urllib模块:
urllib.requests: 打开和读取urls
urllib.error: 包含urllib.requests 产生的常见错误,使用try捕捉
urllib.parse: 包含即系url方法
urllib.robotparse: 解析robots.txt文件
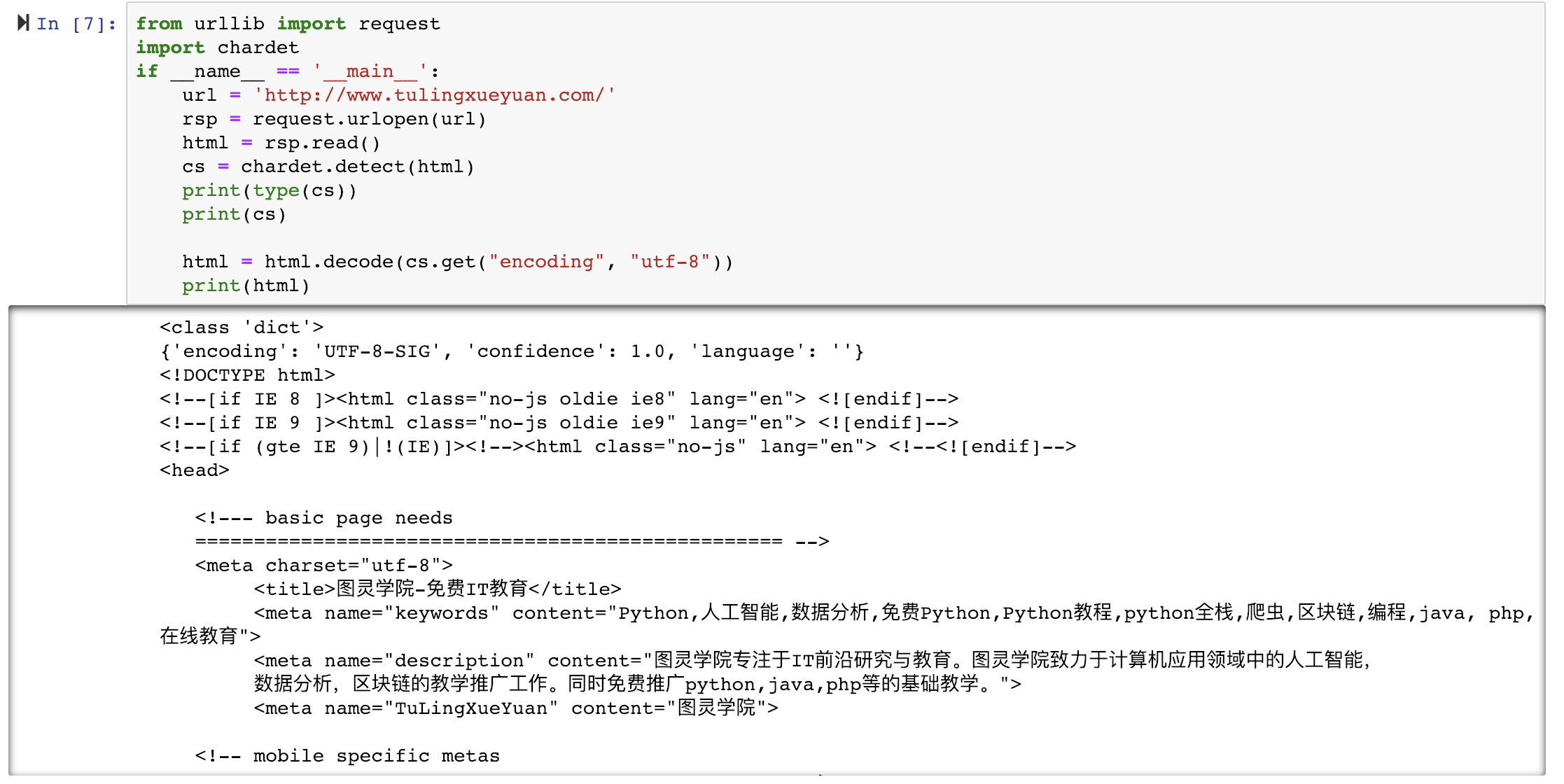
网页编码问题解决:
chardet 可以自动检测页面文件的编码格式,可能有误
urlopen的返回对象:
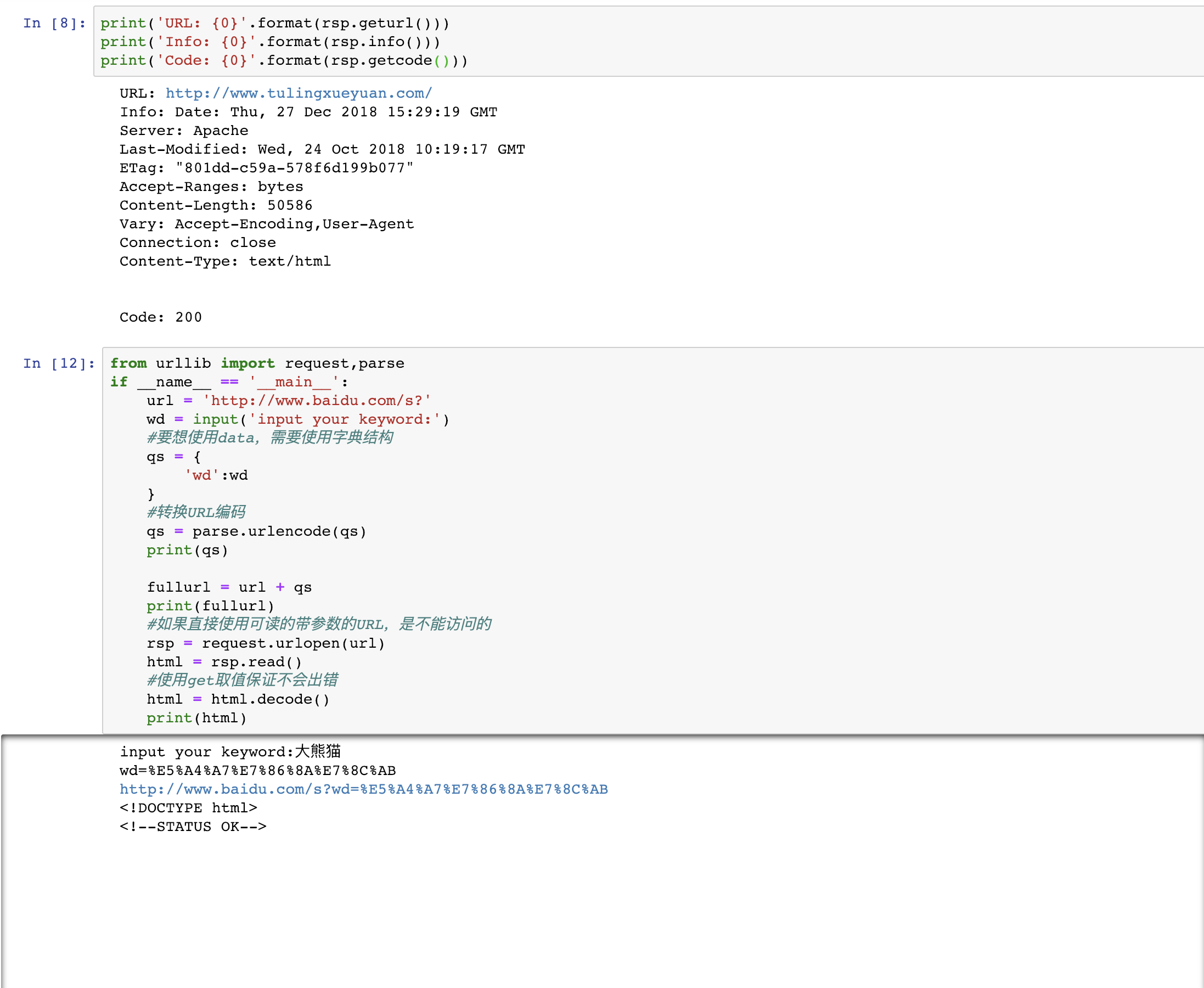
geturl: 返回请求对象的url
info: 返回请求对象的meta信息
getcode: 返回http code
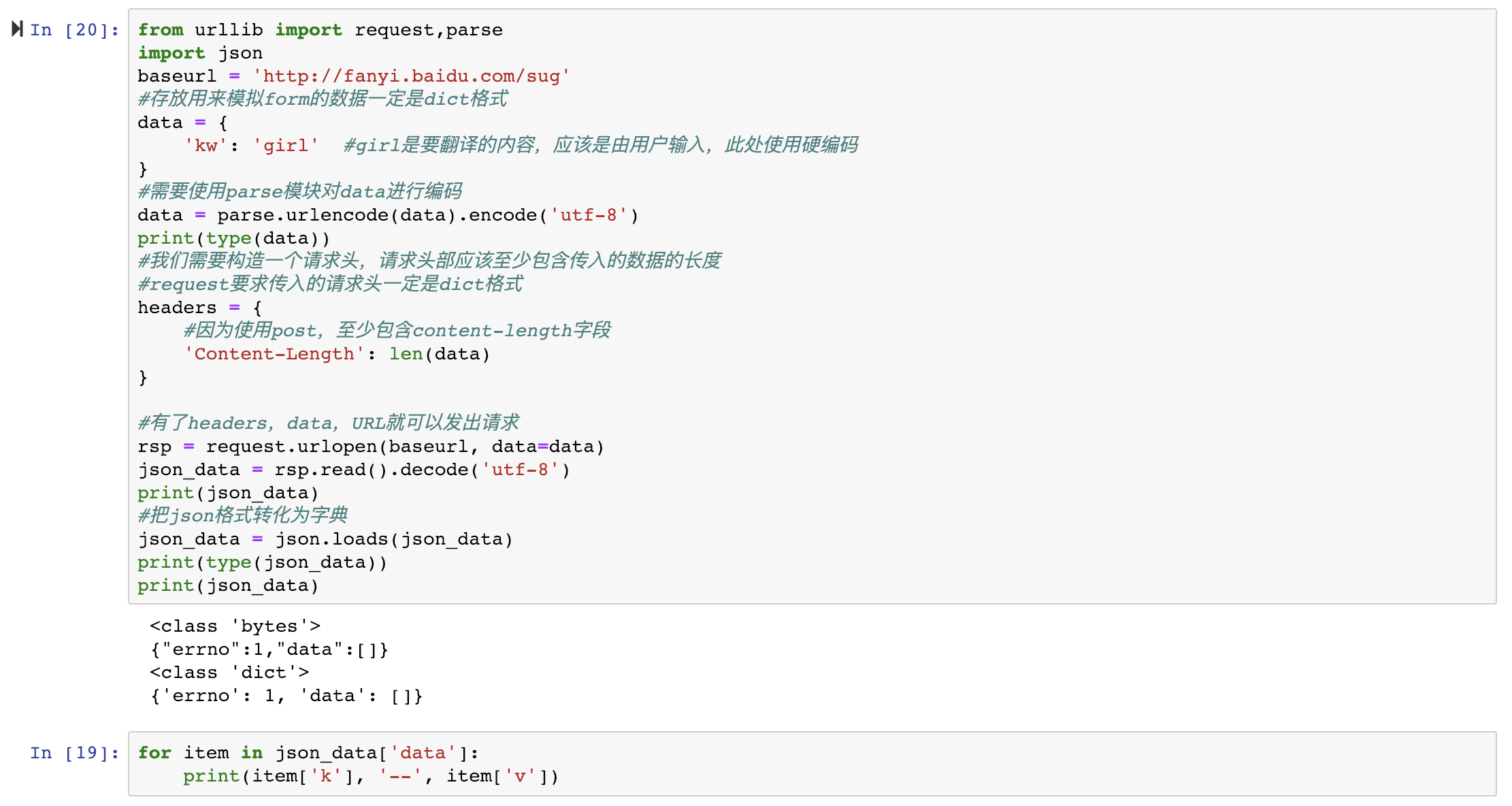
request.data:
访问网络的两种方法:
get:利用参数给服务器传递信息,参数为dict,然后用parse编码
post:一般向服务器传递参数使用,把信息自动加密处理,如果想使用post信息,需要使用data参数
使用post,意味着http的请求头可能需要修改
一旦更改请求方法,需要注意其他请求头部信息相适应
request.Request
urllib.error: 没网,服务器连接失败, 不知道指定服务器, OS.error子类 一般对应网络出现问题,包括URL问题
HTTPError 对应的HTTP请求的返回码的错误,是URLError的一个子类
UserAgent 用户代理,属于heads一部分,服务器通过UA判断访问者身份 使用时可以复制,也可以web抓包
设置方式: heads , add_header