作业①
1)要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
代码部分
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import urllib.request
import threading
import sqlite3
import os
import datetime
from selenium.webdriver.common.keys import Keys
import time
class MySpider:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
# # Initializing Chrome browser
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
# Initializing variables
self.threads = []
self.No = 0
self.imgNo = 0
self.page_num = 1 #爬取页面初始化
# Initializing database
try:
self.con = sqlite3.connect("phones.db")
self.cursor = self.con.cursor()
try:
# 如果有表就删除
self.cursor.execute("drop table phones")
except:
pass
try:
# 建立新的表
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print(err)
# Initializing images folder
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print(err)
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print(err);
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print(err)
def showDB(self):
try:
con = sqlite3.connect("phones.db")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东
", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东
", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
#设置爬取页数为5次
if(self.page_num<=4):
self.page_num +=1
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
结果展示

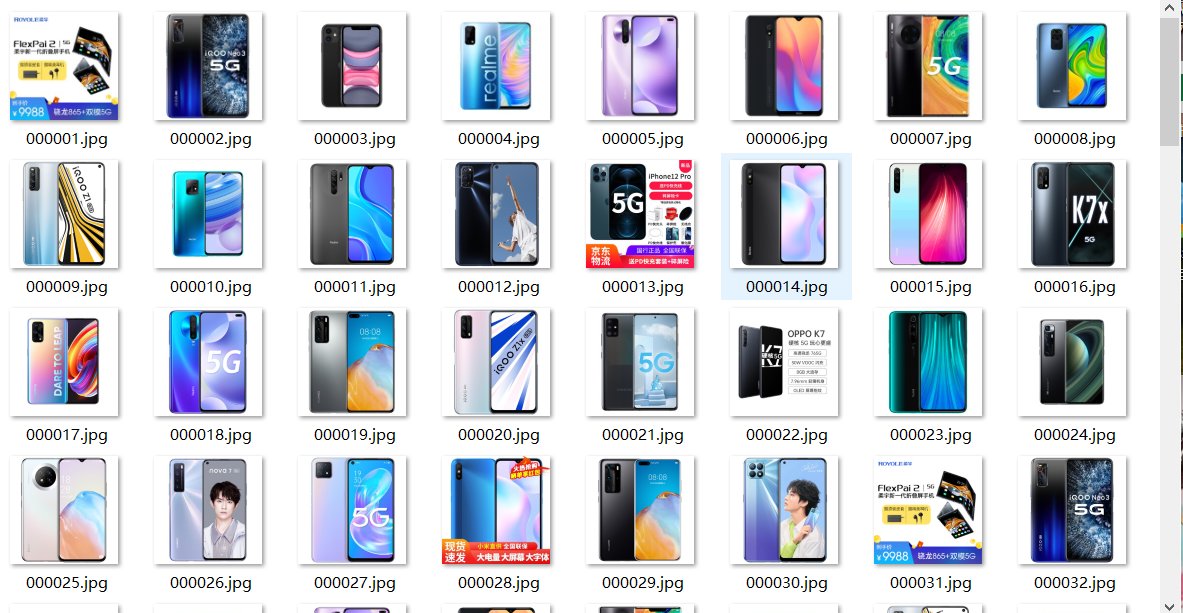
2)心得体会
第一题主要是复现老师的代码,花了不少时间才算是大致理解了老师的代码(老师不愧是老师)。有了第一题的基础,后面两题的实现算是大致都有了思路,通过第一题,我对selenium的运用更加了解了。
作业②
1)要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
代码部分
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import datetime
import time
from lxml import etree
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
count = 1
def startUp(self,url):
# # Initializing Chrome browser
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host = "127.0.0.1",port = 3306,user = "root",passwd = "********",db = "mydb",charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("delete from stock") #如果表已经存在就删掉
# self.cursor.execute("create table stock(id int primary key,"
# "stockNo varchar(20),"
# "name varchar(20),"
# "new_price varchar(20),"
# "up_rate varchar(20),"
# "up_num varchar(20),"
# "turnover varchar(20),"
# "turnover_num varchar(20),"
# "change_ varchar(20),"
# "high varchar(20),"
# "low varchar(20),"
# "today varchar(20),"
# "yestoday varchar(20))")
self.opened = True
self.page_num = 1
except Exception as err:
print(err)
self.opened = False
self.driver.get(url)
def closeUp(self):
try:
if(self.opened):
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
print("爬取完毕,closed")
except Exception as err:
print("关闭数据库失败",err)
def insertDB(self,number,id,stockNo,name,new_price,up_rate,up_num,turnover,turnover_num,change_,high,low,today,yestoday):
try:
self.cursor.execute("insert into stock(number,id,stockNo,name,new_price,up_rate,up_num,turnover,turnover_num,change_,high,low,today,yestoday) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)",
(str(self.count),id,stockNo,name,new_price,up_rate,up_num,turnover,turnover_num,change_,high,low,today,yestoday))
except Exception as err:
print("插入失败",err)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
tr_list = self.driver.find_elements_by_xpath("//*[@id='table_wrapper-table']/tbody/tr")
for tr in tr_list:
id = tr.find_element_by_xpath('./td[1]').text
stockNo = tr.find_element_by_xpath('./td[2]').text
name = tr.find_element_by_xpath('./td[3]').text
new_price = tr.find_element_by_xpath('./td[5]').text
up_rate = tr.find_element_by_xpath('./td[6]').text
up_num = tr.find_element_by_xpath('./td[7]').text
turnover = tr.find_element_by_xpath('./td[8]').text
turnover_num = tr.find_element_by_xpath('./td[9]').text
change_ = tr.find_element_by_xpath('./td[10]').text
high = tr.find_element_by_xpath('./td[11]').text
low = tr.find_element_by_xpath('./td[12]').text
today = tr.find_element_by_xpath('./td[13]').text
yestoday = tr.find_element_by_xpath('./td[14]').text
self.insertDB(str(self.count),id,stockNo,name,new_price,up_rate,up_num,turnover,turnover_num,change_,high,low,today,yestoday)
self.count += 1
try:
self.driver.find_element_by_xpath('//*[@id="main-table_paginate"]/a[@class="next paginate_button disabled"]')
except:
next_page = self.driver.find_element_by_xpath('//*[@id="main-table_paginate"]/a[@class="next paginate_button"]')
time.sleep(3)
next_page.click()
#time.sleep(5)
if(self.page_num<3):
self.page_num += 1
self.processSpider()
except Exception as err:
print(err)
myspider = MySpider()
data = {
"沪深A股":"gridlist.html#hs_a_board",
"上圳A股":"gridlist.html#sh_a_board",
"深圳A股":"gridlist.html#sz_a_board"
}
starttime = datetime.datetime.now()
for key in data.keys():
url = "http://quote.eastmoney.com/center/"
print("正在爬取"+key+"板块的股票")
url = url + data[key]
print("开始爬虫...")
myspider.startUp(url)
print("正在爬虫...")
myspider.processSpider()
myspider.closeUp()
endtime = datetime.datetime.now()
total_time = endtime - starttime
print("结束爬虫,"+"一共耗时"+str(total_time)+"秒")
print("一共耗时"+str(myspider.count-1)+"条数据");
结果展示

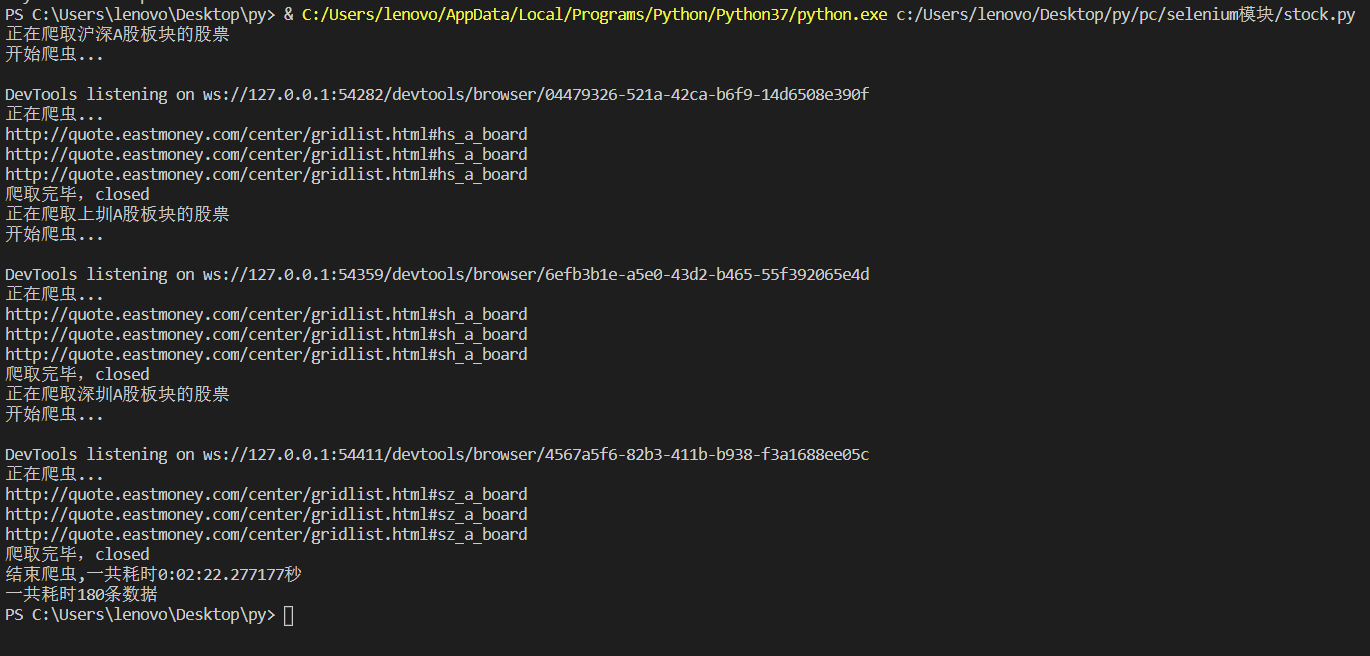

2)心得体会
第二题的话,首先有个疑问:不知道为啥我创建表的命令实现不了?所以只能最后在mysql中创建表格,后续的进展都比较顺利,就是要爬取的项有点多,给列取名取到头秃,还有一个踩到的坑就是在测试爬取情况的时候,没有添加关闭函数,导致爬取插入的数据没有被更新到数据库中,花费了不少时间才发现这个问题。

作业③
1)要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
代码部分
from time import daylight, sleep
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import pymysql
import datetime
import time
from selenium.webdriver.common.keys import Keys
from lxml import etree
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
count = 1
def startUp(self,url):
# # Initializing Chrome browser
chrome_options = Options()
# chrome_options.add_argument('--headless')
# chrome_options.add_argument('--disable-gpu')
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host = "127.0.0.1",port = 3306,user = "root",passwd = "********",db = "mydb",charset = "utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
#self.cursor.execute("delete from stock") #如果表已经存在就删掉
self.opened = True
self.page_num = 1
except Exception as err:
print("连接数据库失败")
self.opened = False
self.driver.get(url)
#这里的search框用id属性显示定位不到
#1.如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)
#2.找到它老爸后,再找下个层级就能定位到了
#3.要是它老爸的属性也不是很明显
time.sleep(2)
accession = self.driver.find_element_by_xpath('//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
# print(accession)
# time.sleep(3)
accession.click()
time.sleep(3)
#其它登入方式
other = self.driver.find_element_by_xpath('//div[@class="ux-login-set-scan-code_ft"]/span')
other.click()
time.sleep(5)
self.driver.switch_to.frame(self.driver.find_element_by_xpath("//iframe[starts-with(@id, 'x-URS-iframe')]"))
email = self.driver.find_element_by_xpath('//input[@name="email"]')
email.send_keys('2105114977@qq.com')
time.sleep(2)
pswd = self.driver.find_element_by_xpath('//input[@name="password"]')
pswd.send_keys('********')
time.sleep(2)
go = self.driver.find_element_by_xpath('//div[@class="f-cb loginbox"]/a')
go.click()
time.sleep(5)
search = self.driver.find_element_by_xpath('//div[@class="u-baseinputui"]/input[@type="text"]') #找到搜索的input框
time.sleep(3)
search.send_keys(key)
search.send_keys(Keys.ENTER)
def closeUp(self):
try:
if(self.opened):
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
print("爬取完毕,关闭数据库")
except Exception as err:
print("关闭数据库失败")
def insertDB(self,id,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief):
try:
self.cursor.execute("insert into mooc(id,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief) values (%s,%s,%s,%s,%s,%s,%s,%s)",
(str(self.count),Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief))
except Exception as err:
print("插入数据失败!",err)
def processSpider(self):
time.sleep(3)
print(self.driver.current_url)
div_list = self.driver.find_elements_by_xpath('//div[@class="m-course-list"]/div/div[@class="u-clist f-bgw f-cb f-pr j-href ga-click"]')
#print(len(div_list))
for div in div_list:
Mcourse = div.find_element_by_xpath('.//div[@class="t1 f-f0 f-cb first-row"]').text
Mcollege = div.find_element_by_xpath('.//a[@class="t21 f-fc9"]').text
Mteacher = div.find_element_by_xpath('.//a[@class="f-fc9"]').text
Mcount = div.find_element_by_xpath('.//span[@class="hot"]').text
#详情页,这里通过点击图片来实现
detail = div.find_element_by_xpath('.//div[@class="u-img f-fl"]')
detail.click()
time.sleep(2) #等待详情页面加载,准备爬取我们所需要的其它内容
windows = self.driver.window_handles #获取当前所有页面句柄
self.driver.switch_to.window(windows[1]) #切换到刚刚点击的新页面
teams = self.driver.find_elements_by_xpath('//div[@class="um-list-slider_con_item"]//h3[@class="f-fc3"]')
Mteam = ""
for team in teams:
Mteam = Mteam + team.text
if(team!=teams[-1]):
Mteam += " "
#print(Mteam) #测试团队爬取情况
Mprocess = self.driver.find_element_by_xpath('//div[@class="course-enroll-info_course-info_term-info"]//div[@class="course-enroll-info_course-info_term-info_term-time"]/span[2]').text
Mbrief = self.driver.find_element_by_xpath('//div[@class="course-heading-intro_intro"]').text
#print(Mprocess,Mbrief)
self.driver.close() #把详情页窗口关闭
self.driver.switch_to.window(windows[0]) #切换回最初的页面
#通过观察浏览器的行为,确实可以爬取到我们所需要的所有信息了,接下来只要把我们的数据存储到数据库即可
#print(self.count,Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief)
self.insertDB(str(self.count),Mcourse,Mcollege,Mteacher,Mteam,Mcount,Mprocess,Mbrief)
self.count += 1
#爬取完毕一个页面的数据了,这里就爬取2页的数据
#这题先找disable的话在第一页会先点击上一页
try:
next_button = self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]//a[@class="th-bk-main-gh"]')
#print(next_button)
next_button.click()
time.sleep(2)
if(self.page_num<2):
self.page_num += 1
self.processSpider()
except:
self.driver.find_element_by_xpath('//li[@class="ux-pager_btn ux-pager_btn__next"]//a[@class="th-bk-disable-gh"]') #当前页面是否是最后一页
key = "机器学习"
url = "https://www.icourse163.org"
myspider = MySpider()
start = datetime.datetime.now()
myspider.startUp(url)
myspider.processSpider()
myspider.closeUp()
end = datetime.datetime.now()
print("一共爬取了"+str(myspider.count-1)+"条数据,"+"一共花费了"+str(end-start)+"的时间")
结果展示
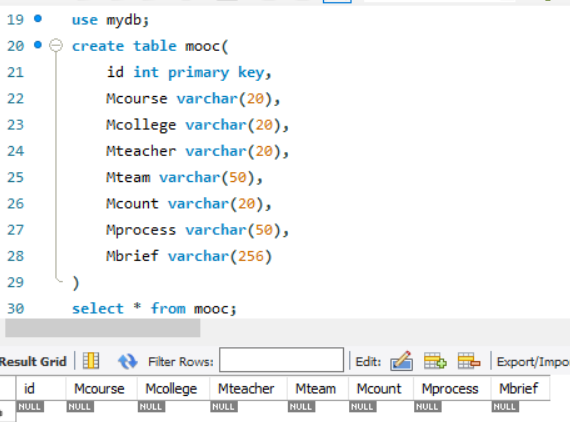


2)心得体会
这次作业的坑就有点多了。首先是模拟登入,在进行xpath解析时,有的元素定位不到,但是xpath其实是没有错的,这时候可以先定位到它的父节点,如果还不行,就再往上定位。然后模拟登入的账号密码框是嵌套在iframe中,所以要先进入iframe中再定位才能定位到账号框和密码框。第二个就是又踩了上一题的坑,明明在存储到数据库的过程中没有任何报错信息,发现又是没有写colse函数,没有commit。还有一个就是点击页面详情页,一开始我以为直接click之后就可以开始爬取了,但实际上此时仍处于最初的窗口,要通过来回切换窗口来进行数据捕获。经过三次实验,算是对selenium和数据库的存储方面的运用都了解更深了。
iframe的xpath定位参考博客
窗口切换的参考博客
