1)UniversityRanking实验
作业要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
(1)代码部分
import requests
from bs4 import BeautifulSoup
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
r = requests.get(url = url,headers = headers)
r.encoding = 'utf-8'
page_text = r.text
soup = BeautifulSoup(page_text,"lxml")
all_list=[]
tr_list = soup.findAll("tr")
for tr in tr_list:
arr = []
td_list = tr.findAll("td")
if len(td_list)==0:
continue
for td in td_list:
arr.append(td.text)
all_list.append(arr)
print("排名 学校名称 省市 学校类型 总分")
for row in all_list:
row[0]=row[0].strip()
row[1]=row[1].strip()
row[2]=row[2].strip()
row[3]=row[3].strip()
row[4]=row[4].strip()
print(row[0],row[1],row[2],row[3],row[4])
自己后面看了xpath也写了一下,感觉xpath表达式的用法和select大致上一样,感觉就是稍微改了一下一些符号。
from lxml import etree
import requests
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
r = requests.get(url = url,headers = headers)
r.encoding = 'utf-8'
page_text = r.text
tree = etree.HTML(page_text)
print("排名 学校名称 省市 学校类型 总分")
tr_list = tree.xpath('//table[@class="rk-table"]/tbody/tr')
for tr in tr_list:
td_1 = tr.xpath('./td[1]//text()')[0].strip()
td_2 = tr.xpath('./td[2]//text()')[0].strip()
td_3 = tr.xpath('./td[3]//text()')[0].strip()
td_4 = tr.xpath('./td[4]//text()')[0].strip()
td_5 = tr.xpath('./td[5]//text()')[0].strip()
print(td_1,td_2,td_3,td_4,td_5)
运行结果
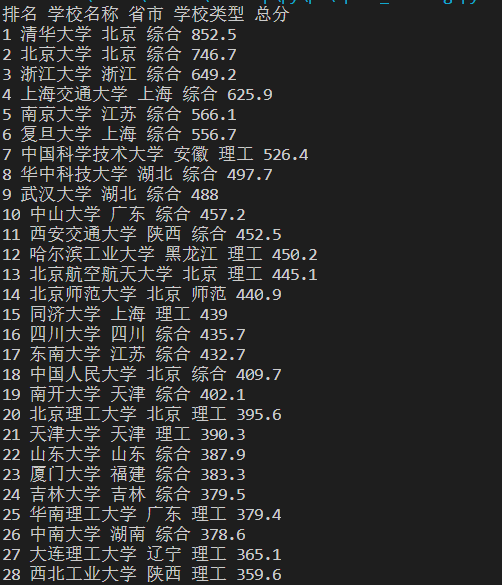
一共有567所高校
(2)心得体会
第一次上手的感觉还是有点难度,在定位标签的时候就花了不少时间,而且提取标签中我们所需要的文本中也夹带着'
',' ',花了不小功夫才解决这些问题。经过这一次实验,自己对爬虫的步骤有了大致的了解。
1、指定url
2、UA伪装
3、发起请求
4、获取响应数据并解析
5、持久化存储。
自己对resquests库的用法也有了了解,自己也会看一些抓包工具,昨天自己用xpath来解析感觉速度就快了很多。经过这次实验,算是小小的入门吧。
2)GoodsPrices实验
作业要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
(1)代码部分
from bs4 import BeautifulSoup
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
url = "https://search.jd.com/Search?keyword=书包&page=%d" #自定义自己要爬取的页数,这里page步长2实际上只有1个页面
r = requests.get(url = url,headers=headers)
r.encoding = 'utf-8'
text = r.text
soup = BeautifulSoup(text,"lxml")
count = 1
print("序号 价格 商品名称")
for j in range(1,10,2):
new_url = format(url,str(j)) #j要为字符串类型
tags1 = soup.select("div[class='p-price'] strong i") #定位2种标签
tags2 = soup.select("div[class='p-name p-name-type-2'] a em")
for i in range(len(tags1)):
print(count,tags1[i].text,tags2[i].text.replace("
","").replace("京东超市","").replace(" ",""))#去掉不必要的空格
count = count + 1
s=j//2+1
print("=========================第"+str(s)+"页商品打印完毕=========================")


(2)心得体会
这次爬取京东商品的实验我用的是select,感觉select还蛮好用的,正则的话感觉难度有点大,并且我没有加入刷新商品的模块,一个页面只能显示出一半的商品(30)个,并且前两天爬虫的时候好像一定要加头部了,不加头部就访问不了。这里page值为0,1时是第一页,2,3是第二页,以此类推,所以遍历的时候步长要取2。
感觉数据解析只要定位到标签的位置,剩下的就比较简单了。
3)JPGFileDownload实验
作业要求:爬取一个给定网页(http://xcb.fzu.edu.cn/html/2019ztjy)或者自选网页的所有JPG格式文件
(1)代码部分
import os
import requests
from bs4 import BeautifulSoup
import re
if not os.path.exists('./JpgFile'): #当文件夹不存在的时候,在当前目录下创建该文件夹
os.mkdir('./JpgFile')
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
url = 'http://xcb.fzu.edu.cn/'
r = requests.get(url = url,headers = headers).text
soup = BeautifulSoup(r,"lxml")
path_list = []
tags1 = soup.select("img[src$='jpg']")
for tag in tags1:
if tag["src"][0] =='/': #判断我们所获取的图片网址是不是完整的,不是的话要补成完成的地址
tag["src"] = 'http://xcb.fzu.edu.cn' + tag["src"]
path_list.append(tag["src"])
list2 = re.findall("/attach.*?jpg",r,re.I) #正则表达式匹配我们所需要的图片网址
for i in list2: #re.I忽略正则表达式的大小写,因为有个是大写的JPG
i = 'http://xcb.fzu.edu.cn'+i
path_list.append(i)
print(len(path_list))
for path in path_list:
jpg_data = requests.get(url=path,headers=headers).content
jpg_name = path.split('/')[-1] #获取图片名称
path_name = './JpgFile/'+jpg_name
with open(path_name,'wb') as fp:
fp.write(jpg_data)
print(jpg_name,"下载完毕!!!")


(2)心得体会
这次实验相较前两次难度会大一些,不过有了前两次实验的铺垫,这次实验做起来也比较得心应手。首先创建一个文件夹来保存所有的图片,用select来找出我们要的jpg文件的链接,这里要注意补全网址。我访问的网址是http://xcb.fzu.edu.cn/,这里有点坑,有5张图片是在一个文本中,并且有一张是大写的JPG,所以得用正则表达式来匹配到我们所需要的图片的地址,re.I忽略大小写,然后再补全网址。然后对每个图片地址发起url请求,这里获取二进制数据,然后给图片命名,依次写入文件夹。