这个部分将讲解一些性能分析工具,这些性能分许主要关注在执行计划。
缓存执行计划
SQL Server 2008提供了一些服务器对象来分析执行计划
Sys.dm_exec_cached_plans: 包含缓存的执行计划,每个执行计划对应一行。
Sys.dm_exec_plan_attributes: 这是一个系统函数,每一个执行计划都对应着一些属性,在这个系统函数中包含着这些属性。
Sys.dm_exec_sql_text: 这是一个系统函数,返回文字格式的执行计划。
Sys.dm_exec_query_plan: 这是一个系统函数,返回xml格式的执行计划。
SQL Server 2008还提供了一个兼容性的视图sys.syscacheobject,这个视图中保存了所有的执行计划的信息。
清除缓存
在进行性能分析的时候有时候需要清除缓存以便进行下一次分析。SQL Server提供了一些工具来清除缓存的性能数据。使用下面的语句来完成这些任务。
清除全局缓存使用下面的语句:
DBCC DROPCLEANBUFFERS;
从全局缓存中清除执行计划,使用下面的语句:
DBCC FREEPROCCACHE;
清除某一个数据库中的执行计划,使用下面的语句:
DBCC FLUSHPROCINDB(<db_id>);
清除一个特定的执行计划使用下面的语句:
DBCC FREESYSTEMCACHE(<cachestore>);
可以使用’ALL’,pool_name,’Object Plan’,’SQL Plans’,’Bound Trees’作为输入参数。’ALL’参数标明要清除所有的缓存,pool_name的值表明要清除的一个缓存池的名字。’Object Plans’清除对象计划(例如存储过程,触发器,用户定义函数等等)。’SQL Plans’用来清除要立即执行的语句。’Bound Trees’定义清除视图,约束等的缓存。
注意:在使用这些语句清除缓存之前要想清楚,特别是在生产环境。这些对性能有很大的影响。清除这些缓存之后SQL Server需要从数据页中重新读取数据。并且SQL Server需要重新生成新的执行计划。因此在清除之前要想清楚这些对生产或者测试环境的影响。
动态的管理对象
SQL Server 2005引入了动态管理对象,例如DMV,DMF。SQL Server 2008中添加了新的对象,新的属性。这些饱含非常有用的信息,利用这些信息可以监视SQL Server,诊断问题,进行性能监视。要仔细研究这些对象会很耗时。这里只是列举一些常用的。
统计IO
统计IO是是一个session选项。它返回域当前执行的语句相关的I/O信息。要使用这个选项首选清除数据缓存:
DBCC DROPCLEANBUFFERS;
然后运行下面的代码来打开这个选项:
SET STATISTICS IO ON;
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders
WHERE orderdate >= '20060101'
AND orderdate < '20060201';
最后可以得到类似下面的信息:
(21226 row(s) affected)
Table 'Orders'. Scan count 1, logical reads 537, physical reads 3, read-ahead reads 549, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
从输出信息中我们可以看到在执行计划中有多少次获取表(Scan count);多少次读取缓存(logical reads);多少次读取硬盘(physical reads 俺的read-ahead reads);多少次读取大的对象(lob physical reads , log read-ahead reads)。
使用下面的语句来关闭这个选项:
SET STATISTICS IO OFF;
统计运行时间
STATISTICS TIME是一个用来返回CPU时钟时间的session选项。它返回语法分析,编译,执行的时间。要使用这个选项首选要清除执行计划缓存。
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
运行下面的语句来打开相应的选项:
SET STATISTICS TIME ON;
运行下面的语句:
SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders WHERE orderdate >= '20060101' AND orderdate < '20060201';
得到下面的信息:
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 4 ms.
SQL Server Execution Times:
CPU time = 46 ms, elapsed time = 544 ms.
从这些信息中可以获得执行这个语句时候的CPU时钟时间,编译时间,运行时间。运行下面的语句可以关闭这个选项:
SET STATISTICS TIME OFF;
当需要分析一个单独的语句的性能的时候这个选项非常有用。当需要使用批处理的模式来运行语句的时候需要度量会有所不同。在查询之前保存SYSDATETIME函数的值,并写入到一个表中。注意这个函数返回的时间格式是DATETIME2,可以精确到100纳秒。这个函数的准确性取决于计算机硬件和操作系统版本。因为这个函数会调用GetSystemTimeAsFileTime()这个WindowsAPI。需要统计时间的时候可以重复地运行请求语句,然后记录下需要的时间。
分析执行计划
执行计划是SQL优化器生成的如何处理给定的请求的一个工作计划。它包含这个请求中药用到的操作符。有一些操作可能会执行多次。一些计划分支可能会并行执行。在这个工作计划中,优化器决定获取语句中涉及到的表的顺序,要使用到那些索引,要使用那些查询方法,要使用那些算法等等。事实上,优化器会在多个执行计划中选择出一个最优的,资源耗费最少的。频繁地生成执行计划也会耗费时间,所以SQL Server也会根据数据量的大小估算生成执行计划所需要的阀值时间。生成执行计划的时间不会超过这个估算的阀值时间。还有一个阀值是根据耗费的资源计算得到的。如果一个工作计划的资源耗费低于这个阀值,就认为它是足够好的,优化器就会停止优化使用这个计划。
图形执行计划
SSMS允许我们查看一个图形化的执行计划(快捷键Ctrl+L)。注意当查看一个执行计划的时候,查询并没有运行。一些度量值只能在运行完之后才能得到(实际查询得到的行的数目)。
使用下面的语句来查看执行计划:
SELECT custid, empid, shipperid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderdate >= '20080201' AND orderdate < '20080301'
GROUP BY CUBE(custid, empid, shipperid);
这个语句查询得到所有可能的聚合值,聚合属性是custid,empid,shipperid。如图1
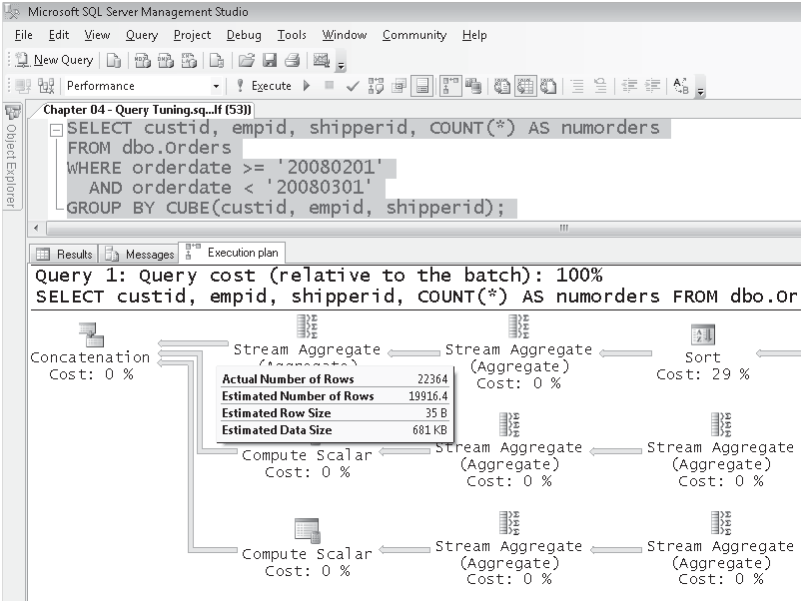
图1
注意当这个执行计划占用很大的屏幕空间的时候可以点击右下方的按钮“+”不放,然后拖动鼠标可以查看想要查看的区域。
执行计划是由一些操作组成的树状结构图。数据从子运算流向父运算。这个结构的顺序是从右到左,从上到下。在这个例子中,运算首选从聚集索引开始,然后是后面的操作缠绕运算-Table Spool
注意每个运算符旁边有一个百分比,这个值表值这个运算在整个执行过程中所占的资源百分比,这个值只是优化器估计的值。SQL语句的优化工作应该放在那些所占的百分比比较大的操作上面。当把鼠标放上去的时候,会有一个换色的提示框。有一个值是Estimated Subtree Cost。最上方,最作坊的运算时整个运算的资源开销。如图2
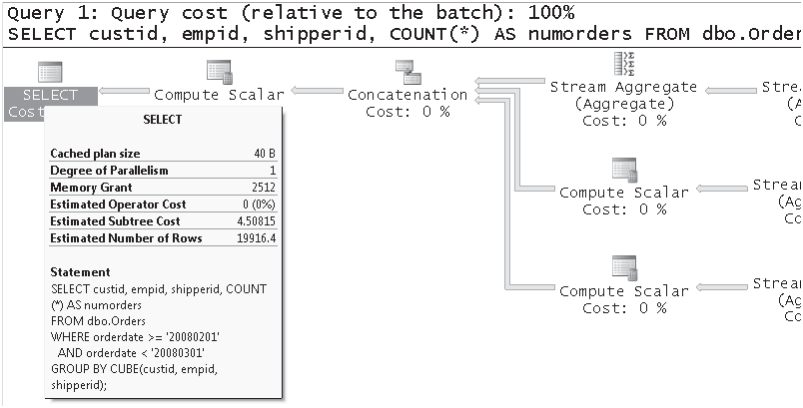
图2
注意这些值只是优化器估计出的值,优化器会使用这个值来和其他的估计值作比较进而选择出一个最优的执行计划。
另外一个比较好的地方时你可以同时生成多个语句的执行计划,进而对他们进行比较。例如下面的语句:

--1
SELECT custid, orderid, orderdate, empid, filler
FROM dbo.Orders AS O1
WHERE orderid =
(SELECT TOP (1) O2.orderid
FROM dbo.Orders AS O2
WHERE O2.custid = O1.custid
ORDER BY O2.orderdate DESC, O2.orderid DESC);
--2
SELECT custid, orderid, orderdate, empid, filler
FROM dbo.Orders
WHERE orderid IN
(
SELECT
(SELECT TOP (1) O.orderid
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS oid
FROM dbo.Customers AS C
);
--3
SELECT A.*
FROM dbo.Customers AS C
CROSS APPLY
(SELECT TOP (1)
O.custid, O.orderid, O.orderdate, O.empid, O.filler
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS A;
--4
WITH C AS
(
SELECT custid, orderid, orderdate, empid, filler,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS n
FROM dbo.Orders
)
SELECT custid, orderid, orderdate, empid, filler
FROM C
WHERE n = 1;
他们的 查询结果是一样的,但是执行计划是不同的。在每个执行计划的开头有一个百分比指示这个语句在所有的语句所占的开销的百分比。在这个例子中我们可以看到第一个语句的比例是37%,第二个语句的比例是19%,第三个是30%,第四个是14%。从这个结果我们可以粗略的认定第四个语句的效率要高一些。
当把鼠标放在运算符上面的时候会有一个黄色的提示框如图4
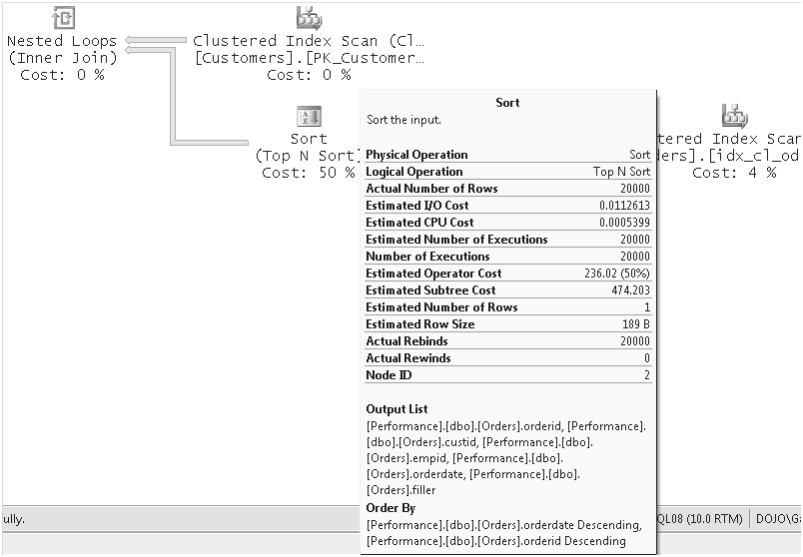
图4
在这个提示框中有下面的一些度量信息:
- 操作符的名字和简单的介绍
- 物理运算:计算机内部的物理运算
- 逻辑运算:与物理运算符匹配的逻辑运算符,如 Inner Join 运算符。逻辑运算符列在物理运算符之后,两者均位于工具提示的顶部。
- 返回的行数: 运算返回的数据行数
- 估计I/O开销,估计CPU开销: 这个数据可以用来估算这个操作是不是造成很大的CPU或者I/O开销,一般Sort操作都会造成很大的I/O开销
- 估计执行行数和执行行数:估计该操作执行的次数和实际执行的次数。这个数据可以帮助你找到更好的执行语句
- 估计执行开销:用于执行此操作的查询优化器的开销
- 估计子树开销:查询优化器执行此操作及同一子树内位于此操作之前的所有操作的总开销
- 运算生成的行数:估计运算符生成的行数。有些情况下可以通过实际行数和估计行数之间的差异来判断一个SQL语句的优劣
- 估计数据大小:操作符生成的行的估计大小(字节)。可能你会疑惑为什么这个实际行数没有显示在执行计划里面,那是因为数据行里面有可变长度的数据类型
- 实际的重绑和重绕: 这个数据之和一些特定的操作有关(非聚集的缠绕,远程请求,行数缠绕,排序,表缠绕,表值函数,断言,过滤等)。只有在内层嵌套查询的时候这才会统计个度量信息,否则Rebinds是1,Rewinds是0。这些数据表示内层的Init方法被调用。重绑和重绕的综合应该是外连接得到的行数之和。重绑意味着一个或者多个相关的连接参数改变了,需要重新估算。重绕意思是相关的参数没有改变,可以重用先前得到的内部结果集
- 底部的信息:显示相关的对象名,输出,参数等等
选中一个操作符,按下F4键,可以查看更加详细的信息。
文本格式的执行计划
可以通过设置以文本格式查看执行计划。设置SHOWPLAN_TEXT选项可以达到这个目的,如下:
SET SHOWPLAN_TEXT ON;
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders WHERE orderid = 280885;
查看执行计划(CTRL+L)得到下面的结果:
(1 row(s) affected)
StmtText
-----------------------------------------------------------------------------------------------------
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders WHERE orderid = 280885;
(1 row(s) affected)
StmtText
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|--Nested Loops(Inner Join, OUTER REFERENCES:([Uniq1002], [Performance].[dbo].[Orders].[orderdate]))
|--Index Seek(OBJECT:([Performance].[dbo].[Orders].[PK_Orders]), SEEK:([Performance].[dbo].[Orders].[orderid]=[@1]) ORDERED FORWARD)
|--Clustered Index Seek(OBJECT:([Performance].[dbo].[Orders].[idx_cl_od]), SEEK:([Performance].[dbo].[Orders].[orderdate]=[Performance].[dbo].[Orders].[orderdate] AND [Uniq1002]=[Uniq1002]) LOOKUP ORDERED FORWARD)
(3 row(s) affected)
(1 row(s) affected)
分析这个执行计划,从内层的分支到外层分支,从上到下。但是在这里我们只能看到运算符的名字和参数。运行下面的语句关闭这个选项:
SET SHOWPLAN_TEXT OFF;
如果想得到更加详细的执行计划信息,使用SHOWPLAN_ALL选项查看执行计划,STATISTICS PROFILE选项查看具体的某一个执行计划。SHOWPLAN_ALL将执行计划的信息写入到一个表中,其中包含的一些估计的值有:StmtText, StmtId, NodeId, Parent, PhysicalOp, LogicalOp, Argument, Defi nedValues,EstimateRows, EstimateIO, EstimateCPU, AvgRowSize, TotalSubtreeCost, OutputList,Warnings, Type, Parallel, and EstimateExecutions。
通过下面的语句打开这个选项:
SET SHOWPLAN_ALL ON;
运行下面的语句:
SELECT orderid, custid, empid, shipperid, orderdate, filler
FROM dbo.Orders WHERE orderid = 280885;
得到的结果如下图5:

图5
运行下面的语句关闭选项:
SET SHOWPLAN_ALL OFF;
STATISTICS PROFILE选项会产生一个实际的计划。设置这个选项为ON的时候显示的结果和设置SHOWPLAN_ALL为ON差不多,不过多了两个属性Rosw和Executes,表示实际的行数和运行行数。
语句如下:
SET STATISTICS PROFILE ON;
SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders WHERE orderid = 280885;
取消设置:
SET STATISTICS PROFILE OFF;
XML格式的执行计划
如果想用自己的代码来描述执行计划或者把执行计划发送给客户或者同事,你会发现使用文本格式的信息很不方便。SQL Server 2008允许允许返回XML格式的执行计划内容,这非常利于使用应用程序代码处理。打开使用SQL Server 2008产生的xml格式的执行计划会显示成图形结果,后缀是.sqlplan。
打开这个选项的代码如下:
SET SHOWPLAN_XML ON;
运行语句
SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders WHERE orderid = 280885;
运行结果如下图6:
![]()
图6
点击这个xml文件,图形格式的执行计划如下图7:
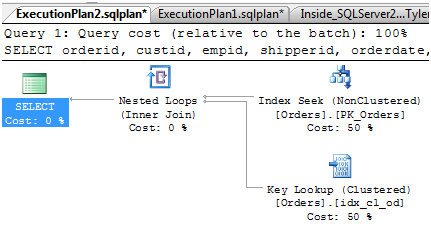
图7
使用下面的语句关闭选项:
SET SHOWPLAN_XML OFF;
为了不影响其他语句的输出效果建议使用类似下面的代码来查看效果:
SET STATISTICS XML ON;
GO
SELECT orderid, custid, empid, shipperid, orderdate, filler FROM dbo.Orders WHERE orderid = 280885;
GO
SET STATISTICS XML OFF;
可以看出XML格式的执行计划提供了最友好的查看形式。
更多知识请参见:http://www.cnblogs.com/tylerdonet/tag/SQL%E7%82%B9%E6%BB%B4/