1. 前言
diff 算法是一种通过同层的树节点进行比较的高效算法,避免了对树进行逐层搜索遍历,所以时间复杂度只有 O(n)。diff 算法的在很多场景下都有应用,例如在 vue 虚拟 dom 渲染成真实 dom 的新旧 VNode 节点比较更新时,就用到了该算法。diff 算法有两个比较显著的特点:
- 比较只会在同层级进行, 不会跨层级比较。
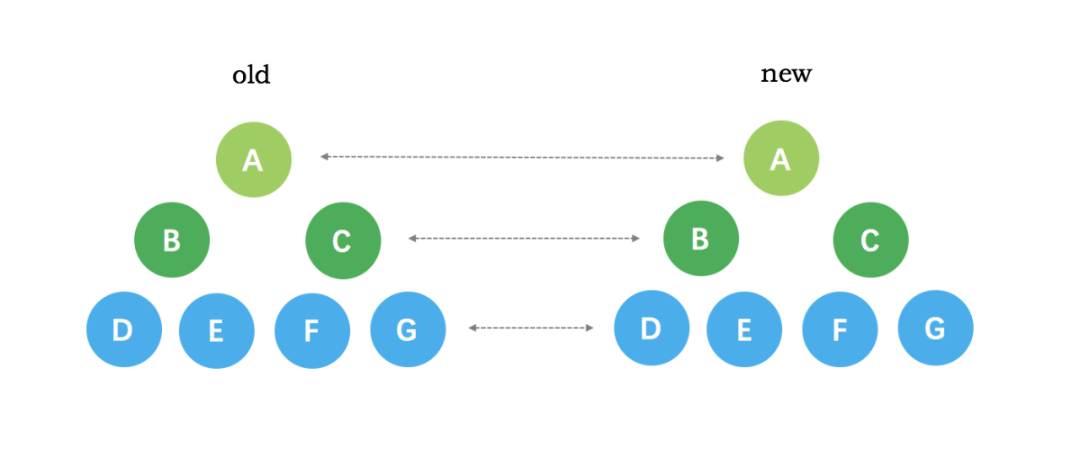
- 在 diff 比较的过程中,循环从两边向中间收拢。
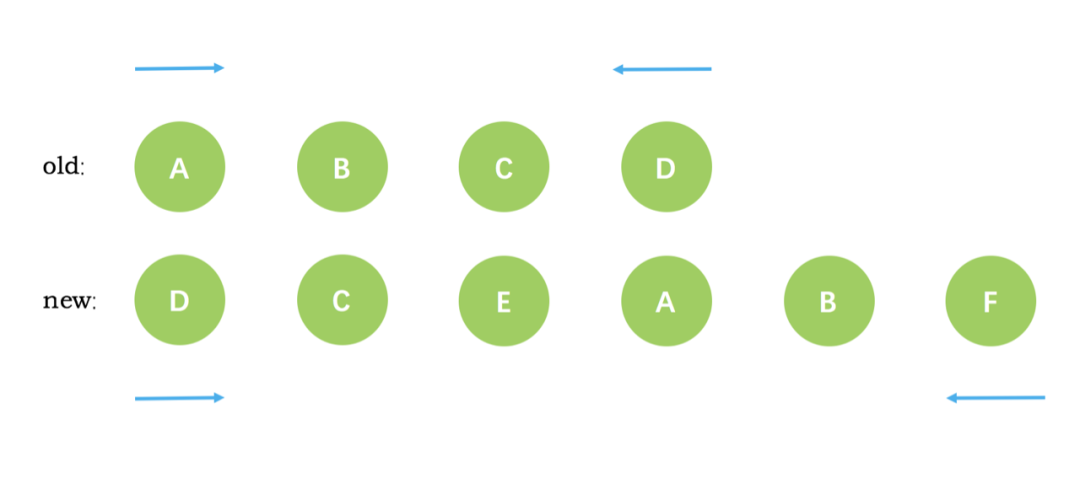
2. diff 流程
本着对 diff 过程的认识和 vue 源码的学习,我们通过 vue 源码的解读和实例分析来理清楚 diff 算法的整个流程,下面把整个 diff 流程拆成三步来具体分析:
第一步
vue 的虚拟 dom 渲染真实 dom 的过程中首先会对新老 VNode 的开始和结束位置进行标记:oldStartIdx、oldEndIdx、newStartIdx、newEndIdx。let oldStartIdx = 0// 旧节点开始下标
let newStartIdx = 0 // 新节点开始下标 let oldEndIdx = oldCh.length - 1 // 旧节点结束下标 let oldStartVnode = oldCh[0] // 旧节点开始 vnode let oldEndVnode = oldCh[oldEndIdx] // 旧节点结束 vnode let newEndIdx = newCh.length - 1 // 新节点结束下标 let newStartVnode = newCh[0] // 新节点开始 vnode let newEndVnode = newCh[newEndIdx] // 新节点结束 vnode
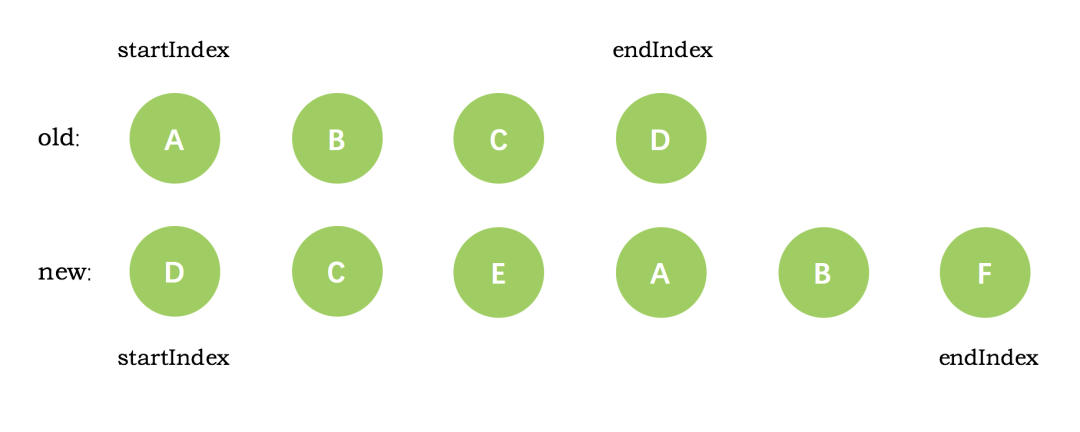 经过第一步之后,我们初始的新旧 VNode 节点如下图所示:
经过第一步之后,我们初始的新旧 VNode 节点如下图所示:
第二步标记好节点位置之后,就开始进入到的 while 循环处理中,这里是 diff 算法的核心流程,分情况进行了新老节点的比较并移动对应的 VNode 节点。while 循环的退出条件是直到老节点或者新节点的开始位置大于结束位置。
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { ....// 处理逻辑 }
情形一:当新老 VNode 节点的 start 满足 sameVnode 时,直接 patchVnode 即可,同时新老 VNode 节点的开始索引都加 1。接下来具体介绍 while 循环中的处理逻辑, 循环过程中首先对新老 VNode 节点的头尾进行比较,寻找相同节点,如果有相同节点满足 sameVnode(可以复用的相同节点) 则直接进行 patchVnode (该方法进行节点复用处理),并且根据具体情形,移动新老节点的 VNode 索引,以便进入下一次循环处理,一共有 2 * 2 = 4 种情形。下面根据代码展开分析:
if (sameVnode(oldStartVnode, newStartVnode)) { patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx) oldStartVnode = oldCh[++oldStartIdx] newStartVnode = newCh[++newStartIdx] }
else if (sameVnode(oldEndVnode, newEndVnode)) { patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx) oldEndVnode = oldCh[--oldEndIdx] newEndVnode = newCh[--newEndIdx] }
情形三:当老 VNode 节点的 start 和新 VNode 节点的 end 满足 sameVnode 时,这说明这次数据更新后 oldStartVnode 已经跑到了 oldEndVnode 后面去了。这时候在 patchVnode 后,还需要将当前真实 dom 节点移动到 oldEndVnode 的后面,同时老 VNode 节点开始索引加 1,新 VNode 节点的结束索引减 1。
else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx) canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm)) oldStartVnode = oldCh[++oldStartIdx] newEndVnode = newCh[--newEndIdx] }
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx) canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm) oldEndVnode = oldCh[--oldEndIdx] newStartVnode = newCh[++newStartIdx] }
如果都不满足以上四种情形,那说明没有相同的节点可以复用。于是则通过查找事先建立好的以旧的 VNode 为 key 值,对应 index 序列为 value 值的哈希表。从这个哈希表中找到与 newStartVnode 一致 key 的旧的 VNode 节点,如果两者满足 sameVnode 的条件,在进行 patchVnode 的同时会将这个真实 dom 移动到 oldStartVnode 对应的真实 dom 的前面;如果没有找到,则说明当前索引下的新的 VNode 节点在旧的 VNode 队列中不存在,无法进行节点的复用,那么就只能调用 createElm 创建一个新的 dom 节点放到当前 newStartIdx 的位置。
else {// 没有找到相同的可以复用的节点,则新建节点处理 /* 生成一个 key 与旧 VNode 的 key 对应的哈希表(只有第一次进来 undefined 的时候会生成,也为后面检测重复的 key 值做铺垫) 比如 childre 是这样的 [{xx: xx, key: 'key0'}, {xx: xx, key: 'key1'}, {xx: xx, key: 'key2'}] beginIdx = 0 endIdx = 2 结果生成{key0: 0, key1: 1, key2: 2} */ if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) /* 如果 newStartVnode 新的 VNode 节点存在 key 并且这个 key 在 oldVnode 中能找到则返回这个节点的 idxInOld(即第几个节点,下标)*/ idxInOld = isDef(newStartVnode.key) ? oldKeyToIdx[newStartVnode.key] : findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx) if (isUndef(idxInOld)) { // New element /*newStartVnode 没有 key 或者是该 key 没有在老节点中找到则创建一个新的节点 */ createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx) } else { /* 获取同 key 的老节点 */ vnodeToMove = oldCh[idxInOld] if (sameVnode(vnodeToMove, newStartVnode)) { /* 如果新 VNode 与得到的有相同 key 的节点是同一个 VNode 则进行 patchVnode*/ patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx) // 因为已经 patchVnode 进去了,所以将这个老节点赋值 undefined oldCh[idxInOld] = undefined /* 当有标识位 canMove 实可以直接插入 oldStartVnode 对应的真实 Dom 节点前面 */ canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm) } else { // same key but different element. treat as new element /* 当新的 VNode 与找到的同样 key 的 VNode 不是 sameVNode 的时候(比如说 tag 不一样或者是有不一样 type 的 input 标签),创建一个新的节点 */ createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx) } } newStartVnode = newCh[++newStartIdx] }
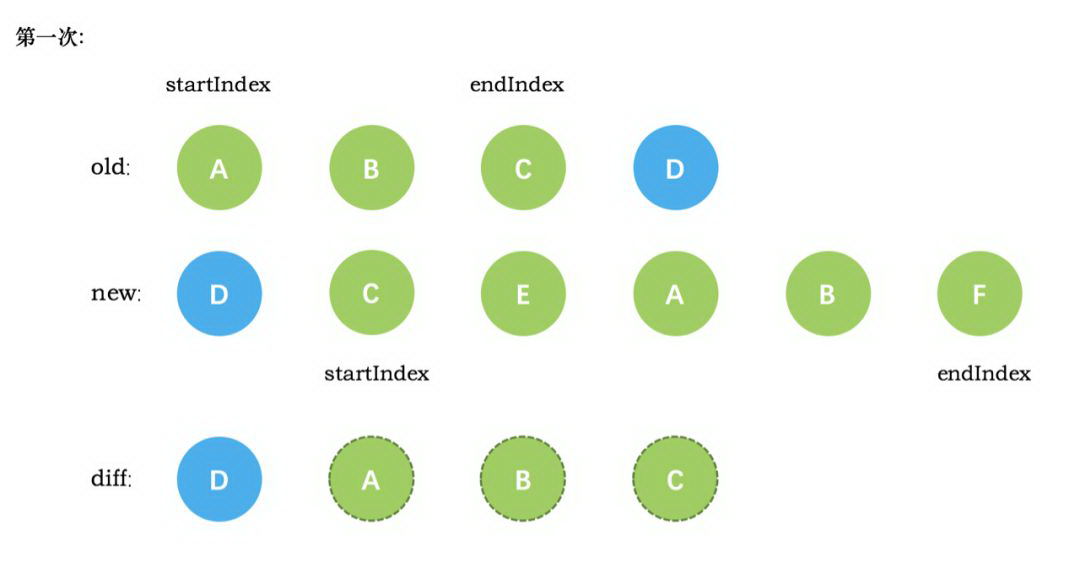
紧接着开始第二次循环,第二次循环后,同样是旧节点的末尾和新节点的开头 (都是 C) 相同,同理,diff 后创建了 C 的真实节点插入到第一次创建的 B 节点后面。同时旧节点的 endIndex 移动到了 B,新节点的 startIndex 移动到了 E。
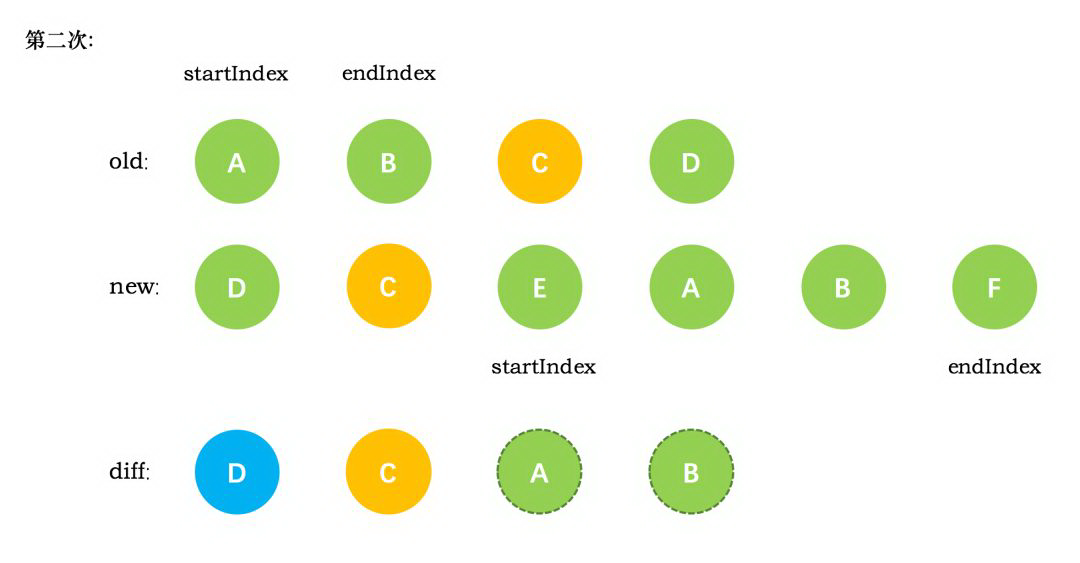
接下来第三次循环中,发现 patchVnode 的 4 种情形都不符合,于是在旧节点队列中查找当前的新节点 E,结果发现没有找到,这时候只能直接创建新的真实节点 E,插入到第二次创建的 C 节点之后。同时新节点的 startIndex 移动到了 A。旧节点的 startIndex 和 endIndex 都保持不动。
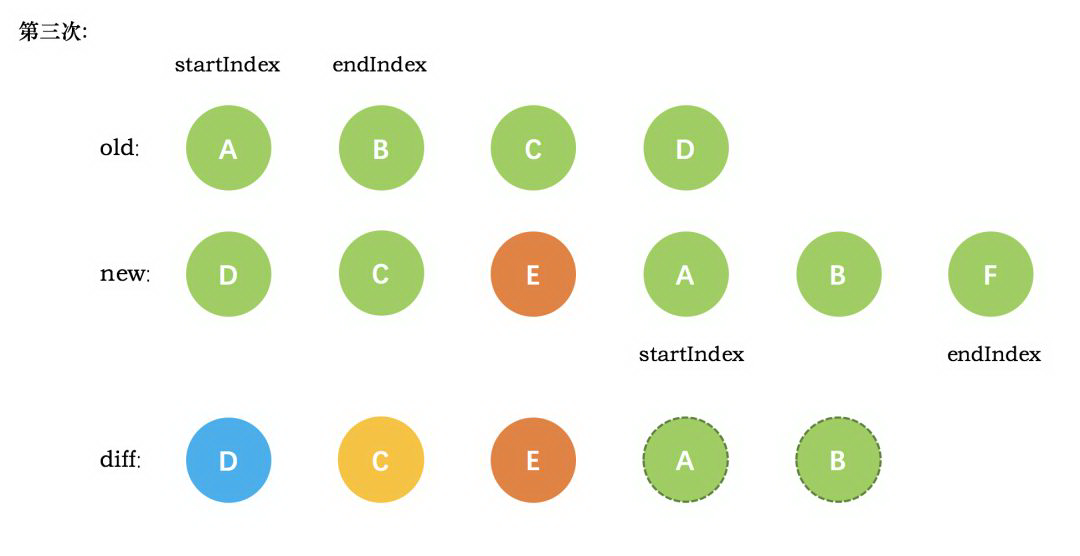
第四次循环中,发现了新旧节点的开头 (都是 A) 相同,于是 diff 后创建了 A 的真实节点,插入到前一次创建的 E 节点后面。同时旧节点的 startIndex 移动到了 B,新节点的 startIndex 移动到了 B。
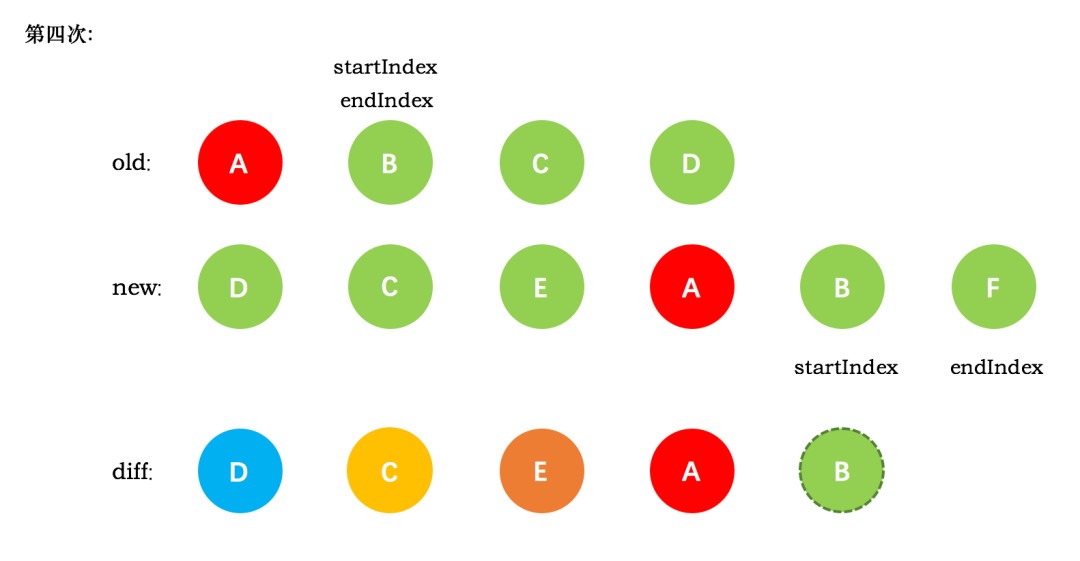
第五次循环中,情形同第四次循环一样,因此 diff 后创建了 B 真实节点 插入到前一次创建的 A 节点后面。同时旧节点的 startIndex 移动到了 C,新节点的 startIndex 移动到了 F。
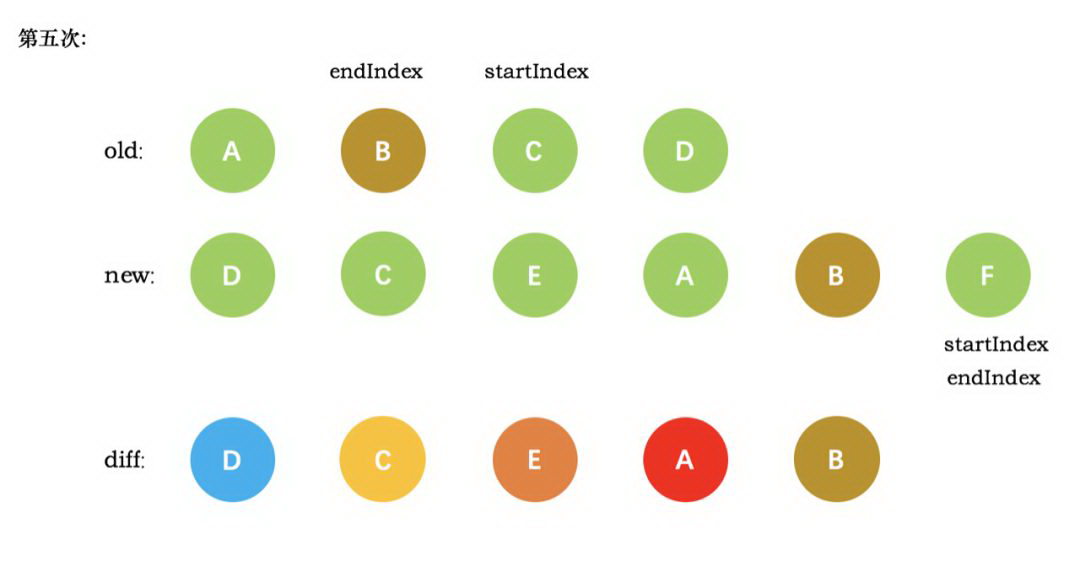
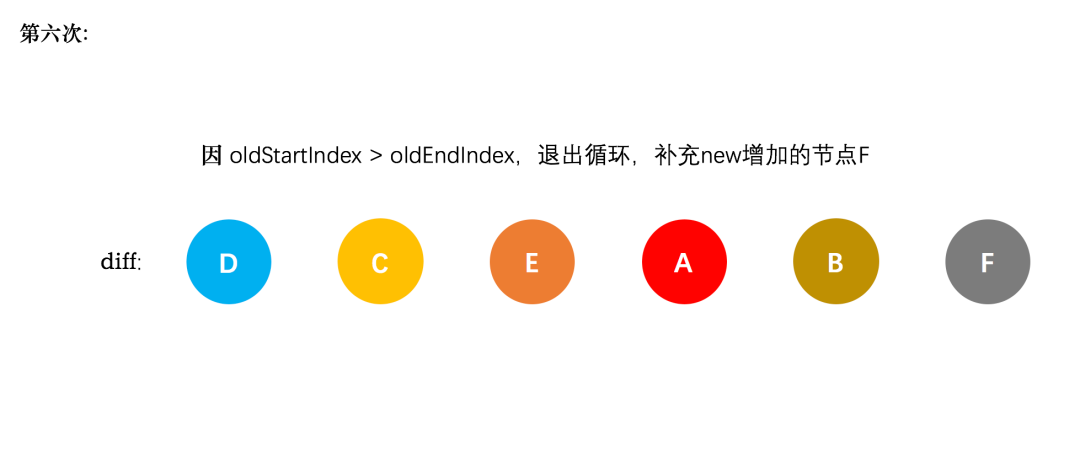
这时候发现新节点的 startIndex 已经大于 endIndex 了。不再满足循环的条件了。因此结束循环,接下来走后面的逻辑。
第三步当 while 循环结束后,根据新老节点的数目不同,做相应的节点添加或者删除。若新节点数目大于老节点则需要把多出来的节点创建出来加入到真实 dom 中,反之若老节点数目大于新节点则需要把多出来的老节点从真实 dom 中删除。至此整个 diff 过程就已经全部完成了。
if (oldStartIdx > oldEndIdx) { /* 全部比较完成以后,发现 oldStartIdx > oldEndIdx 的话,说明老节点已经遍历完了,新节点比老节点多, 所以这时候多出来的新节点需要一个一个创建出来加入到真实 Dom 中 */ refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue) // 创建 newStartIdx - newEndIdx 之间的所有节点 } else if (newStartIdx > newEndIdx) { /* 如果全部比较完成以后发现 newStartIdx > newEndIdx,则说明新节点已经遍历完了,老节点多于新节点,这个时候需要将多余的老节点从真实 Dom 中移除 */ removeVnodes(oldCh, oldStartIdx, oldEndIdx) // 移除 oldStartIdx - oldEndIdx 之间的所有节点 }
再回过头看我们的实例,新节点的数目大于旧节点,需要创建 newStartIdx 和 newEndIdx 之间的所有节点。在我们的实例中就是节点 F,因此直接创建 F 节点对应的真实节点放到 B 节点后面即可。
3. 结尾
最后通过上述的源码和实例的分析,我们完成了 Vue 中 diff 算法的完整解读。如果想要了解更多的 Vue 源码。欢迎进入我们的 github 地址( https://github.com/DQFE/vue )进行查看,里面对每一行 Vue 源码都做了注释,方便大家的理解。
作者介绍:
徐辉,滴滴软件开发工程师
现就职于泛前端问卷项目组,负责星云和桔研问卷相关工作,爱好广而不精,喜欢篮球、游戏、爬山。努力工作,开心生活!
本文转载自公众号普惠出行产品技术(ID:pzcxtech)。
原文链接: