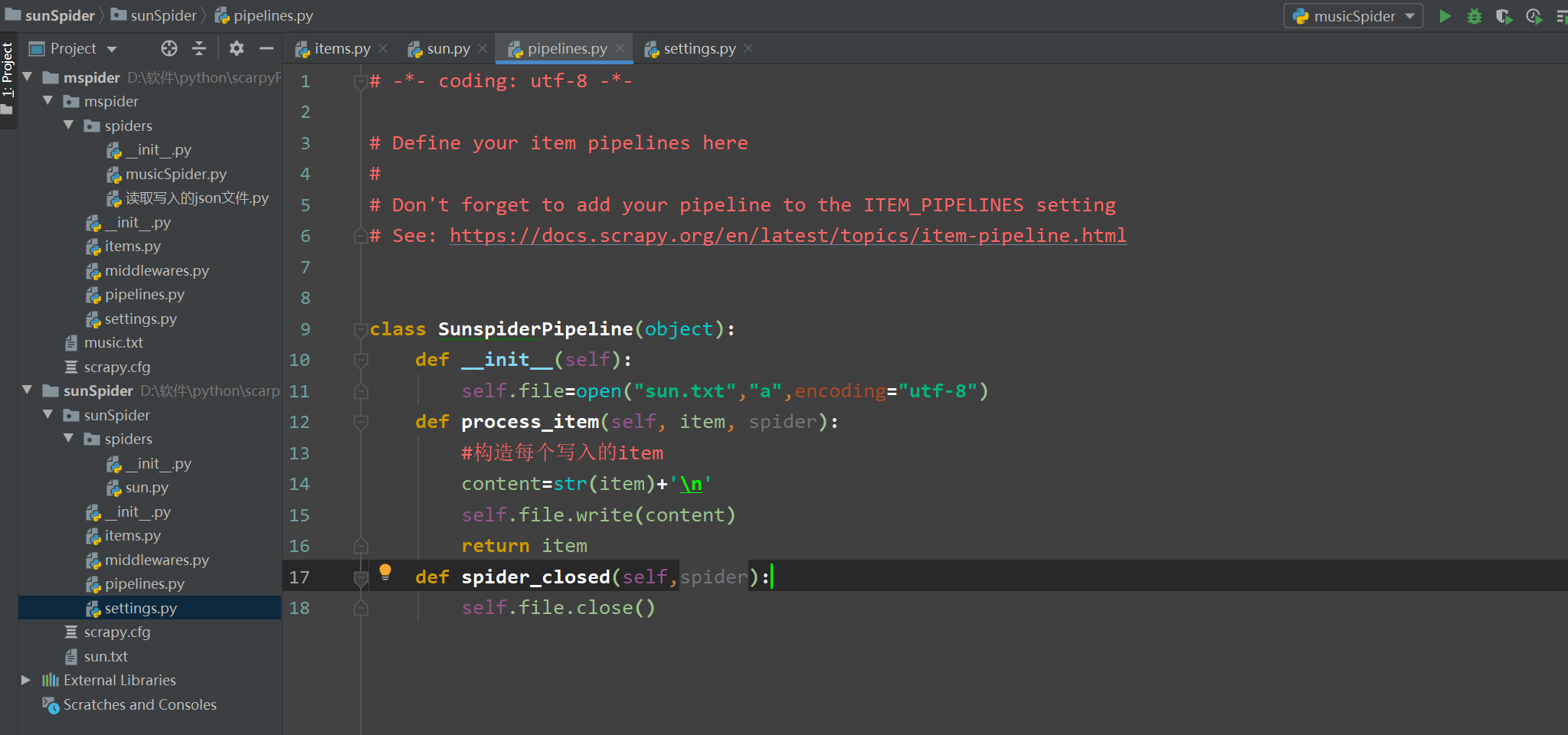
1 pipelines.py 2 3 # -*- coding: utf-8 -*- 4 5 # Define your item pipelines here 6 # 7 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 8 # See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html 9 10 11 class SunspiderPipeline(object): 12 def __init__(self): 13 self.file=open("sun.txt","a",encoding="utf-8") 14 def process_item(self, item, spider): 15 #构造每个写入的item 16 content=str(item)+' ' 17 self.file.write(content) 18 return item 19 def spider_closed(self,spider): 20 self.file.close()
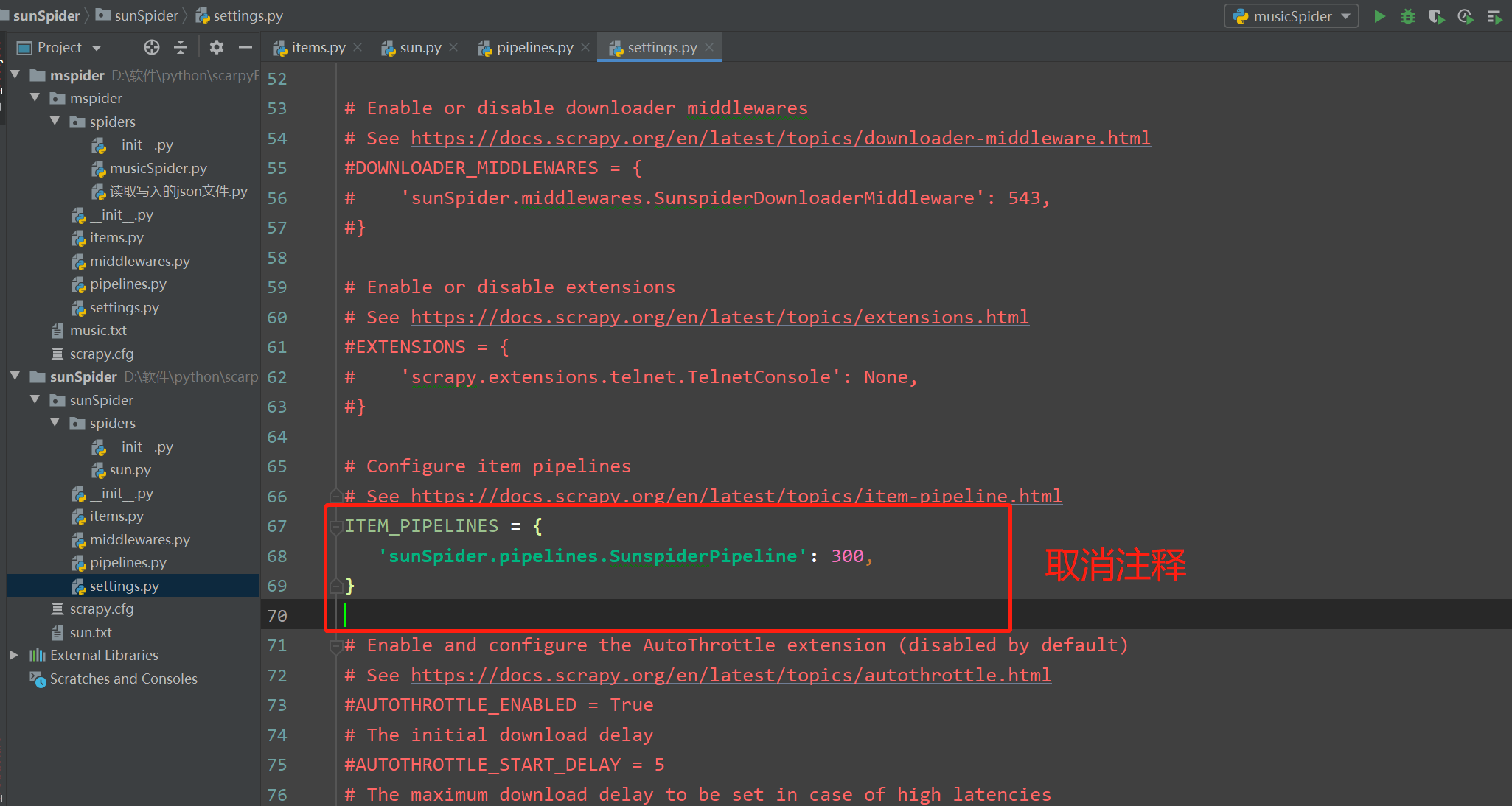
1 最后在settings.py文件中取消管道文件的注释 2 3 ITEM_PIPELINES = { 4 'sunSpider.pipelines.SunspiderPipeline': 300, 5 }