Motivation
网络剪枝(Network Pruning)就是删除一个较大网络中的一些weight或neuron得到一个更小的网络。
我们相信,通常情况下我们训练出的神经网络是over-parameterized,即其中存在很多weight或neuron是没有用的(比如有些neuron的输出总是0、有些weight非常接近0) ,因此我们可以把这些没有用的weight或neuron剪掉。
在90年代,Yann Le Cun就提出了“网络剪枝”,paper名称为Optimal Brain Damage。
有个问题是:为什么不直接使用较小Network而是对较大Network进行剪枝?常见的解释是:较小的Network训练出来的结果一般都不好,而较大的Network更容易optimize(李老师这个视频有讲解为什么:https://www.youtube.com/watch?v=_VuWvQUMQVk)。在训练神经网络时可能会遇到local minima和saddle point的问题,但如果Network够大这种问题就会不那么严重,现在有很多文献甚至可以证明只要Network够大就可以用梯度下降找到global optimal。
How to Prune a Network
-
训练出一个较大的Network
-
评估该Network中每个weight和neuron的重要性
这一步有很多种做法
-
weight的重要性
比如:如果其值接近0,则说明该weight不重要,因此可以计算weight的L1或L2判断weight的重要性。
-
neuron的重要性
比如:给定dataset,如果某个neural的输出都是0那么该neural是不那么重要的
-
-
根据重要性将weight和neuron排序并删除那些不那么重要的weight和neuron
删除一些weight和neuron后,Network会变小但精度一般也会变低,因此还需要进行fine-tune
一次最好不要删除太多neuron或weight,否则Network的精度会无法通过fine-tune恢复,最好是每次只删除一小部分然后进行fine-tune并重复该过程
-
fine-tune
训练剪枝得到的较小的网络
熟悉YOLO的读者,可以根据这个仓库(https://github.com/tanluren/yolov3-channel-and-layer-pruning)感受一下剪枝和知识蒸馏。
Lottery Ticket Hypothesis
论文链接:https://arxiv.org/abs/1803.03635,这是ICLR2019的一篇论文
如下图所示,现有一个较大网络A,随机初始化其参数并记该参数为W,训练该较大网络A并进行剪枝得到较小网络B。有个现象是:如果我们随机初始化较小网络B的参数并进行训练,得到的结果就不行;但如果使用参数W中的对应参数初始化,得到的结果就可以。
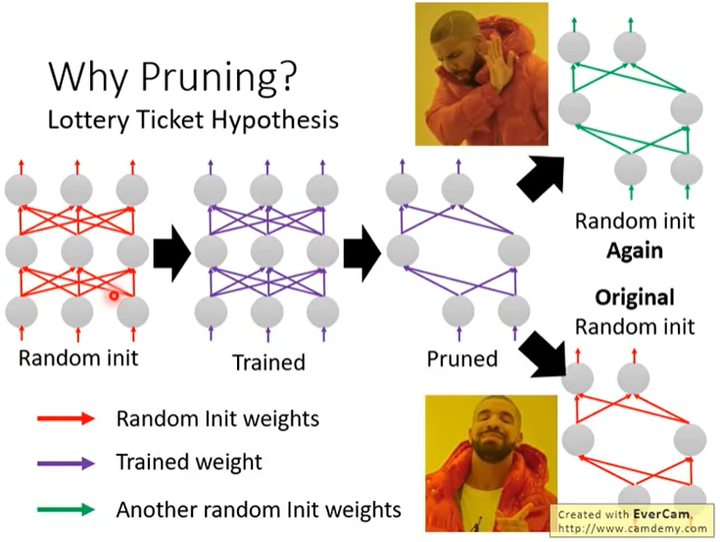
Rethinking the Value of Network Pruning
论文链接:https://arxiv.org/abs/1810.05270,这是ICLR2019的一篇论文
这篇论文的结论和Lottery Ticket Hypothesis一文相反:现有剪枝后的网络,将其参数随机初始化是可以训练出好的结果的。
ICLR2019的review是开放的,网上可以搜到两篇文章作者的讨论,知乎上也有关于这两篇论文的讨论,后续也有人做了相关研究。
Some Issue in Weight Pruning
如果是weight pruning,那剪枝后的Network会变得不规则(比如有些neuron有2个weight而有些neuron有4个weight)。这样的不规则的Network是不好用keras等代码框架实现的,并且GPU只能对矩阵运算进行加速而无法加速这样的Network。比较常见的实做方法是将需要剪掉的weight设成0,因此仍然可以用GPU加速,但这样其实并没有使网络变小。
实际上做weight pruning是很麻烦的,通常都进行neuron pruning,因为比较容易用代码实现、也容易达到加速的目的。
Github(github.com):@chouxianyu
Github Pages(github.io):@臭咸鱼
知乎(zhihu.com):@臭咸鱼
博客园(cnblogs.com):@臭咸鱼
B站(bilibili.com):@绝版臭咸鱼
微信公众号:@臭咸鱼
转载请注明出处,欢迎讨论和交流!