本节介绍一种查找算法——哈希查找算法;涉及的内容有:哈希函数、解决冲突的方法、哈希表、哈希查找的python实现;
1. 基本概念
关键字序列:
在哈希查找中,我们把查找表称为关键字序列;
哈希函数:
一个把关键字序列映射成相应哈希地址的函数;
冲突:
由同一个哈希函数,将关键字序列中不同的关键字映射到相同的哈希地址,这种情况称“冲突”;
同义词:
关键字序列中,发生“冲突”的两个关键字;
哈希表:
哈希表就是一种以键-值(key-value)存储数据的结构,建立了关键字key和存储地址Addr之间的一种直接映射关系;
通俗一些说就是,我们需要把关键字序列映射到另一个序列(哈希表)中,那么怎么映射呢?方法就是使用某个哈希函数对关键字进行映射得到哈希地址,那么该关键字在新的序列中的位置就由这个哈希地址来决定;如何选择哈希函数呢?如果将不同的关键字使用某个哈希函数映射得到的哈希地址一样怎么办?这就是下面将要讨论的问题。
2. 构造哈希函数
上面我们提到了两个问题,首先看第一个问题:如何选择哈希函数?下面介绍的几个哈希函数,包括:直接定位法、除留余数法、数字分析法、平方取中法以及折叠法,最长用的当数除留余数法;
2.1 直接定位法
该方法直接利用某个线性函数对关键字映射,值为映射的哈希地址,哈希函数为:
优缺点:
- 计算简单,并且不会产生冲突;
- 适合关键字分布均匀的情况;
- 如果关键字分布不均匀,则会浪费大量空间;
2.2 除留余数法
采用下面的哈希函数,对关键字进行映射:
其中,设查找表表长为(m),(p)是一个不大于但最接近或者等于m的质数;
优缺点:
- 简单,常用;
- (p)的选择影响效果,取(p)为不大于但最接近或者等于m的质数;
2.3 数字分析法
适用于已知的关键字集合;如果更换了关键字,就需要重新构造新的散列函数;
2.4 平方取中法
取关键字的平方值的中间几位作为哈希值;
2.5 折叠法
将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为哈希值;
3. 处理冲突的方法
使用处理冲突的方法,默认在关键词序列中存在不同关键字映射到相同哈希地址的情况;
3.1 开放定址法
开放地址法,使用下面递推公式得到关键字序列中的元素在新的序列中的哈希地址为:
上述递推公式中可以看出,(H(key))表示将关键词使用某种哈希函数映射后的哈希地址;之后((H(key) +d_i) \%m)表示在之前映射地址的基础上重新映射,直到在新的序列中找到空闲位置;可以看出(d_i)的选择方式不同,对应着不同的处理”冲突“的方法,因此, 根据(d_i)取值方法的不同分成下列方法:线性探测法、平方探测法、再哈希法、伪随机序列法;
3.1.1 线性探测法
当(d_i = 1, 2, cdots, m-1)时,称为线性探测法;(什么意思呢?也就是说先取(d_i=1),如果不再冲突,则冲突解决;如果仍存在冲突,继续迭代(d_i);下同)
其中,(m)是新序列的表长,(d_i = 1, 2, cdots, m-1)说明最多能探测(m-1)次,当探测到表尾地址(m-1)时,下一个探测地址为表头地址0;
在新的序列中,线性探测法可能将存入第(i)个位置的关键词的同义词存入第(i+1)个地址,而原本属于第(i+1)个地址的关键字可能存储第(i+2)个位置,这样下去,就可能造成大量元素聚集在相邻的地址中;
3.1.2 平方探测法
当(d_i = 1^2, -1^2, 2^2, -2^2,cdots, k^2, -k^2(k leq m/2)),其中(m)是新序列的表长,同时(m)必须可以表示成(4k+3)的质数,也称为二次探测法;
平方探测法可以避免出现堆积问题,缺点是不能探测到哈希表上的所有单元,但至少能探测到一半单元;
3.1.3 再哈希法
当(d_i=H_2(key)),称为再哈希法;
3.1.3 伪随机序列法
当(d_i = 伪随机数序列),称为伪随机序列法;
注意:上文中提到的”新的序列“指的就是哈希表;当一个新的序列构造完成,哈希表也就得到了;
注意:使用开放地址法解决冲突,不能随便删除哈希表中的元素,因为,若删除元素将会截断其他具有相同哈希地址的关键字的查找地址;当想要删除元素时,只能才采用逻辑上的删除,即给该元素做一个删除标记;当哈希表中执行多次删除后,哈希表看起来还是满的,实际上有很多元素已经被逻辑删除。因此需要定期维护哈希表,将逻辑删除的元素进行物理删除;
3.2 拉链法
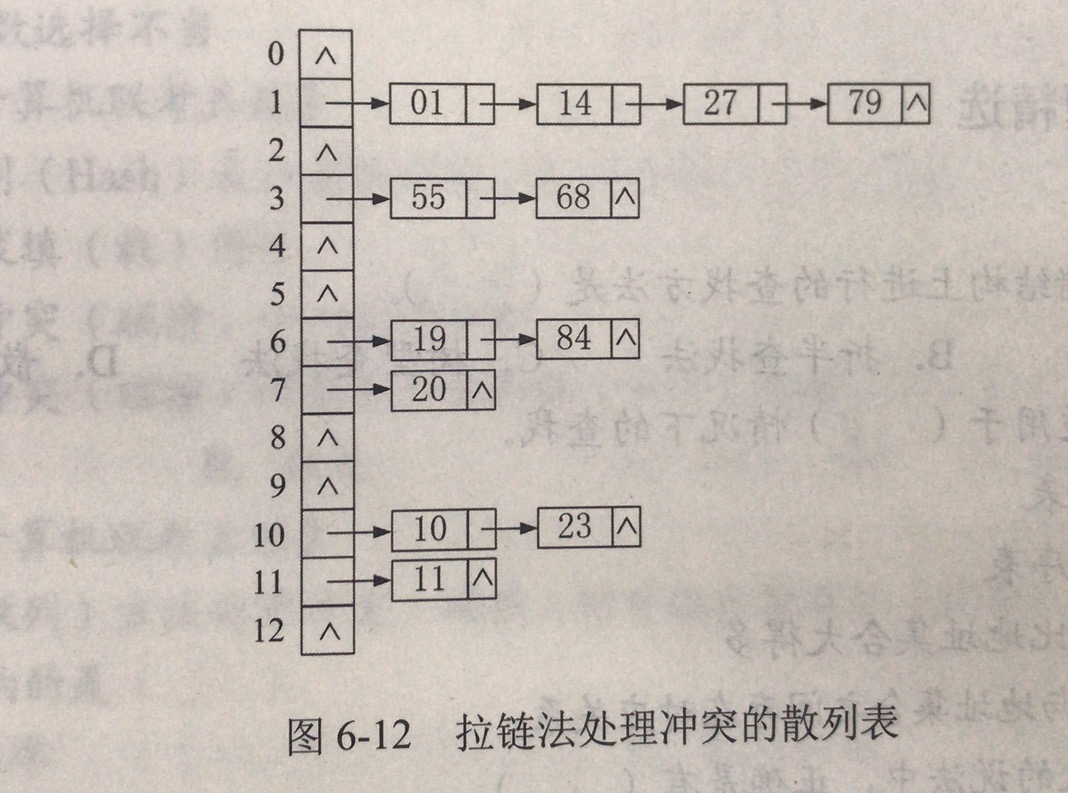
未避免上述开放地址法带来的缺点,即不能随意删除哈希表中的元素;这里有一种称为拉链法的解决冲突的方法,即把所有同义词存储在一个线性链表中,这个线性链表由其哈希地址唯一标识。
例如:关键字序列:({19, 14, 23, 01, 68, 20, 84, 27, 55, 11, 10, 79}),哈希函数(H(key) = key \% 13),采用拉链法处理冲突,建立的表如下图:
4. 哈希查找
哈希查找的过程与构造哈希表的过程基本一致:对于一个给定的关键字key,根据哈希函数可以计算出哈希地址;
步骤如下:
Step 1:初始化(Addr=Hash(key));
Step 2:检测查找表中地址为(Addr)的位置上是否有记录,若没有记录,返回查找失败;若有记录,在与key相比较,若相等,返回查找成功,否则执行步骤Step 3;
Step 3:用给定的处理冲突方法计算下一个哈希地址,并把(Addr)置为该地址,转入步骤Step 2;
下面使用python实现哈希查找,使用除留余数构造哈希函数、线性探测法解决冲突;
# -*- coding:utf-8 -*-
# @Time: 2019-04-17
# @ Author: chen
class HashSearch:
def __init__(self, length=0):
self.length = length # 需要构造的哈希表长度
self.table = [None for i in range(length)] # 初始化哈希表
self.li = None # 关键字序列
self.first_hash_value = None # 关键字哈希值
# ------------- hash function 1: 直接定址法 ---------------
def _linear_func(self, key, a, b):
"""直接定位法
Argument:
key:
需要映射的关键字
a, b: int
斜率、偏置
Return:
value:
哈希值
"""
self.first_hash_value = [a * item + b for item in key]
# ------------- hash function 2: 除留余数法 ---------------
def _prime(self, value):
"""判断是否为质数"""
for i in range(2, value // 2 + 1):
if value % i == 0:
return False
return True
def _max_prime(self, value):
"""不大于(小于或等于)给定值的最大质数"""
for i in range(value, 2, -1):
if self._prime(i):
return i
def _remainder_function(self, key, max_prime=None):
"""除留余数
Argument:
key:
需要映射的关键字
Return:
value:
哈希值
"""
if max_prime is None:
max_prime = self._max_prime(len(key)) # 小于查找表长度的最大质数
self.first_hash_value = [item % max_prime for item in key]
# ------------- 构造哈希表 1: 开放地址法—线性探测法 ---------------
def generate_hash_table_linear_probing(self, li, max_prime=None, a=1, b=1, hash_func='remainder_func'):
"""利用线性探测法解决冲突
Argument:
li: list
关键字序列
hash_func: str
选择使用的哈希函数;提供两种方式:
remainder_func: 表示除留余数法,默认;
linear_func: 表示线性定址法;
max_prime: int
当使用"remainder_func"时使用,指定最大质数;
a, b: int
当使用"linear_func"时使用,指定斜率、偏置;
Return:
table: list
构造的哈希表
"""
# ------ Step 1: 选择哈希函数 ------
self.li = li
if hash_func == 'remainder_func':
self._remainder_function(self.li, max_prime)
elif hash_func == 'linear_func':
self._linear_func(self.li, a, b)
else:
raise LookupError('select a correct hash function.')
# ----- Step 2: 迭代构造哈希表 -----
for first_hash, value in zip(self.first_hash_value, self.li):
# ----- Step 3: 迭代解决冲突 -----
for probing_times in range(1, self.length):
if self.table[first_hash] is None:
self.table[first_hash] = value
break
# ----- Step 4: 线性探测法处理冲突 -----
first_hash = (first_hash + 1) % self.length
return self.table
def hash_serach_linear_probing(self, key, hash_table, max_prime=None, a=1, b=1, hash_func='remainder_func'):
"""在哈希表中查找指定元素
Argument:
key: int
待查找的关键字
hash_table: list
查找表,上一步骤中构造的哈希表
hash_func: str
选择使用的哈希函数;提供两种方式:
remainder_func: 表示除留余数法,默认;
linear_func: 表示线性定址法;
max_prime: int
当使用"remainder_func"时使用,指定最大质数;
a, b: int
当使用"linear_func"时使用,指定斜率、偏置;
Return:
查找成功,返回待查找元素在查找表中的索引位置;否则,返回-1
"""
# ------ Step 1: 选择哈希函数 ------
if hash_func == 'remainder_func':
first_hash = key & max_prime
elif hash_func == 'linear_func':
first_hash = a * key + b
else:
raise LookupError('select a correct hash function.')
# ----- Step 2: 迭代解决冲突 -----
for probing_times in range(1, self.length):
if hash_table[first_hash] is None:
return -1
elif hash_table[first_hash] == key:
return first_hash
else:
# ----- Step 3: 线性探测法处理冲突 -----
first_hash = (first_hash + 1) % self.length
if __name__ == '__main__':
LIST = [19, 14, 23, 1, 68, 20, 84, 27, 55, 11, 10, 79] # 关键字序列
# ============
# 当使用"除留余数法"构造哈希函数时,max_prime应取不大于关键字序列长度的最大质数;
# max_prime也可以不指定,代码里自己计算其最大质数;
# 当使用"线性定址法"构造哈希函数时,注意哈希表的大小选择
# ============
max_prime = 13
length = 16 # 构造哈希表的长度
HS = HashSearch(length) # 初始化
# 构造的哈希表
hash_table = HS.generate_hash_table_linear_probing(li=LIST, max_prime=max_prime, hash_func='remainder_func')
print(hash_table)
# 查找指定元素
result = HS.hash_serach_linear_probing(1, hash_table, max_prime, hash_func='remainder_func')
print(result)